

01 Spark架构与运行流程
1. 阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系,为什么要引入Yarn和Spark。
Hadoop框架中其中最核心的组件有三个:HDFS、MapReduce和Yarn。HDFS为海量数据提供了存储,而MapReduce则为海量的数据提供了计算,Yarn为海量数据的处理提供了良好的系统调度。因为 Yarn 支持动态资源配置。Standalone 模式只支持简单的固定资源分配策略,每个任务固定数量的 core,各 Job 按顺序依次分配在资源,资源不够的时候就排队。这种模式比较适合单用户的情况,多用户的情境下,会有可能有些用户的任务得不到资源。Yarn 作为通用的种子资源调度平台,除了 Spark 提供调度服务之外,还可以为其他系统提供调度。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
a.运行速度快:Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
b.易用性好:Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
c.通用性强:Spark生态圈即BDAS(伯克利数据分析栈)包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,这些组件分别处理Spark Core提供内存计算框架、SparkStreaming的实时处理应用、Spark SQL的即席查询、MLlib或MLbase的机器学习和GraphX的图处理。
d.随处运行:Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算
3. 用图文描述你所理解的Spark运行架构,运行流程。
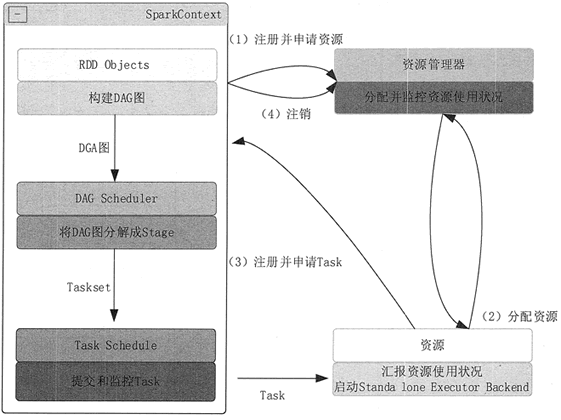
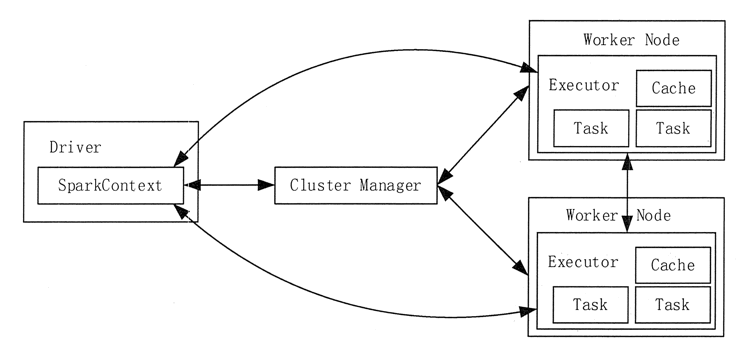
4. 软件平台准备:Linux-Hadoop

