RL实践2——RL环境gym搭建
RL回顾
首先先来回顾一下强化学习问题中,环境Env 和 代理Agent 分别承担的角色和作用。
RL组成要素是Agent、Env
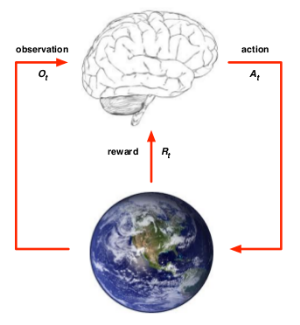
代理和环境 分别承担的作用
- Agent:
由Policy 和 RL_Algorithm构成,这种对RL_algorithm的算法理解比较宽泛- policy负责将observation映射为action
- RL_Algorithm负责优化policy,具有学习和搜索(规划)的能力
- Enviroment:
- 输入action
- 输出reward、state
- 内部还需要完成执行状态转移、判断是否终止等任务
- Agent的构成的另一种理解
组成要素:Policy、Value function、Model其中至少一个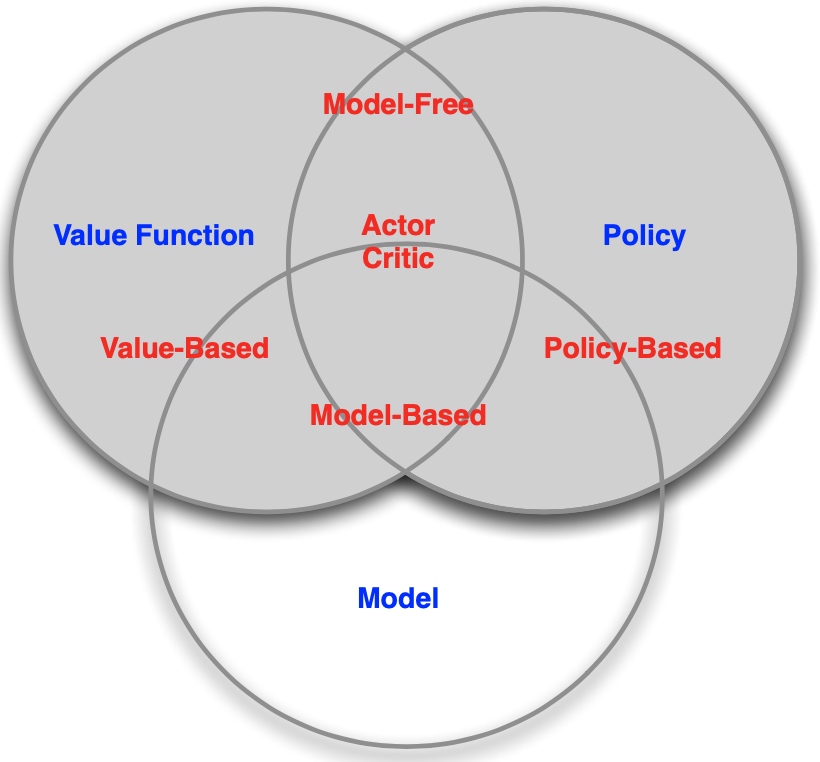
gym
gym介绍
gym是一个热门的学习库,搭建了简单的示例,其主要完成的功能,是完成了RL问题中Env的搭建。
- 对于强化学习算法的研究者,可以快速利用多种不同的环境验证迭代自己的算法有效性。
- 对于强化学习应用的研究者,我们可以效仿gym中的接口,搭建自己的环境。
gym定义
gym是一个class 的形式,完成了接口定义和调用
gym的核心代码写在core.py里,定义两个最基本的基类Env和Space
SpaceDiscrete类,定义离散状态、动作,初始化需要1个参数,维度nBox类,定义连续状态、动作,初始化需要2个array(size=维数n)
伪代码如下:
- 环境Env
class Environment():
self.states # 所有可能的状态集合
self.agent_cur_state # 记录个体当前的状态
self.observation_space # 个体的观测空间
self.action_space # 个体的行为空间
def reward(self) -> reward # 根据状态确定个体的即时奖励
def dynamics(self, action) -> None # 根据当前状态和个体的行为确定个体的新状态
def is_episode_end(self) -> Bool # 判断是否一个Episode结束
def obs_for_agent() -> obs # 环境把个体当前状态做一定变换,作为个体的观测
- 代理Agent
class Agent(env: Environment):
self.env = env # 个体依附于一个环境存在
self.obs # 个体的观测
self.reward # 个体获得的即时奖励
def performPolicy(self, obs) -> action # 个体执行一个策略产生一个行为
def performAction(self, action) -> None # 个体与环境交互,执行行为
action = self.performPolicy(self.obs)
self.env.dynamics(action)
def observe(self) -> next_obs, reward # 个体得到从环境反馈来的观测和奖励
self.obs = self.env.obs_for_agent()
self.reward = self.env.reward()
gym调用
gym的调用框架
env = gym.make('x')
observation = env.reset()
for i in range(time_steps):
env.render() # 调用第三方库刷动画写这里
action = policy(observation)
observation, reward, done, info = env.step(action)
if done:
……
break
env.close()
例子

例程是一个简单的策略,杆左斜车左移,右斜则右移。
import gym
import numpy as np
env = gym.make('CartPole-v0')
t_all = [ ]
action_bef = 0
for i_episode in range(5):
observation = env.reset()
for t in range(100):
env.render()
cp, cv, pa, pv = observation
if abs(pa)<= 0.1:
action = 1 -action_bef
elif pa >= 0:
