Base64隐写
0x00: 前言
Base64编码的作用:
- 将一些特殊的字符转换成常见的字符。特殊的字符可能是不可见字符或者是大于ascii码127的,将其变成常见的字符(在base64中为a~z A~Z 0~9 + /)。
- Base64特别适合在某些网络协议下快速传输。
在学习Base64隐写之前,得先熟悉Base64编码与解码的过程。
0x01: Base64的编码过程
Base64编码后的字符为”a~z A~Z 0~9 + /“共计64个,每个需要6个比特位进行存储。原本,ASCII编码字符每个字符占8个比特位。Base64编码则是把原来每单位8个比特位的字符序列划分成每单位6个比特位,然后按单位转换成上述中的64个字符。
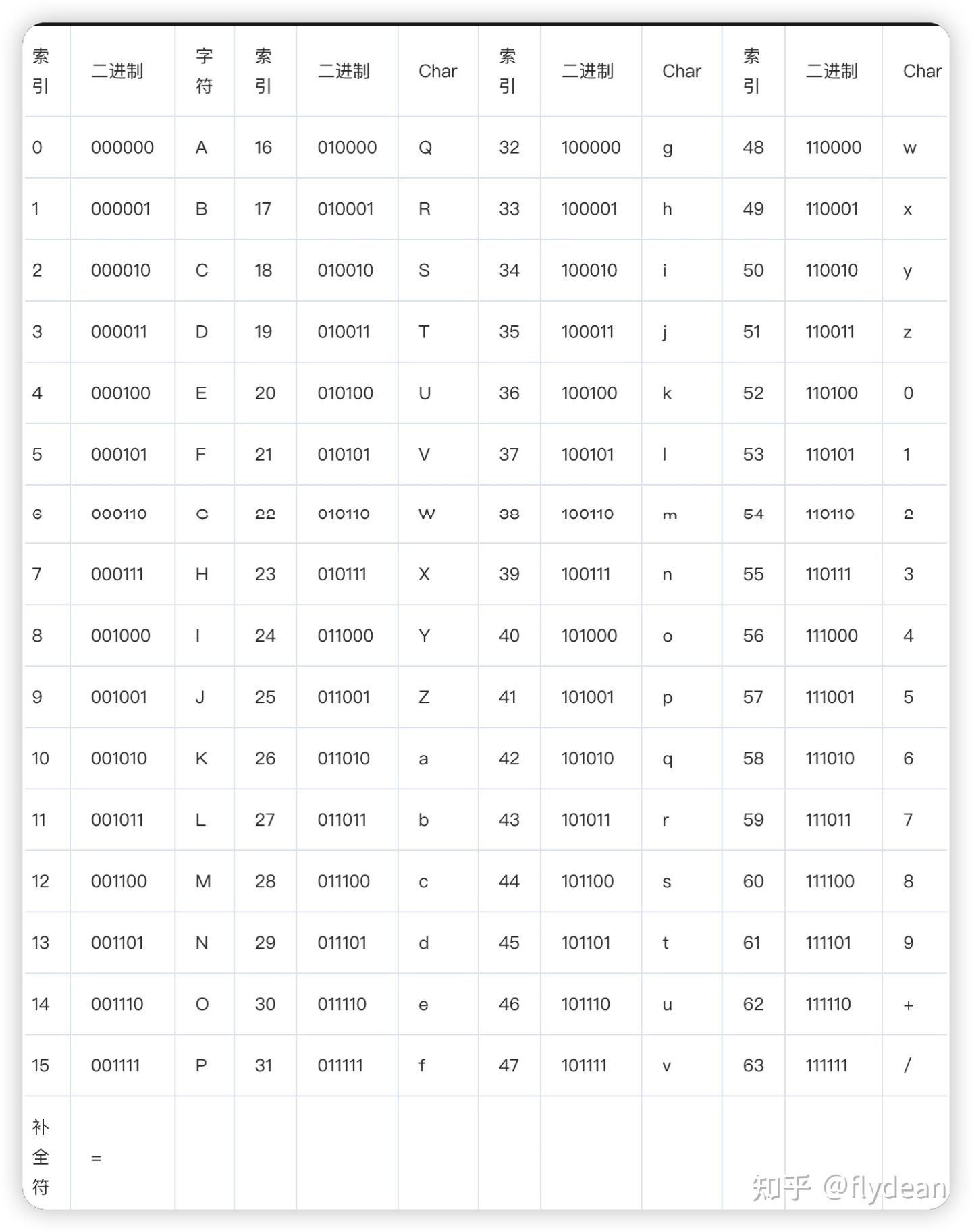
Base64编码表
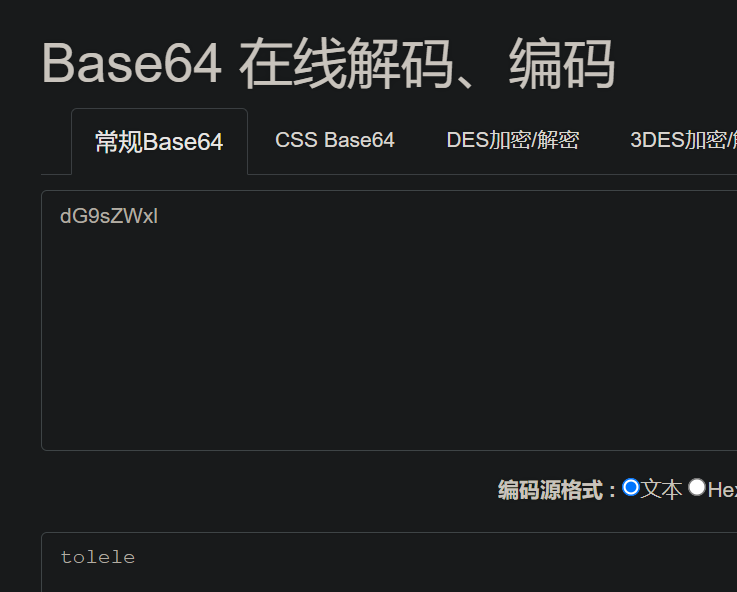
举个栗子~:将字符串"tolele"进行Base64编码。
