
Netty(一)Netty简介与Java的IO模型
Netty(一)Netty简介与Java的IO模型
1 Netty简介与应用场景
Netty是由JBOSS提供的一个Java开源框架,现为Github上的独立项目。
- Netty是一个异步的、基于事件驱动的网络应用框架,用以快速开发高性能、高可靠性的网络IO程序
- Netty主要针对在TCP环境下,面向Clients端的高并发应用,或者P2P场景下的大量数据持续传输的应用
- Netty的本质是一个
NIO框架,适用于服务器通讯相关的多种应用场景
Netty框架基于TCP/IP协议,在原生的JDK IO、网络的基础上使用NIO对IO、网络进行的封装优化的框架
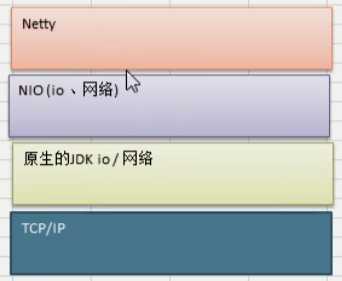
Netty的应用场景:
- 分布式系统中各个节点的远程服务调用,需要高性能的RPC框架,Netty作为基础通信组件常常被这些RPC框架所使用:如阿里的分布式服务框架Dubbo的RPC框架使用Dubbo协议默认使用Netty作为基础通信组件,用于实现各进程节点之间的内部通信
- 在游戏行业,Netty作为高性能的基础通信组件,提供了TCP/UDP以及HTTP协议栈,方便定制和开发私有协议栈,账号登录服务器
2 Java IO模型
2.1 Java IO模型简介
-
IO模型就是用什么样的通道进行数据的发送和接收(是同步的还是异步的、是单通道还是双通道、用没用到缓冲、是阻塞的还是非阻塞的等等),很大程度上决定了程序通信的性能
-
当调用一次
channel.read()或者stream.read()后,java本身不能完成数据的读取,会切换到操作系统的内核态来完成真正数据的读取(系统调用),而读取又分为两个阶段:
-
数据等待阶段:等待数据就绪
-
数据拷贝阶段:数据就绪后需要将数据从内核空间拷贝给用户空间的用户线程
IO模型的堵塞指的是在数据等待阶段是否堵塞当前用户线程,而数据拷贝阶段一定是堵塞的
IO模型的异步则是指的数据等待阶段的线程和数据拷贝的线程是否为同一个
-
-
Java IO模型主要包括三种:
BIO、NIO和AIO-
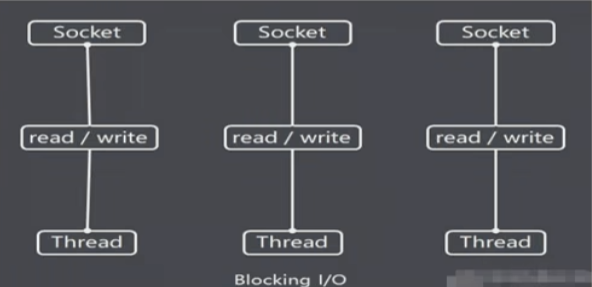
BIO:同步并堵塞(传统阻塞型),即用户线程在系统调用之后就进入堵塞状态,然后在内核完成数据等待和数据拷贝之后被唤醒,即用户线程在两个数据阶段都处于堵塞状态 堵塞IO的问题在于对于同一个用户线程的多个系统调用之间可能会互相影响,比如客户端在与服务器建立连接进行数据传输的时候,
ServerSocketChannel和SocketChannel分别对应连接建立和数据传输的channel,如果一个客户端连接后,没有发生数据传输,那么服务器线程就发生堵塞了,这也就意味着单线程下无法处理第二个客户端连接
服务器实现模式为一个连接一个线程,即客户端有连接请求的时候,服务器端就需要启动一个线程进行处理,如果这个连接不进行任何操作则会造成不必要的线程开销,可以通过线程池改善
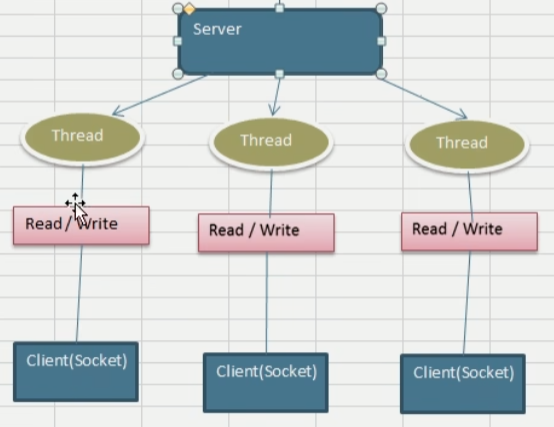
阻塞就是指的客户端想通过Socket套接字与客户端建立的连接没有响应或者拒绝的情况
-
NIO:同步非堵塞,用户线程在进行系统调用之后,不会进入堵塞状态,而是不断轮询数据是否就绪,就绪后进入堵塞状态开始复制数据,即在等待数据阶段是非堵塞的,但是在数据复制阶段是堵塞的 非堵塞IO解决了堵塞模式下单线程无法处理多个系统调用的问题,因为在事件触发但没有完成的情况下,非阻塞模式会返回一个null保证程序的正常执行,比如上面的客户端连接服务端的例子,第一个客户端连接服务器即使不发送数据也不会导致线程阻塞,服务器线程仍然会轮询是否有客户端连接或者客户端数据读取。
造成的问题就是CPU一直空转造成了性能的浪费

服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求会注册到多路复用器(选择器 Selector)上,然后由多路复用器轮询I/O请求进行处理

-
AIO:异步非堵塞,引入了异步通道的概念,采用了Proactor模式简化了程序编写,只有有效的请求才会启动线程,并且会先由操作系统完成后才通知服务器端去处理,一般适用于连接数较多且连接时间较长的应用
-
2.2 BIO、NIO、AIO的使用场景分析
- BIO方式使用于连接数目比较少且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序简单易理解
- NIO方式适用于连接数目多并且连接比较短(轻操作)的架构,比如聊天服务器、弹幕系统,服务器间通讯等,编程比较负责,JDK1.4开始支持
