链表算法经典十题总结
前言
由于前面写了一些数据结构的相关的文章,但是都是偏基本的数据结构知识,并没有实际的算法题加以实践,故整理十道题目,都是比较常见的链表类的算法题,也参考了优秀的博客。
预备的数据结构知识点:
数据结构绪论
循序渐进学习栈和队列
循序渐进学习数据结构之线性表
循序渐进学习时间复杂度
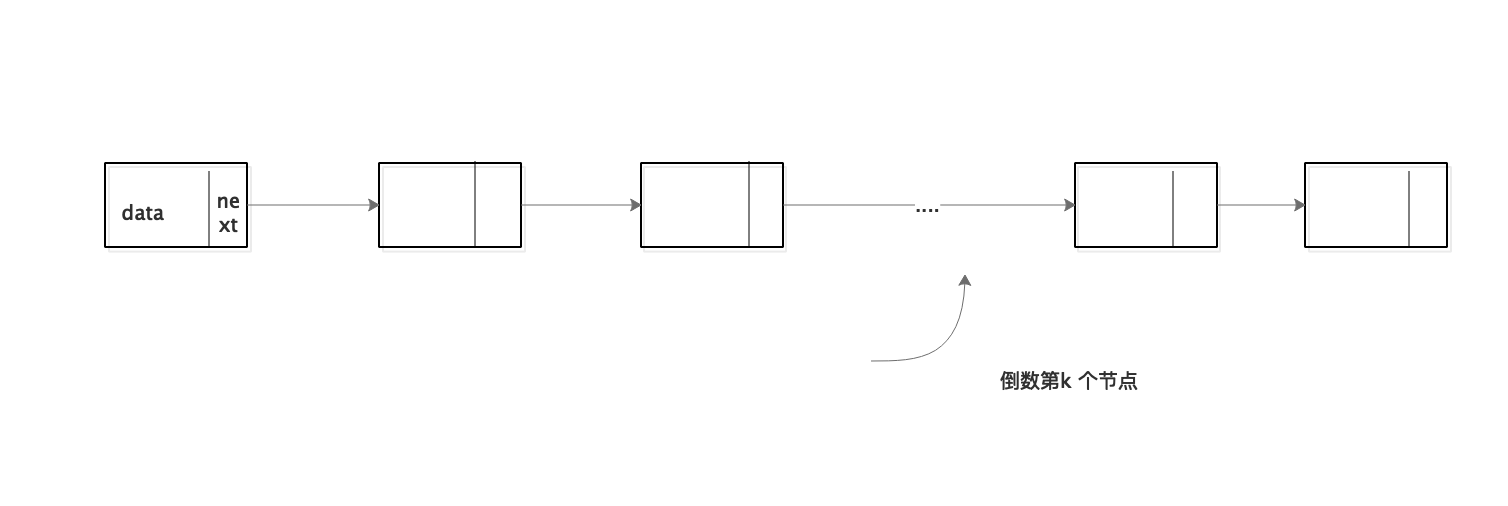
1.链表的倒数第K个结点
问题描述:
输入一个链表,输出该链表中倒数第k个结点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾结点是倒数第1个结点。例如一个链表有6个结点,从头结点开始它们的值依次是1、2、3、4、5、6。这个链表的倒数第3个结点是值为4的结点,需要保证时间复杂度。
算法思路:
设置两个指针p1,p2,从头到尾开始出发,一个指针先出发k个节点,然后第二个指针再进行出发,当第一个指针到达链表的节点的时候,则第二个指针表示的位置就是链表的倒数第k个节点的位置。

代码如下:
//倒数第k个结点
ListNode findKth(ListNode head,int k){
ListNode cur=head;
ListNode now=head;
int i=0;
while(cur!=null&i++<k){
cur=cur->next;
}
while(cur!=null){
now=now->next;
cur=cur->next;
}
}
总结:当我们用一个指针遍历链表不能解决问题的时候,可以尝试用两个指针来遍历链表。可以让其中一个指针遍历的速度快一些(比如一次在链表上走两步),或者让它先在链表上走若干步。
2.从尾到头打印链表(递归和非递归)
问题描述:
输入一个单链表链表,从尾到头打印链表每个节点的值。输入描述:输入为链表的表头;输出描述:输出为需要打印的“新链表”的表头。
算法思路:
首先我们想到从尾到头打印出来,由于单链表的查询只能从头到尾,所以可以想出栈的特性,先进后出。所以非递归可以把链表的点全部放入一个栈当中,然后依次取出栈顶的位置即可。
代码如下:
//非递归
void PrintReversing(ListNode * head){
//利用一个栈
Stack stack;
ListNode *node=head->next;
//将链表的结点压入
while(node!=null){
stack.push(node);
node=node->next;
}
ListNode *popNode;
while(stack.isEmpty()){
//获得最上面的元素
popNode=stack.top();
//打印
printf("%d\t",popNode->value);
//弹出元素
stack.pop();
}
/递归
void printRevese(ListNode *head){
if(head!=null){
if(head->next!=null){
printRevese(head->next);
}
print("%d\t",head->value);
}
}
非递归的描述当中,经常会用栈或者队列这些数据结构来改写一些递归的算法。其实递归的算法的时间复杂度是递归树的高度,所以递归的层数越高,时间复杂度也就会越高的。
3.如何判断一个链表有环
问题描述:
有一个单向链表,链表当中有可能出现“环”,如何用程序判断出这个链表是有环链表?