- 根据ASCII编码进行转换:tolele <==> 01110100 01101111 01101100 01100101 01101100 01100101
- 重新按6bit进行划分:011101 000110 111101 101100 011001 010110 110001 100101
- 根据Base64编码表进行转码:dG9sZWxl
检验一下是没问题的:
通过这种方式编码,当字符数为3的倍数时才会刚好可以转换成若干个Base64编码字符。那当字符数不为3的倍数时,该怎么办呢?解决方法就是往后面以8bit为单位填充0。
这时,有两种情况:
- 字符数为3n+1:此情况最后会多出2个比特位,我们可以填充2个单位的0(即16个比特位的0),这时会有多余的18个比特位。前6个比特位按表格进行转码,其余的每6个bit位转换成'='。
- 字符数为3n+2:此情况会多出4个比特位,填充1个单位的0,这样就多余12个比特位,为6的整数倍。后续和1中类似。
图像总是比话语更能说明内容:
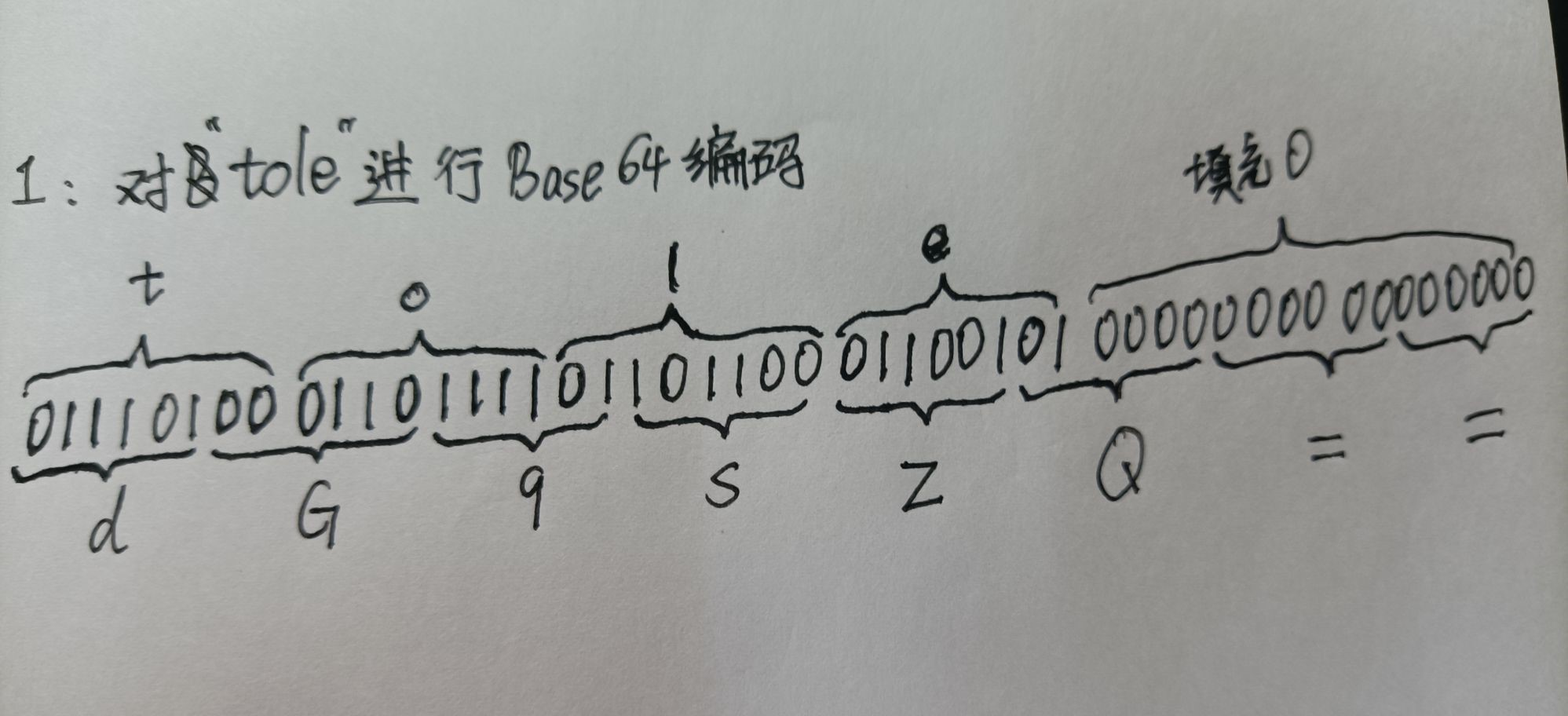
检验一下:
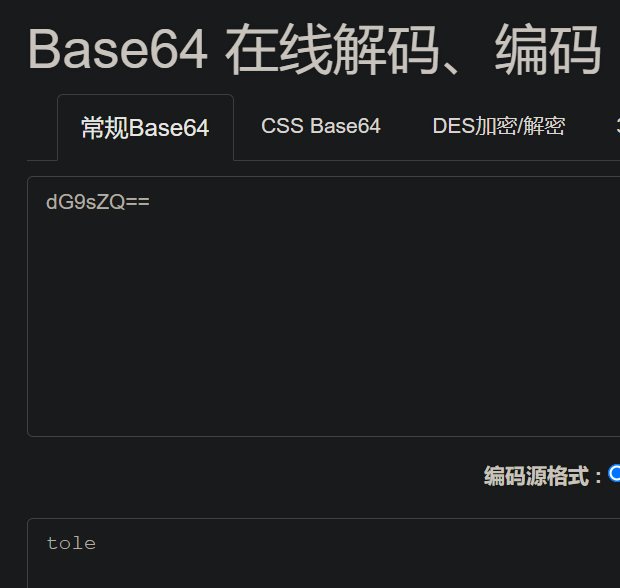
0x02: Base64的解码过程:
很显然,解码过程就是编码的逆过程。
拿上面"tole"的Base64编码"dG9sZQ=="进行举例:
- 先把填充的'='去掉:dG9sZQ
- 根据Base64编码表进行转码:dG9sZQ <==> 011101 000110 111101 101100 011001 010000
- 从前往后,以每8个比特位为单位进行ASCII转换成字符。最后面会有4个'0'多余,直接去掉就行。
0x03: Base64隐写原理:
可以留意一下解码过程中的第三步,会将多余的比特位去掉(因为凑不到8位)。那么,这说明了:这多余的比特位即使我们随意的改变值也不会影响解码后的结果,因为它会被丢弃掉。
测试一下:还是上面的例子,最后是Q,为010000。后面的4个0在解码时会被丢弃掉的,那我们使其变成010101,变成了V。解码后的结果会改变吗?