- AIO方式适用于连接数目多并且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较负责JDK7开始支持
2.3 Java BIO
BIO:同步并堵塞(传统阻塞型),服务器实现模式为一个连接一个线程,即客户端有连接请求的时候,服务器端就需要启动一个线程进行处理,如果这个连接不进行任何操作则会造成不必要的线程开销,可以通过线程池改善- BIO方式使用于连接数目比较少且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序简单易理解
- BIO相关的类和接口在java.io包下
- BIO编程简单流程:
- 服务器端启动一个ServerSocket
- 客户端启动Socket与服务器端进行通信,默认情况下服务器端需要对每个客户(请求)建立一个线程与之通信
- 客户端发出请求后,先咨询服务器端是否有线程响应,如果没有则会等待或者被拒绝(阻塞)
- 如果有响应,则客户端线程必须在请求结束后才能继续执行(同步)
Java BIO实例:
下面的代码用BIO模型编写了一个服务器端,实现了:
- 监听6666端口,当有客户端连接的时候,就启动一个线程与之通讯
- 使用了线程池进行了完善,能够与多个客户端同时进行通讯
- 服务器端接收客户端(使用talnet模拟)发送的数据
public class BIOServer {
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName());
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
try {
ServerSocket serverSocket = new ServerSocket(6666);
System.out.println("服务器启动");
while(true) {
// 阻塞点1:主线程等待客户端连接:accept无连接会阻塞线程
System.out.println("等待连接");
Socket accept = serverSocket.accept();
System.out.println("连接到一个客户端");
cachedThreadPool.execute(() -> {
handler(accept);
});
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void handler(Socket socket) {
System.out.println(Thread.currentThread().getName());
InputStream inputStream = null;
try {
inputStream = socket.getInputStream();
byte[] bytes = new byte[1024];
while(true) {
// 阻塞点2:客户端无输入,read堵塞子线程
System.out.println(Thread.currentThread().getName());
System.out.println("等待读取输入流");
int len = inputStream.read(bytes);
if(len == - 1) {
break;
}
System.out.println(new String(bytes, 0, len));
}
} catch (IOException e) {
e.printStackTrace();
} finally {
System.out.println("关闭和client的连接");
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2.4 Java NIO介绍
- Java NIO全称java non-blocking IO,是JDK1.4开始提供的一系列改进的输入、输出新特性,被统称为NIO(也可以理解为New IO),是同步非堵塞的
- NIO的相关类都放在了
java.nio包及其子包下,并且对原java.io包中的很多类进行了改写 - NIO的三大核心组件:
Channel(通道)、Buffer(缓冲区)、Selector(选择器) - NIO是面向缓冲区的,或者是面向块编程的。数据读取到一个它稍后处理的缓冲区,需要的时候可以在缓冲区前后移动,这就增加了处理过程中的灵活性,使用它可以提供非堵塞式的高伸缩性网络
- Java NIO的非堵塞模式,使一个线程从某通道发送请求、获取或者写入数据的时候,如果没有数据也不会堵塞等待,而是直至数据变得可以读、写之前,该线程可以继续去做其他的事情。.
- 因此NIO可以做到用一个线程来处理多个操作