不允许修改链表结构。时间复杂度O(n),空间复杂度O(1)。
算法思路:
方法一、穷举遍历
首先从头节点开始,依次遍历单链表的每一个节点。每遍历到一个新节点,就从头节点重新遍历新节点之前的所有节点,用新节点ID和此节点之前所有节点ID依次作比较。如果发现新节点之前的所有节点当中存在相同节点ID,则说明该节点被遍历过两次,链表有环;如果之前的所有节点当中不存在相同的节点,就继续遍历下一个新节点,继续重复刚才的操作。
假设从链表头节点到入环点的距离是D,链表的环长是S。那么算法的时间复杂度是0+1+2+3+….+(D+S-1) = (D+S-1)(D+S)/2 , 可以简单地理解成 O(NN)。而此算法没有创建额外存储空间,空间复杂度可以简单地理解成为O(1)。
这种方法是暴力破解的方式,时间复杂度太高。
方法二、快慢指针
首先创建两个指针1和2,同时指向这个链表的头节点。然后开始一个大循环,在循环体中,让指针1每次向下移动一个节点,让指针2每次向下移动两个节点,然后比较两个指针指向的节点是否相同。如果相同,则判断出链表有环,如果不同,则继续下一次循环。
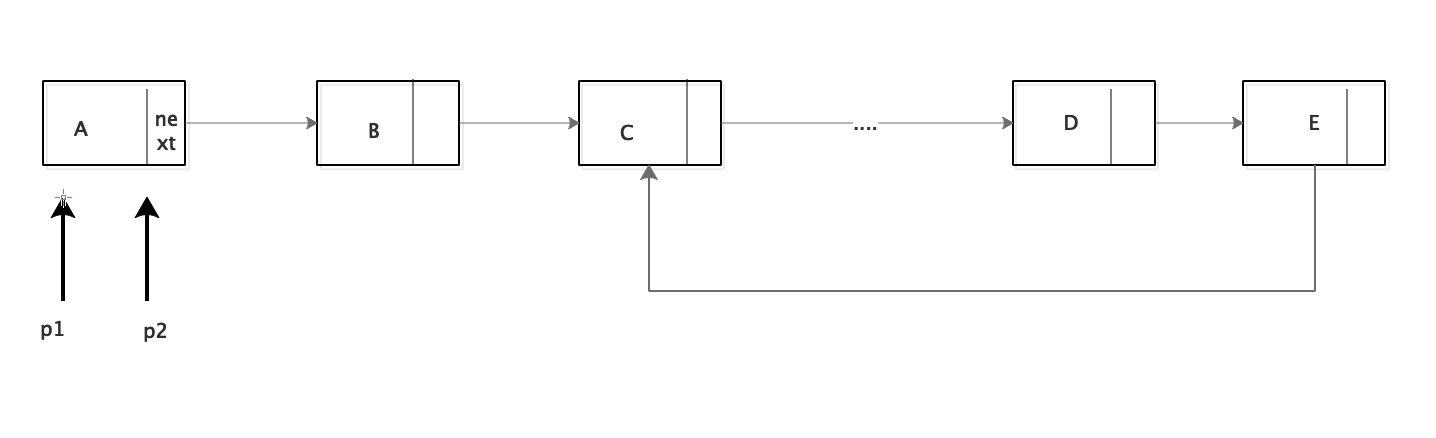
说明 :在循环的环里面,跑的快的指针一定会反复遇到跑的慢的指针 ,比如:在一个环形跑道上,两个运动员在同一地点起跑,一个运动员速度快,一个运动员速度慢。当两人跑了一段时间,速度快的运动员必然会从速度慢的运动员身后再次追上并超过,原因很简单,因为跑道是环形的。
代码如下:
/**
* 判断单链表是否存在环
* @param head
* @return
*/
public static <T> boolean isLoopList(ListNode<T> head){
ListNode<T> slowPointer, fastPointer;
//使用快慢指针,慢指针每次向前一步,快指针每次两步
slowPointer = fastPointer = head;
while(fastPointer != null && fastPointer.next != null){
slowPointer = slowPointer.next;
fastPointer = fastPointer.next.next;
//两指针相遇则有环
if(slowPointer == fastPointer){
return true;
}
}
return false;
}
4.链表中环的大小
问题描述
有一个单向链表,链表当中有可能出现“环”,那么如何知道链表中环的长度呢?
