@@IDENTITY与NEWID
看到有些存储过程在返回最后一次插入的行的编号时使用@@IDENTITY,这种做法很危险,在并发量大时会造成数据不一致问题,因此请使用SCOPE_IDENTITY函数。详见联机文档的比较,另外还有一个IDENT_CURRENT。
简单的说,SCOPE_IDENTITY只在当前作用域有效,比如一个存储过程中。IDENT_CURRENT返回的是一个表中最后受影响的编号,而@@IDENTITY则是针对整个数据库有效的。
另外,如果表中非要使用GUID类型作为唯一标识字段,向大家推荐一个2005下的新的函数:NEWSEQUENTIALID。
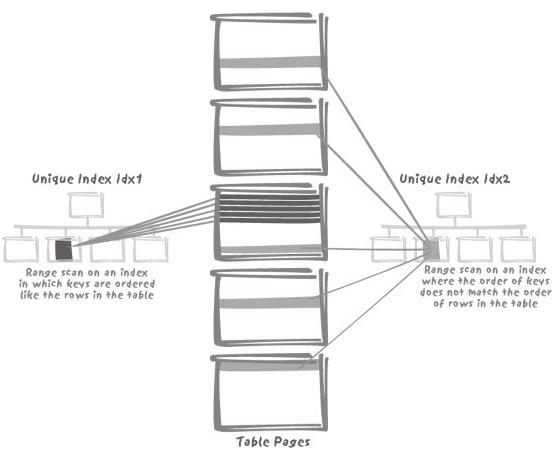
但是此函数的限制是只保证在本地机器产生唯一的GUID,但好处是每一GUID都是递增的。如果表中的聚焦索引是使用IDENTITY或NEWSEQUENTIALID,则在批量导入数据时,观察SQLSERVER:LATCHES或是SQLSERVER:WAIT STATISTICS中的相关计数器,会发现在开始大量修改表中的记录时,会出现很多latch锁。因此,会影响数据修改的速度。如果使用NEWID时,因为要根据GUID对数据维持一个逻辑顺序,会产生大量的分页操作,可以通过SQLSERVER:ACCESS METHODS里的Page Splits来观察。同时,如果这是你按照一个日期范围对表查询时,因为这时GUID会分散到很多页中,还会造成过多的I/O操作。像下面图中所示,过于密集和过于分散对查询的性能及数据修改的性能都会有影响。因此应该很谨慎的选择聚集索引。