- HTTP2.0使用了多路复用技术,使得浏览器能够做到一个连接并发处理多个请求,因此NIO的使用变得更加广泛
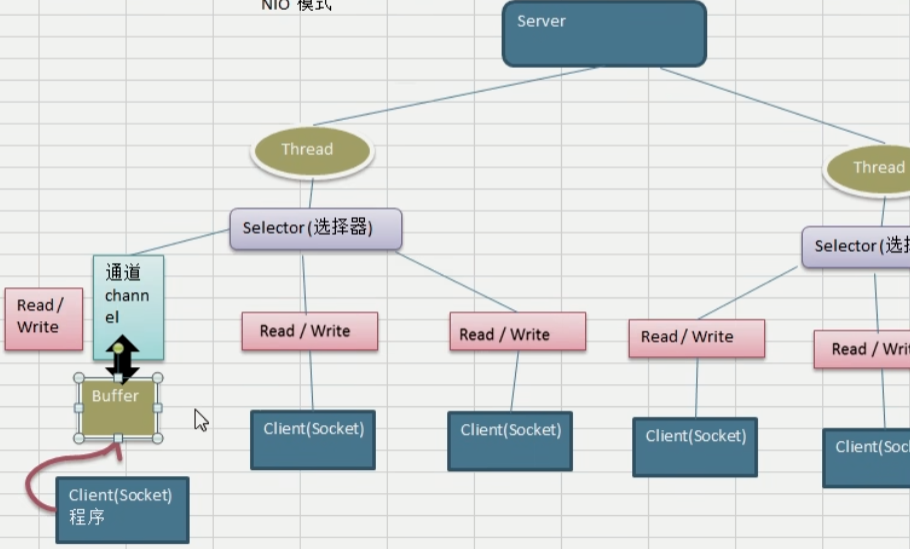
Channel即数据通道,作用是完成读写任务。
Selector根据每个通道的事件来决定为哪个通道服务
每一个通道对应一个Buffer,通道和缓冲区之间是双向连接的,即二者之间是可以相互读写的;客户端不会直接读写通道的数据,而是直接和缓冲区交互,正是由于缓冲区的设置,使得客户端在读写数据的时候不会被堵塞
2.5 AIO 异步IO
同步和异步的区别:
-
同步:线程自己去获取结果(一个线程),在进行读写操作的时候,线程需要等待结果,还是相当于闲置
-
异步:线程线程自己不去获取结果,而是由其他线程推送结果(至少两个线程),线程不必等待结果,而是将来由操作系统通过回调的方式,由另外的线程获取结果
-
阻塞IO和非阻塞IO都是由发起read请求的线程再去获取数据,因此都是同步的
异步模型需要底层操作系统(Kernel)提供支持
- Windows通过IOCP实现了真正的异步IO
- Linux系统异步IO在2.6版本引入,但是底层还是用多路复用模拟了异步IO,性能没有优势
2.6 零拷贝 && NIO优化
public static void main(String[] args) {
File f = new File("data.txt");
try {
RandomAccessFile file = new RandomAccessFile(f, "r");
byte[] buf = new byte[(int)file.length()];
file.read(buf);
Socket socket = ...;
socket.getOutputStream().write(buf);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
上面一个简单的磁盘读取+socket写入的操作,其实在底层包含了四次数据拷贝,进行了三次OS状态切换:
-
java本身不具备IO读写能力,因此在read方法调用后,会通过read系统调用,然后操作系统由java程序的用户态切换为内核态,去调用操作系统的读写能力。在这期间用户进程阻塞,操作系统调用使用DMA(Direct Memory Access)来实现文件读,期间不会使用CPU,最终将读取到的磁盘文件数据拷贝到内核缓冲区
DMA可以理解为一个硬件单元,用来解放CPU完成文件读取
-
从内核态切换回用户态后,将数据从内核缓冲区拷贝到用户缓冲区(上面的byte[] buf),期间CPU参与拷贝,无法利用DMA
-
java用户进程调用write方法,将数据从用户缓冲区(byte[] buf)拷贝到socket缓冲区,CPU参与拷贝
-
最后需要向网卡写数据,java不具备这项能力,因此需要切换用户态为内核态,然后通过系统调用调用OS的写能力,使用DMA将socket缓冲区的数据写入网卡,因此CPU不参与

从上面的过程中可以看出:
- 内核缓冲区和socket缓冲区对用户进程是可见的,因此用户进程访问不需要进行OS状态的切换,但是数据拷贝的时候必须有CPU参与
- 在内核态下,硬件写入、读取缓冲区的操作可以借助DMA方式,也就是数据的拷贝不需要CPU参与
NIO优化方案一
通过DirectByBuf可以进行优化
ByteBuffer.allocate():返回的是HeapByteBuffer,使用的还是java内存ByteBuffer.allocateDirect():返回的是DirectByteBuffer,使用的是操作系统内存
java可以使用DirectByteBuffer将堆外内存映射到jvm内存中来直接访问使用
-
这块内存不受垃圾回收影响,因此内存地址固定,有助于IO读写
-
java中的DirectByteBuffer对象仅仅维护了这个内存的虚引用,因此内存回收分为两步
DirectByteBuffer对象被垃圾回收,虚引用加入引用队列- 通过专用线程访问引用队列,根据虚引用释放堆外内存
-
减少了一次数据拷贝(用户缓冲区和内核缓冲区合二为一),用户态和内核态的切换次数没有减少,也就是三次数据拷贝三次状态切换

NIO优化方案二
通过两个channel调用transferTo、transferFrom方法进行数据拷贝,底层采用的是linux2.1后提供的sendFile方法
Sendfile 函数在两个文件描述符之间直接传递数据(完全在内核中操作,传送),从而避免了内核缓冲区数据和用户缓冲区数据之间的拷贝,操作效率很高,被称之为零拷贝
则优化之后的流程为:
- java调用transferTo方法之后,要从java程序的用户态切换至内核态,使用DMA将数据读入内核缓冲区,不会使用CPU