算法思路
由[3.如何判断一个链表有环](# 3.如何判断一个链表有环)可以知道,快慢指针可以找到链表是否有环存在,如果两个指针第一次相遇后,第二次相遇是什么时候呢?第二次相遇是不是可以认为快的指针比慢的指针多跑了一个环的长度。所以找到第二次相遇的时候就找到了环的大小。
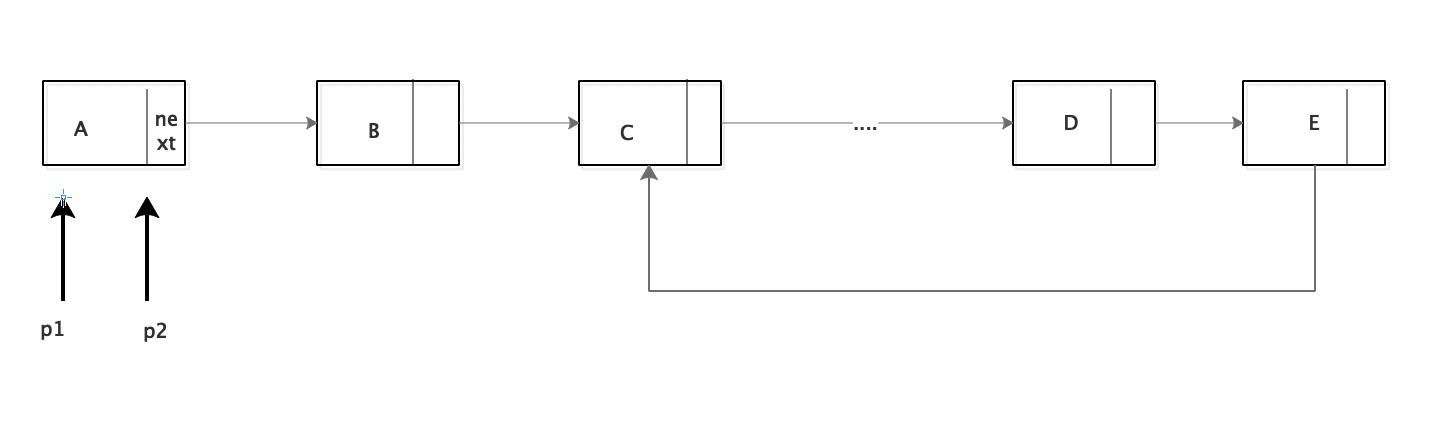
代码如下
//求环中相遇结点
public Node cycleNode(Node head){
//链表为空则返回null
if(head == null)
return null;
Node first = head;
Node second = head;
while(first != null && first.next != null){
first = first.next.next;
second = second.next;
//两指针相遇,则返回相遇的结点
if(first == second)
return first;
}
//链表无环,则返回null
return null;
}
public int getCycleLength(Node head){
Node node = cycleNode(head);
//node为空则代表链表无环
if(node == null)
return 0;
int length=1;
Node current = node.next;
//再次相遇则循环结束
while(current != node){
length++;
current = current.next;
}
return length;
}
5.链表中环的入口结点
问题描述
给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null。
算法思路
如果链表存在环,那么计算出环的长度n,然后准备两个指针pSlow,pFast,pFast先走n步,然后pSlow和pFase一块走,当两者相遇时,即为环的入口处;所以解决三个问题:如何判断一个链表有环;如何判断链表中环的大小;链表中环的入口结点。实际上最后的判断就如同链表的倒数第k个节点。
代码如下
public class Solution {
public ListNode EntryNodeOfLoop(ListNode pHead)
{
if(pHead.next == null || pHead.next.next == null)
return null;
ListNode slow = pHead.next;
ListNode fast = pHead.next.next;
while(fast != null){
if(fast == slow){
fast = pHead;