action = 1
elif pa <= 0:
action = 0
observation, reward, done, info = env.step(action)
action_bef = action
if done:
# print("Episode finished after {} timesteps".format(t+1))
t_all.append(t)
break
if t ==99:
t_all.append(0)
env.close()
print(t_all)
print(np.mean(t_all))
gym的搭建
函数接口
一个完整的gym环境包括以下函数:
- class Cartpoleenv(gym.env)
def __ init __(self):类构建def reset(self):初始化def seed(self, seed = None):随机初始条件种子return [seed]def step(self, action): 单步仿真observation, reward, done, infodef render(self, mode='human'):图像引擎调用绘制窗口return self.viewer.render()def close():关闭窗口
功能函数
参数限位
vel = np.clip(vel, vel_min, vel_max)action输入校验
self.action_space.contains(action)action和observation空间定义
例子:
Discrete: 0,1,2三个离散值
low = np.array([min_0,min_1],dtype=np.float32)
high = np.array([max_0,max_1],dtype=np.float32)
self.action_space = spaces.Discrete(3)
self.observation_space = spaces.Box(
self.low, self.high, dtype=np.float32)
agent 的构建
agent与环境进行交互,输入是env的输出(observation),输出是env的输入(action)
class Agent():
def __ init__(self,action_space):
self.action_space = action_space
def act(self, observation, reward, done):
return action
agent和env交互逻辑如下:
nb_episodes = xx
nb_steps = xx
reward = 0
done = False
for i in range(nb_episodes):
ob = env.reset()
sum_reward = 0
for j in range(nb_steps):
action = agent.act(ob, reward, done)
ob, reward, done, _ = env.step(action)
sum_reward += reward
if done:
break
添加自己写的环境到gym,方便调用
设置过程
- 打开gym.envs目录:
/usr/local/lib/python3.7/site-packages/gym/envs - 将自己编写的myenv.py拷贝至一个
custom目录 envs/custom下__init__.py添加from gym.envs.custom.myenv import MyEnv,将子文件夹的.pyimport到上层目录- env下
__init__.py添加
register(
id='myenv-v0',
entry_point='gym.envs.custom:MyEnv,
max_episode_steps=999, #限制了最大终止仿真步数
)
授权gym的方法可以调用myenv.py中的MyEnvclass
- 注意:
__init__.py里的register方法中env_name版本号-v0不能省略- 调用的时候,也要带上环境相应的版本号
调用方法
env_name = 'myenv-v0'
env = gym.make('env_name')
env.reset() # 初始化环境
env.render() # 绘制环境,if necessary
env.step() # 单步仿真
env.close() # 关闭环境,一般涉及图像绘制的任务,此步为必须
欢迎关注微信公众号“探物及理”