- 在内核态下将数据从内核缓冲区复制到socket缓冲区,需要CPU的参与
- 使用DMA将数据从socket缓冲区写入网卡,不会使用CPU
可以看到整个过程,
- 只发生了一次内核态与用户态的切换,三次数据拷贝

进一步优化(Linux2.4)

- java调用transferTo方法之后,从java程序的用户态切换至内核态,使用DMA将数据读入内核缓冲区,不需要CPU参与
- 只会将一些offset、length信息拷贝进socket缓冲区,几乎没有消耗
- 使用DMA将内核缓冲区的数据写入网卡,不会使用CPU
可以看到整个过程
-
进行了一次状态切换,两次数据拷贝(但是不需要CPU参与)
-
零拷贝并不是真正的没有数据拷贝,而是不会拷贝重复的数据到JVM内存
-
零拷贝的优点有:
- 减少了用户态和内核态的切换
- 不利用CPU计算,减少CPU缓存伪共享
- 零拷贝适合小文件传输
2.7 stream和channel的区别
-
stream属于高级API不会自动缓冲数据,channel会利用系统提供的发送缓冲区和接收缓冲区(更为底层)
-
stream仅支持堵塞式API,channel同时支持堵塞式API、非堵塞式API,网络Channel还能够配合
selector实现IO多路复用 -
两者都为全双工,即读写可以同时进行
虽然Stream是单向的,但其实可以在读的同时进行写操作的
3 ByteBuffer
3.1 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.55.Final</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1-jre</version>
</dependency>
3.2 ByteBuffer的使用
- 向buffer中写入数据,例如调用channel.read(buffer)
- 调用flip()切换到读模式
- 调用buffer.get()从buffer中读取数据
- 调用clear()或者compact()切换到写模式
public static void main(String[] args) {
try (FileChannel fileChannel = new FileInputStream("data.txt").getChannel()) {
ByteBuffer byteBuffer = ByteBuffer.allocate(10);
while (true) {
int len = fileChannel.read(byteBuffer);
if(len == -1) {
break;
}
// 切换为读模式
byteBuffer.flip();
while (byteBuffer.hasRemaining()) {
byte b = byteBuffer.get();
System.out.println((char) b);
}
// 切换为写模式
byteBuffer.clear();
}
} catch (IOException e) {
e.printStackTrace();
}
}
-
put:向byteBuffer中写入数据ByteBuffer buffer = ByteBuffer.allocate(10); buffer.put((byte) 0x61); debugAll(buffer); buffer.put(new byte[]{0x62, 0x63, 0x64}); debugAll(buffer);底层是通过一个position指针指向byteBuffer索引,每添加一个元素的时候就将指针向前移动,始终指向最后的一个元素右边的元素
+--------+-------------------- all ------------------------+----------------+ position: [1], limit: [10] +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 61 00 00 00 00 00 00 00 00 00 |a......... | +--------+-------------------------------------------------+----------------+ +--------+-------------------- all ------------------------+----------------+ position: [4], limit: [10] +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 61 62 63 64 00 00 00 00 00 00 |abcd...... | +--------+-------------------------------------------------+----------------+ -