while(fast != slow){
fast = fast.next;
slow = slow.next;
}
return fast;
}
slow = slow.next;
fast = fast.next.next;
}
return null;
}
}
以上5题的套路其实都非常类似,第5题可以说是前面几道题的一个汇总题目吧,链表类的题利用快慢指针,两个指针确实挺多的,如下面题目7
6.单链表在时间复杂度为O(1)删除链表结点
问题描述
给定单链表的头指针和一个结点指针,定一个函数在时间复杂度为O(1)删除链表结点
算法思路
根据了解的条件,如果只有一个单链表的头指针,链表的删除操作其实正常的是O(n)的时间复杂度。因为首先想到的是从头开始顺序遍历单链表,然后找到节点,再进行删除。但是这样的方式达到的时间复杂度并不是O(1);实际上纯粹的删除节点操作,链表的删除操作是O(1)。前提是需要找到删除指定节点的前一个结点就可以。
那么是不是必须找到删除指定节点的前一个结点呢?如果我们删除的节点是A,那么我们把A下一个节点B和A的data进行交换,然后我们删除节点B,是不是也可以达到同样的效果。
答案是肯定的。
既然不能在O(1)得到删除节点的前一个元素,但我们可以轻松得到后一个元素,这样,我们何不把后一个元素赋值给待删除节点,这样也就相当于是删除了当前元素。可见,该方法可行,但如果待删除节点为最后一个节点,则不能按照以上思路,没有办法,只能按照常规方法遍历,时间复杂度为O(n),是不是不符合题目要求呢?可能很多人在这就会怀疑自己的思考,从而放弃这种思路,最后可能放弃这道题,这就是这道面试题有意思的地方,虽看简单,但是考察了大家的分析判断能力,是否拥有强大的心理,充分自信。其实我们分析一下,仍然是满足题目要求的,如果删除节点为前面的n-1个节点,则时间复杂度为O(1),只有删除节点为最后一个时,时间复杂度才为O(n),所以平均的时间复杂度为:(O(1) * (n-1) + O(n))/n = O(1);仍然为O(1).
代码如下
/* Delete a node in a list with O(1)
* input: pListHead - the head of list
* pToBeDeleted - the node to be deleted
*/
struct ListNode
{
int m_nKey;
ListNode* m_pNext;
};
void DeleteNode(ListNode *pListHead, ListNode *pToBeDeleted)
{
if (!pListHead || !pToBeDeleted)
return;
if (pToBeDeleted->m_pNext != NULL) {
