网络爬虫:网页解析库总结
简介
XPath:是一门在XML文档中查找信息的语言。XPath可用来在XML文档中对元素和属性进行遍历。lxml是Python语言中处理XML和HTML的功能最丰富、最易于使用的库。lxml库对XPath提供了完美支持。
Pyquery:允许您对xml文档进行jquery查询。API尽可能类似于jquery。pyquery使用lxml进行快速xml和html操作。
Parsel:是一个BSD授权的Python库,可以使用XPath和CSS选择器(可选地与正则表达式结合)从HTML和XML中提取和删除数据。
Beautiful Soup:是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。
使用总结

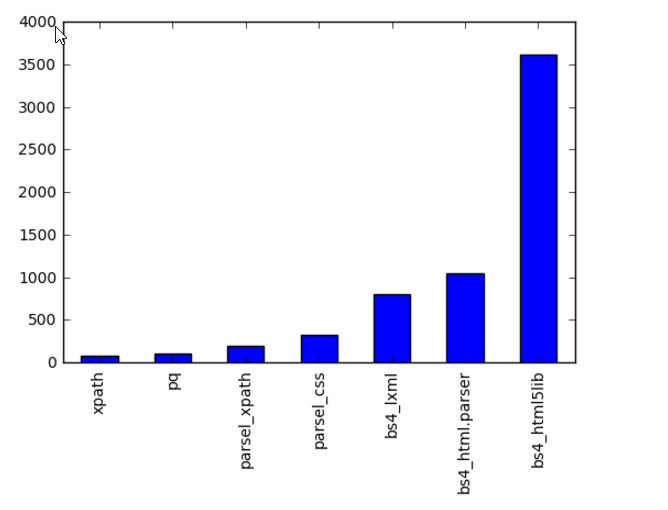
效率对比

 浙公网安备 33010602011771号
浙公网安备 33010602011771号