get:获取当前position指针的元素,如果不切换为读模式的话,如上面会直接输出position所在位置的元素,也就是0而如果通过
flip切换为读模式(实质是将position指针归为0),则可以正常输出第一个元素ByteBuffer buffer = ByteBuffer.allocate(10); buffer.put((byte) 0x61); debugAll(buffer); buffer.put(new byte[]{0x62, 0x63, 0x64}); debugAll(buffer); buffer.flip(); System.out.println((char)buffer.get()); -
compact:切换为写模式,并自动将未读取的元素迁前移,如上面已经读了61,则62、63、64会前移,变为:+--------+-------------------- all ------------------------+----------------+ position: [4], limit: [10] +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 61 62 63 64 00 00 00 00 00 00 |abcd...... | +--------+-------------------------------------------------+----------------+ Process finished with exit code 0
3.3 ByteBuffer内部结构
ByteBuffer是Netty的数据容器,因为几乎所有的网络通信都涉及到字节序列的移动,ByteBuffer则是通过其特定的内部结构和方法满足了需求:
capacity:byteBuffer的容量大小position:位移指针的位置limit:指针位移限制
ByteBuffer在初始化以及读写模式切换的时候,三个指针的变化为:
-
allocate():分配初始空间的时候,此时是写模式,capacity:初始容量大小,position(写指针):0,limit:capacity的大小 -
flip():如需要读取缓冲池数据,使用flip()切换为读数据模式,此时position和limit指针位置发生变化,position切换到已经读取过、接下来需要读取的数据的索引,limit则移动到数据长度的末尾此时每读取一个字节,position就向后移动一个字节位置,直到limit位置停止
-
clear():清除缓冲区并切换为写模式,其中position变为0,limit变为capacity,也就是变为初始分配空间的状态 -
compact():把未读取的数据向前压缩,并且切换为写模式,position为数据长度的末尾,limit为写指针限制,也就是capacity
3.4 ByteBuffer常见方法
-
ByteBuffer只能一次性分配内存,不支持动态调整
-
两种分配方式:
allocate:输出的对象为class java.nio.HeapByteBuffer,也就是分配的是java堆内存,读写效率较低,受到GC的影响allocateDirect:输出的对象是class java.nio.DirectByteBuffer,也就是直接内存,读写效率高,少一次内存的拷贝且不会受到GC的影响;但是使用完成之后需要进行释放否则会造成内存泄露
System.out.println(ByteBuffer.allocate(16).getClass()); System.out.println(ByteBuffer.allocateDirect(16).getClass()); -
向byteBuffer中写入数据,有两种方法:
- 调用channel的read方法
- 调用buffer自己的put方法
-
从buffer中读取数据,也有两种方法:
- 调用channel.write方法
- 调用buffer自己的get方法,同时get方法会使position指针后移,如果想要读取重复数据,可以调用rewind方法将position重新置为0;或者调用get(int i)获取指定索引的指针,不会导致position指针的移动
-
mark:标记当前position -