ListNode *pNext = pToBeDeleted->m_pNext;
pToBeDeleted->m_pNext = pNext->m_pNext;
pToBeDeleted->m_nKey = pNext->m_nKey;
delete pNext;
pNext = NULL;
}
else { //待删除节点为尾节点
ListNode *pTemp = pListHead;
while(pTemp->m_pNext != pToBeDeleted)
pTemp = pTemp->m_pNext;
pTemp->m_pNext = NULL;
delete pToBeDeleted;
pToBeDeleted = NULL;
}
}
题目的考虑的点,也很特别
7.两个链表的第一个公共结点
问题描述
输入两个单链表,找出他们的第一个公共结点。
算法思路
我们了解到单链表的指针是指向下一个节点的,如果两个单链表的第一个公共节点就说明他们后面的节点都是在一起的。类似下图,由于两个链表的长度可能是不一致的,所以首先比较两个链表的长度m,n,然后用两个指针分别指向两个链表的头节点,让较长的链表的指针先走|m-n|个长度,如果他们下面的节点是一样的,就说明出现了第一个公共节点。
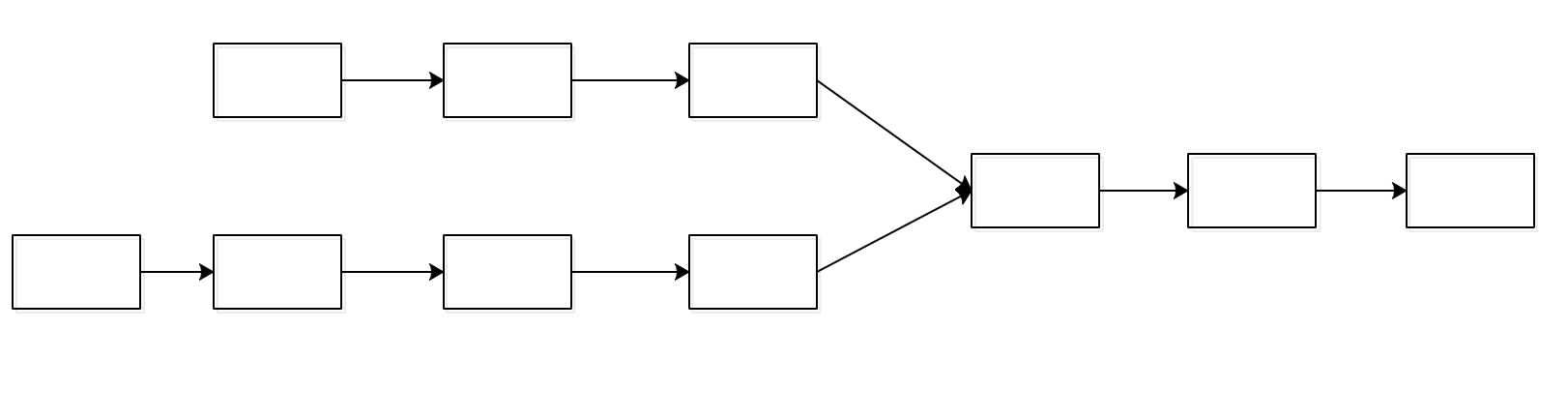
代码如下
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
if (pHead1 == null||pHead2 == null) {
return null;
}
int count1 = 0;
ListNode p1 = pHead1;
while (p1!=null){
p1 = p1.next;
count1++;
}
int count2 = 0;
ListNode p2 = pHead2;
while (p2!=null){
p2 = p2.next;
count2++;
}
int flag = count1 - count2;
if (flag > 0){
while (flag>0){
pHead1 = pHead1.next;
flag --;
}
while (pHead1!=pHead2){
pHead1 = pHead1.next;
pHead2 = pHead2.next;
}
return pHead1;
}
if (flag <= 0){
while (flag<0){
pHead2 = pHead2.next;
flag ++;
}
while (pHead1 != pHead2){
pHead2 = pHead2.next;
pHead1 = pHead1.next;
}
return pHead1;
}
return null;
