MySQL(十七)查询优化(二)与数据库主键设计
查询优化(二)
1 覆盖索引
什么是覆盖索引
看下面的例子,对于联合索引age_sno_name,当查询字段较少时能够使用索引,而字段较多的时候只能进行文件排序,这是由优化器判断通过索引加回表或者直接文件排序的成本来决定的。这种一个索引包含了满足查询结果的数据(select + where + join字句用到的列)就叫做覆盖索引。
SHOW INDEX FROM student;
-- idx_age_sno_name
EXPLAIN SELECT * FROM student ORDER BY age, stu_no;

EXPLAIN SELECT age, name, stu_no FROM student ORDER BY age, stu_no;
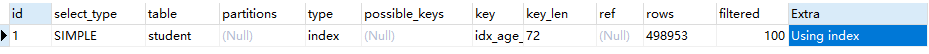
EXPLAIN SELECT age, name, stu_no, id FROM student ORDER BY age, stu_no;

二级索引包含主键,这种就是覆盖索引无需回表
EXPLAIN SELECT age, name, stu_no, class_id FROM student ORDER BY age, stu_no;

非索引覆盖需要回表但是优化器还是判断成本低于文件排序
举例一
CREATE INDEX idx_age_name ON student(age, name);
EXPLAIN SELECT * FROM student WHERE age <> 40;

EXPLAIN SELECT age, name FROM student WHERE age <> 40;

明明这里用的是不等于,但是索引还是生效了?
这是因为优化器判断遍历索引树就能得到检索字段,成本要比扫描全表(全部字段)低,因此还是用到了索引
这里可以试下如果添加name字段,key_len还是5表示索引还是失效的,用了但是没完全用
EXPLAIN SELECT age, name FROM student WHERE age <> 40 AND name ='abc';
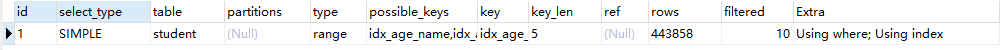
举例二
EXPLAIN SELECT * FROM student WHERE name like '%a';

EXPLAIN SELECT name, age FROM student WHERE name like '%a';
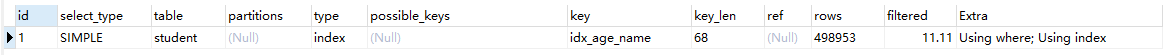
这里甚至都不满足最左前缀,但是仍然和上面一样使用了索引
从key_len=4 + 1(age null值列表) +20 * 3(utf8mb3 一个字符三个字节) + 1(name null值列表)+ 2(name变长字段列表) =68看,用到了索引的两个字段
覆盖索引的利弊、
-
避免了InnoDB表的二次查询(回表)
-
把随机IO变为了顺序IO
经过覆盖索引,在二级索引中查到的记录相对来说比较连续集中,但是经过回表到聚簇索引之后可能就非常离散了
-
索引字段的维护需要代价,建立冗余索引来支持覆盖索引需要权衡
2 ⭐ 索引下推(ICP)
索引条件下推(Index Condition PushDown)是mysql5.6新的特性,是一种存储引擎使用索引过滤数据的优化方式,目的是为了减少回表操作。
- 如果没有ICP,存储引擎会遍历索引定位基表中的行,然后将其交给mysql服务器,由mysql服务器评估where后面的条件是否保留该行
- 有ICP之后,如果where后面的条件可以仅使用索引列进行筛选,则存储引擎就可以提前进行条件过滤,减少回表操作。
ICP的开启与关闭
默认条件下是启动索引条件下推的,可以通过设置系统变量optimizer_switch来设置。
SET optimizer_switch = 'index_condition_pushdown=off';
SET optimizer_switch = 'index_condition_pushdown=on';
ICP案例
举个栗子,首先创建一张表和索引:
CREATE TABLE `people` (
`id` INT NOT NULL AUTO_INCREMENT,
`zipcode` VARCHAR(20) COLLATE utf8_bin DEFAULT NULL,
`firstname` VARCHAR(20) COLLATE utf8_bin DEFAULT NULL,
`lasename` VARCHAR(20) COLLATE utf8_bin DEFAULT NULL,
`address` VARCHAR(50) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY(`id`),
KEY `zip_last_first` (`zipcode`, `lasename`, `firstname`)
)ENGINE=INNODB auto_increment =5 DEFAULT CHARSET = utf8mb3 collate=utf8_bin;
INSERT INTO `people` VALUES
('1', '000001', '三', '张', '北京市'),
('2', '000002', '四', '李', '上海市'),
('3', '000003', '五', '王', '南京市'),
('4', '000001', '六', '赵', '天津市')
查询下面语句的执行计划,由于lasename使用了百分号前缀,所以联合索引到该字段及之后失效,keylen为63表示只使用了zipcode(20 * 3 + 2 + 1),但是extra有using index condition表名在回表之前针对lasename进行了条件过滤,也就是索引条件下推。而address不在索引范围内,因此只能够通过回表由mysql服务器进行过滤,extra自然也就有using where。
EXPLAIN SELECT * FROM `people`
WHERE zipcode = '000001'
AND lasename like '%张%'
AND address like '%北京市%'