reset:返回到mark的位置ByteBuffer buffer = ByteBuffer.allocate(10); buffer.put(new byte[]{'a', 'b', 'c', 'd'}); buffer.flip(); buffer.get(new byte[4]); debugAll(buffer); buffer.rewind(); System.out.println((char)buffer.get()); System.out.println((char)buffer.get()); buffer.mark(); // a b System.out.println((char)buffer.get()); System.out.println((char)buffer.get()); buffer.reset(); // c d System.out.println((char)buffer.get()); System.out.println((char)buffer.get()); -
get(index):获取到index索引下的元素,但是和get()不同不会影响到position的变化
ByteBuffer buffer = ByteBuffer.allocate(10); buffer.put(new byte[]{'a', 'b', 'c', 'd'}); buffer.flip(); buffer.get(new byte[4]); // position: 4 debugAll(buffer); // position: 4 System.out.println((char)buffer.get(0)); debugAll(buffer);
3.5 ByteBuffer和字符串之间的转换
-
使用
getBytes(),然后byteBuffer的put直接将字节数组放入:ByteBuffer buffer = ByteBuffer.allocate(16); buffer.put("hello".getBytes()); debugAll(buffer);输出为:
+--------+-------------------- all ------------------------+----------------+ position: [5], limit: [16] +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 68 65 6c 6c 6f 00 00 00 00 00 00 00 00 00 00 00 |hello...........| +--------+-------------------------------------------------+----------------+ +--------+-------------------- all ------------------------+----------------+ -
使用CharSet字符集对字符串进行编码:
ByteBuffer hello = StandardCharsets.UTF_8.encode("hello"); debugAll(hello);输出为:
+--------+-------------------- all ------------------------+----------------+ position: [0], limit: [5] +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 68 65 6c 6c 6f |hello | +--------+-------------------------------------------------+----------------+上面两种字符串转换为ByteBuffer的方式的区别在于,put方法在放入缓冲区后会仍为写模式但是CharSet字符集会自动转化为读模式,所以position为0
-
使用wrap方法也会把字节数组放入缓冲区,但是不会像put方法一样修改position指针,也就是会自动更改为读模式
ByteBuffer wrap = ByteBuffer.wrap("hello".getBytes()); debugAll(wrap); -
ByteBuffer转换为字符串:
ByteBuffer wrap = ByteBuffer.wrap("hello".getBytes()); debugAll(wrap); System.out.println(StandardCharsets.UTF_8.decode(wrap)); buffer.flip(); System.out.println(StandardCharsets.UTF_8.decode(buffer)); System.out.println(StandardCharsets.UTF_8.decode(hello));buffer是通过put字符数组直接添加的,因此处于写模式,需要转化为读模式才能够获取