}
}
8.合并两个排序的链表
问题描述
输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
算法思路
这道题比较简单,合并两个有序的链表,就可以设置两个指针进行操作即可,同时比较大小,但是也需要注意两个链表的长度进行比较。
代码如下
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode Merge(ListNode list1,ListNode list2) {
ListNode head = new ListNode(-1);
ListNode cur = head;
while (list1 != null && list2 != null) {
if (list1.val <= list2.val) {
cur.next = list1;
list1 = list1.next;
} else {
cur.next = list2;
list2 = list2.next;
}
cur = cur.next;
}
if (list1 != null)
cur.next = list1;
if (list2 != null)
cur.next = list2;
return head.next;
}
}
9.复杂的链表复制
问题描述
题目:请实现函数ComplexListNode Clone(ComplexListNode head),复制一个复杂链表。在复杂链表中,每个结点除了有一个Next指针指向下一个结点外,还有一个Sibling指向链表中的任意结点或者NULL。
下图是一个含有5个结点的复杂链表。图中实线箭头表示m_pNext指针,虚线箭头表示m_pSibling指针。为简单起见,指向NULL的指针没有画出。
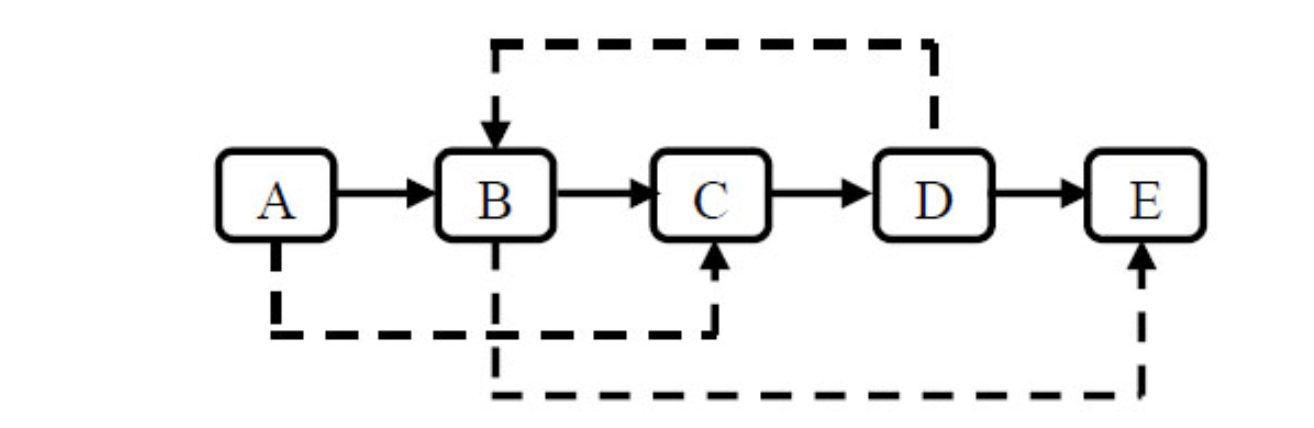
算法思路
第一种:O(n2)的普通解法
第一步是复制原始链表上的每一个结点,并用Next节点链接起来;
第二步是设置每个结点的Sibling节点指针。
第二种 :借助辅助空间的O(n)解法
第一步仍然是复制原始链表上的每个结点N创建N',然后把这些创建出来的结点用Next链接起来。同时我们把<N,N'>的配对信息放到一个哈希表中。
第二步还是设置复制链表上每个结点的m_pSibling。由于有了哈希表,我们可以用O(1)的时间根据S找到S'。
第三种:不借助辅助空间的O(n)解法
第一步仍然是根据原始链表的每个结点N创建对应的N'。(把N'链接在N的后面)
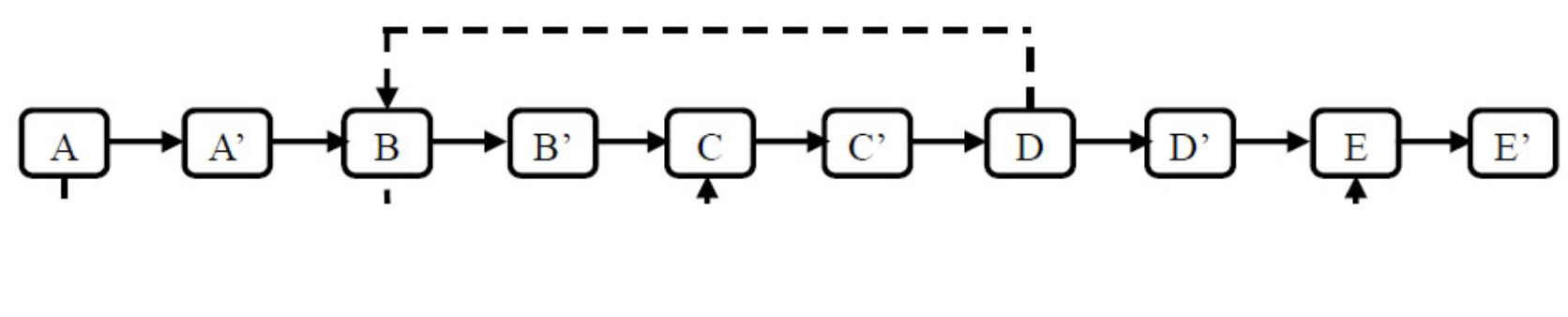
第二步设置复制出来的结点的Sibling。(把N'的Sibling指向N的Sibling)