ICP的使用条件
- 如果访问表的类型为range、ref、eq_ref、ref_or_null可以使用ICP
- ICP可以适用于InnoDB和MyISAM表
- 对于InnoDB表,ICP只适用于二级索引,目的是为了减少回表操作带来的IO消耗
- 当SQL使用覆盖索引的时候不能进行ICP,因为索引覆盖不会回表
- 相关子查询不能使用ICP
3 其他优化策略
3.1 ⭐Exists和in的区分
对比下面的两个sql的差异,应该如何选择?
SELECT * FROM A WHERE A.cc IN (SELECT cc FROM B);
SELECT * FROM A EXISTS (SELECT cc FROM B WHERE A.cc = B.cc);
- 如果A表比较大,则选择用IN的方式
- 如果B表比较大,则选择用EXISTS的方式
第一个sql是非相关的子查询,类似于
for i in B for j in A A.cc = b.cc then ...而第二个是相关子查询,类似于外循环,即外面遍历一条记录就送给里面,然后里面进行匹配
for i in A for j in B A.cc = b.cc then ...秉承小表驱动大表的原则,A表小则选择exists,B表小则选择in
3.2 ⭐Count(*)与Count(具体字段)效率
Select Count(1)、Select Count(*)、Select Count(具体字段)的查询效率是怎么样的?
在结果相同的前提下,
-
Select Count(1)、Select Count(*)都是对所有结果进行统计,本质上没有区别,执行时间可能略有差异- 如果是MyISAM存储引擎,统计表的行数是O(1)复杂度,因为MyISAM表都会有一个meta信息存储
row_count值,其一致性由表级锁保证 - 而如果是InnoDB存储引擎,由于InnoDB支持事务,采用行级锁和MVCC机制,所以无法像MyISAM一样维护一个
row_count,必须进行全表扫描,采用循环+计数的方式完成统计,时间复杂度O(n)。
- 如果是MyISAM存储引擎,统计表的行数是O(1)复杂度,因为MyISAM表都会有一个meta信息存储
-
在InnoDB存储引擎中,
Select Count(具体字段)应该尽量选择二级索引,因为聚簇索引包含的信息明显大于二级索引(需要存储真实数据),加载到内存的消耗更大。而对于Select Count(1)、Select Count(*)来说,它们不需要查找具体的行,只需要统计行数,因此系统会默认使用占用空间较小key_len的二级索引,没有再使用主键索引。 -
count(1)会查询所有记录,包含字段为null的,而count(具体字段)则不会
3.3 ⭐关于select(*)
尽量不要使用select *
- mysql在解析过程中,还要查询
数据字典将*转化为具体的字段,耗费大量的时间和资源 - 无法使用
索引覆盖
3.4 ⭐Limit 1对优化的影响
- 针对的是会进行全表扫描的sql,如果可以确定sql查询的结果只有一条,找到之后就不会继续扫描了,可以加快查询的速度
- 如果该字段拥有
唯一索引,则意义不大
3.5 多使用Commit
只要有可能,就应在程序中多使用commit,这样程序的性能能够得到提升,需求也会因commit释放的资源而减少。commit释放的资源:
- 回滚段上用于恢复数据的信息(undo log)
- 被程序语句获得的锁
- redo 、undo log buffer的空间
- 管理上述资源的内部花费
4 淘宝数据库的主键设计
4.1 自增id的问题
-
可靠性不高:存在
自增id回溯的问题,直到8.0才修复自增id回溯:假设我们设置id自增为1,插入三条数据,然后这时删除一条记录,这时候用
SHOW CREATE TABLE命令查看该表的AUTO_INCREMENT的值是4,然后重启数据库,再次查看会发现AUTO_INCREMENT变成了3原因就是
AUTO_INCREMENT的值是保存在内存中的,数据库重启后会计算当前表的记录数然后重新设置导致回溯出错 -
安全性不高:对外暴露的接口容易暴露信息,如/usr/1,很容易被爬虫进行数据爬取
-
性能差:需要在mysql服务端进行生成
-
交互多:业务需要根据执行一次
lase_insert_id获取刚才插入的自增值,多一次sql对于海量并发系统就多很多性能消耗 -
局部唯一性:自增的id只在当前数据库唯一,无法用于分布式系统
4.2 业务字段充当主键造成的问题
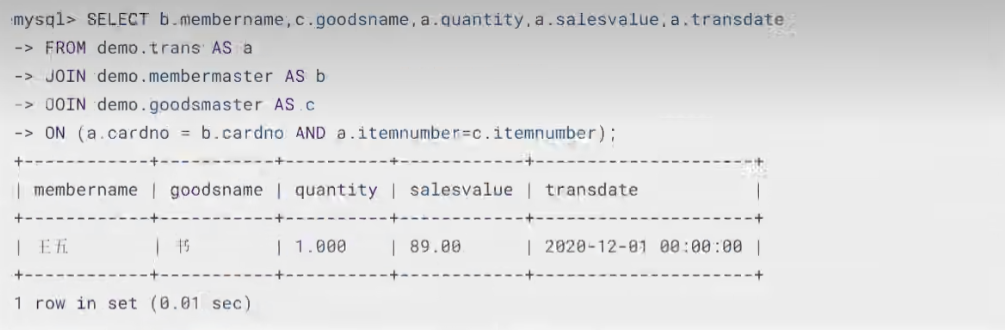
比如下面使用卡号充当主键,张三注销卡后,王五注册了一张该卡号的卡,然后查询订单信息(订单不会随着卡注销而消除的)的时候就会查到张三的消费。


4.3 推荐的主键设计
非核心业务:对应表的主键自增id,如告警、监控、日志信息等数据量较小的表核心业务:主键设计至少是全局唯一而且自增的,全局唯一是为了保证分布式之间的唯一性,自增则是保证插入数据的性能,防止忽大忽小的主键导致页分裂影响性能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号