3.6 ByteBuffer分散读与集中写--减少ByteBuffer的数据拷贝
-
在读取文件的时候,拆分读取内容会涉及到很多拆分和复制的消耗,因此可以使用分散读取(ScatteringRead)的方法直接将内容对到对应的ByteBuffer中,可以减少很多数据拷贝:
@Test public void testScatteringReads() { try (FileChannel channel = new RandomAccessFile("words", "r").getChannel()) { ByteBuffer buffer1 = ByteBuffer.allocate(4); ByteBuffer buffer2 = ByteBuffer.allocate(4); ByteBuffer buffer3 = ByteBuffer.allocate(4); channel.read(new ByteBuffer[]{buffer1, buffer2, buffer3}); debugAll(buffer1); debugAll(buffer2); debugAll(buffer3); } catch (IOException e) { throw new RuntimeException(e); } } -
在写入文件的时候,可以对多个ByteBuffer合并为同一个然后进行写入,但是会造成额外的数据拷贝,因此可以使用集中写的方式将多个ByteBuffer进行组合然后写入
@Test public void testGatheringWrites() { try(FileChannel fileChannel = new RandomAccessFile("words", "rw").getChannel()) { ByteBuffer b1 = ByteBuffer.wrap(" Hello".getBytes()); ByteBuffer b2 = ByteBuffer.wrap(" World".getBytes()); ByteBuffer b3 = ByteBuffer.wrap(" 你好".getBytes()); fileChannel.write(new ByteBuffer[]{b1, b2, b3}); } catch (IOException e) { throw new RuntimeException(e); } }
3.7 ByteBuffer的黏包和半包问题
-
黏包:多条数据通过网络发送给服务端的时候,由于通常是一次性发送,所以服务端也会出现一次性接收多条数据的情况
// Hello, world\n I'm zhangsan\nHo -
半包:由于缓冲区大小限制,只接受了一条数据的一部分,第二部分被放到了其他的缓冲区中
// w are you? // Ho在上一个缓冲区,出现了半包 -
使用ByteBuffer解决:
/** * ByteBuffer解决黏包半包问题 */ @Test public void testByteBufferExam() { ByteBuffer buffer = ByteBuffer.allocate(100); buffer.put("Hello, world\nI'm zhangsan\nHo".getBytes()); split(buffer); buffer.put("w are you".getBytes()); split(buffer); } private void split(ByteBuffer buffer) { // 切换为读模式 buffer.flip(); for(var i = 0; i < buffer.limit(); i++) { if(buffer.get(i) == '\n') { // 遇到分隔符,则需要的长度为len+1-position指针的位置 var length = i + 1 - buffer.position(); // 新建一个ByteBuffer用于写入 ByteBuffer allocate = ByteBuffer.allocate(length + 1); for(var j = 0; j < length; j++) { allocate.put(buffer.get()); } debugAll(allocate); } } // 只是清除缓冲区中已经读取的数据,将未读取的数据放到前面 buffer.compact(); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号