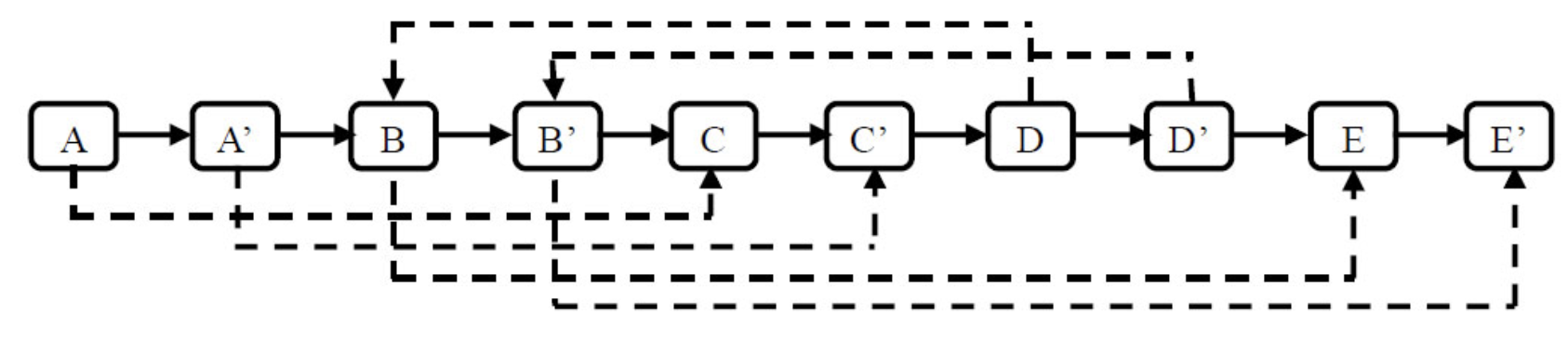
第三步把这个长链表拆分成两个链表:把奇数位置的结点用Next链接起来就是原始链表,偶数数值的则是复制链表。

代码如下
public class Solution {
public RandomListNode Clone(RandomListNode pHead) {
if(pHead == null) {
return null;
}
RandomListNode currentNode = pHead;
//1、复制每个结点,如复制结点A得到A1,将结点A1插到结点A后面;
while(currentNode != null){
RandomListNode cloneNode = new RandomListNode(currentNode.label);
RandomListNode nextNode = currentNode.next;
currentNode.next = cloneNode;
cloneNode.next = nextNode;
currentNode = nextNode;
}
currentNode = pHead;
//2、重新遍历链表,复制老结点的随机指针给新结点,如A1.random = A.random.next;
while(currentNode != null) {
currentNode.next.random = currentNode.random==null?null:currentNode.random.next;
currentNode = currentNode.next.next;
}
//3、拆分链表,将链表拆分为原链表和复制后的链表
currentNode = pHead;
RandomListNode pCloneHead = pHead.next;
while(currentNode != null) {
RandomListNode cloneNode = currentNode.next;
currentNode.next = cloneNode.next;
cloneNode.next = cloneNode.next==null?null:cloneNode.next.next;
currentNode = currentNode.next;
}
return pCloneHead;
}
}
10.反转链表
问题描述
题目:定义一个函数,输入一个链表的头结点,反转该链表并输出反转后链表的头结点。如图:
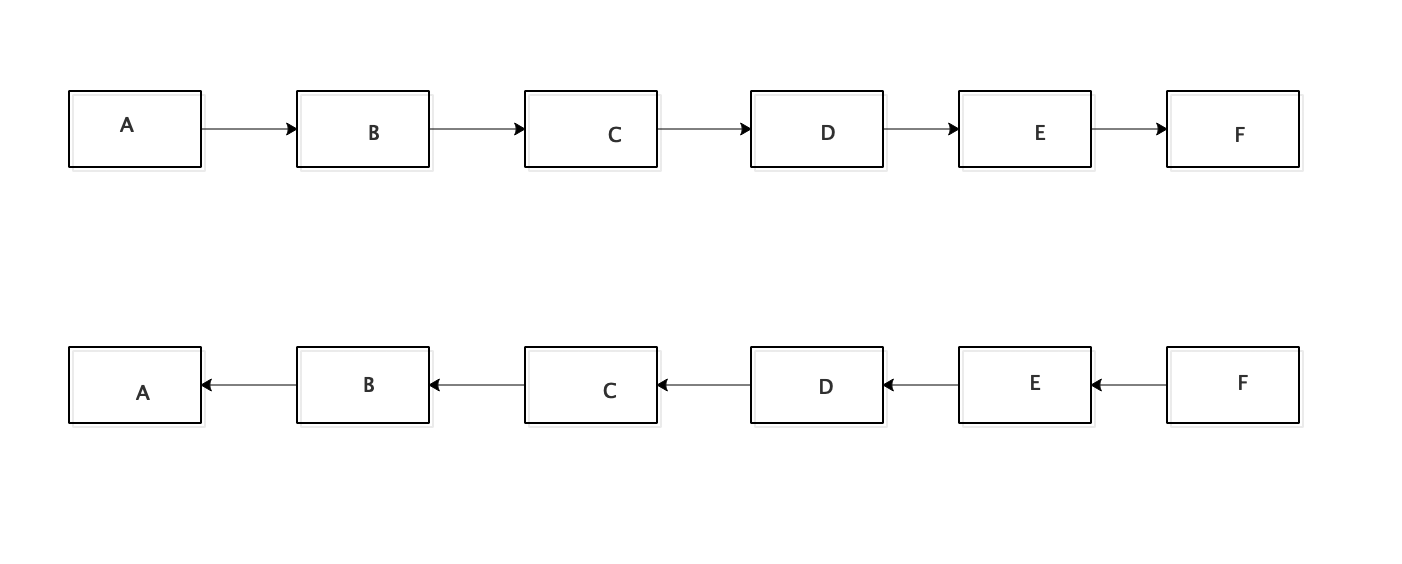
算法思路
为了正确地反转一个链表,需要调整链表中指针的方向。为了将复杂的过程说清楚,这里借助于下面的这张图片。