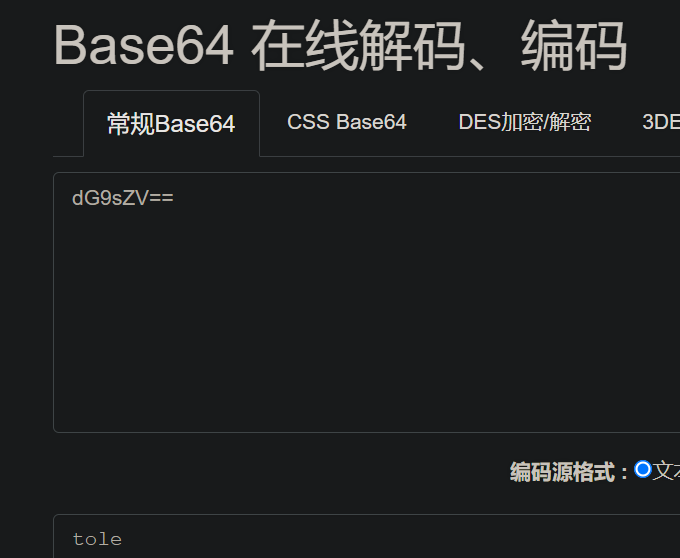
可见,这个改变并不会对解码结果造成影响。
这样,为了隐写某些数据,我们就可以将数据写入这里。但每个Base64编码最多多余4个比特位,为了隐藏较大的数据,我们常常需要多个比特位。提取时,我们可以将每个多余的比特位截取出来,按一定的顺序组合,从而得到我们的隐藏数据。
0x04: 例题实践
Buuctf的base64隐写:
https://buuoj.cn/challenges#[ACTF%E6%96%B0%E7%94%9F%E8%B5%9B2020]base64%E9%9A%90%E5%86%99
打开关键的txt文件一看,大量的base64编码,base64隐写跑不了了:

这里直接用大佬的脚本了,python2执行是没问题的,至于python3的话……
# -*- coding: cp936 -*-
b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('1.txt', 'rb') as f:
bin_str = ''
for line in f.readlines():
stegb64 = ''.join(line.split())
rowb64 = ''.join(stegb64.decode('base64').encode('base64').split())
offset = abs(b64chars.index(stegb64.replace('=','')[-1])-b64chars.index(rowb64.replace('=','')[-1]))
equalnum = stegb64.count('=') #no equalnum no offset
if equalnum:
bin_str += bin(offset)[2:].zfill(equalnum * 2)
print ''.join([chr(int(bin_str[i:i + 8], 2)) for i in xrange(0, len(bin_str), 8)]) #8 位一组
0x05: 感慨
“您这flag挺能藏的呀~”
tolele
2022-05-14

 浙公网安备 33010602011771号
浙公网安备 33010602011771号