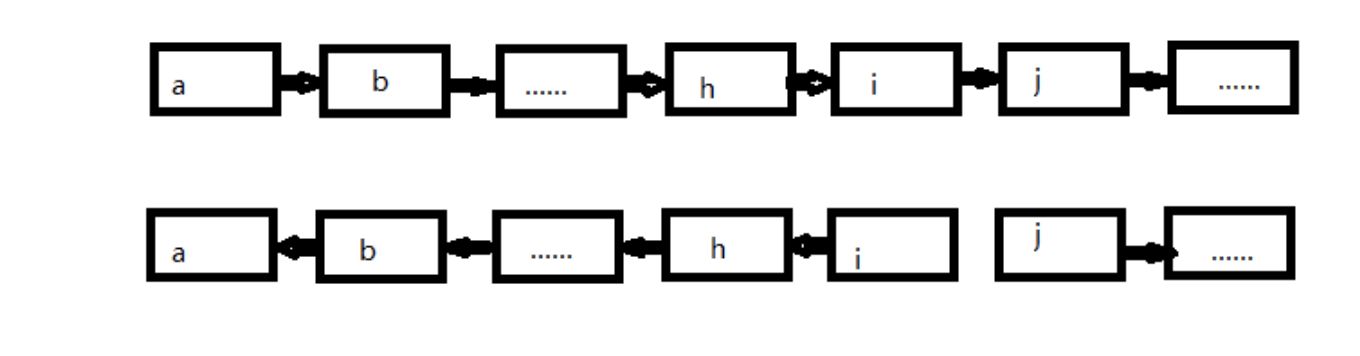
上面的图中所示的链表中,h、i和j是3个相邻的结点。假设经过若干操作,我们已经把h结点之前的指针调整完毕,这个结点的m_pNext都指向前面的一个结点。接下来我们把i的m_pNext指向h,此时结构如上图所示。
从上图注意到,由于结点i的m_pNext都指向了它的前一个结点,导致我们无法在链表中遍历到结点j。为了避免链表在i处断裂,我们需要在调整结点i的m_pNext之前,把结点j保存下来。
即在调整结点i的m_pNext指针时,除了需要知道结点i本身之外,还需要i的前一个结点h,因为我们需要把结点i的m_pNext指向结点h。同时,还需要实现保存i的一个结点j,以防止链表断开。故我们需要定义3个指针,分别指向当前遍历到的结点、它的前一个结点及后一个结点。故反转结束后,新链表的头的结点就是原来链表的尾部结点。尾部结点为m_pNext为null的结点。
代码如下
public class ReverseList_16 {
public ListNode ReverseList(ListNode head) {
if (head == null || head.nextNode == null) {
return head;
}
ListNode next = head.nextNode;
head.nextNode = null;
ListNode newHead = ReverseList(next);
next.nextNode = head;
return newHead;
}
public ListNode ReverseList1(ListNode head) {
ListNode newList = new ListNode(-1);
while (head != null) {
ListNode next = head.nextNode;
head.nextNode = newList.nextNode;
newList.nextNode = head;
head = next;
}
return newList.nextNode;
}
}
欢迎关注公众号:coder辰砂,一个认认真真写文章的公众号
参考:
https://blog.csdn.net/u010983881/article/details/78896293
https://blog.csdn.net/inspiredbh/article/details/54915091
https://www.jianshu.com/p/092d14d13216
https://www.cnblogs.com/bakari/p/4013812.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号