Redis之使用篇
Redis value类型
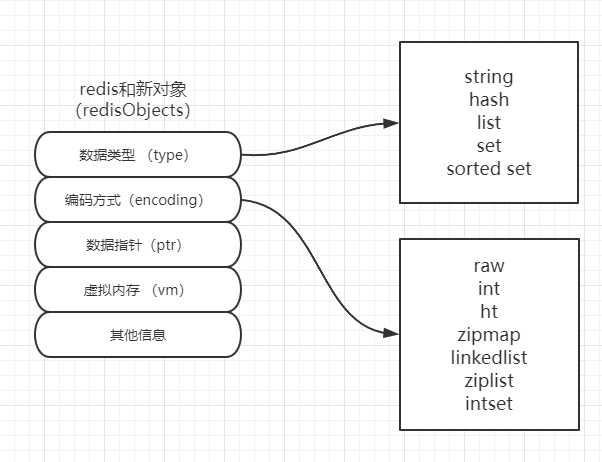
Redis默认为16个库,在配置文件中可以修改,从0开始,每个库互相隔离,库中存储的是key,vaule键值对。value分为五种数据类型。内部维护正负索引。
Redis内部内存管理:
String 类型
String类型的值最大存储512M
-
字符串
set k1 hello nx只能新增,只有当k1不存在时才能设置成功。set k1 hello xx只能修改,只有当k1存在时才能设置成功。getset指令相比于先get再set而言,少了一次IO。使用场景:分布式锁
-
数值
set k1 999type为string,而encoding为int,这样做incr操作的时候不需要判断类型,直接计算即可。redis是二进制安全的,从socket中读取的是字节流,并不对字节流中的数据进行编码,保证了数据不会被破坏。比如说,如果编码后存储,两个客户端的编码解码不一致,A存储一个字符为两个字节,而B解析出来是四个字节,可能会造成溢出。
使用场景:在一些系统中看似不是很重要的统计,抢购,秒杀,详情页中数据统计,点赞,评论等。可以规避并发情况下对数据库的事务操作,完全由redis内存操作代替。
-
bitmap
使用场景 :
-
一个用户系统,要求统计用户登录天数,且窗口随机(某天到某天的数)。
-
常规mysql:存储在表中,每个用户每天登录即为一行数据,每行数据至少需要id,日期等,在8个字节左右,当用户量特别大的时候,查询效率会很慢。会有磁盘IO,读取出来的数据进行解码,再做计算。
-
利用redis的bitmap:一年固定有365天或366天,这样可以用400个二进制位,即最多50个字节就可以记录每个用户一年的登录情况。某天登录把对应的二进制位改为1即可,当查询时,使用bitcount计算即可。即节省了空间,又提高了效率。假如说有1000W用户,500M空间存储足以。
-
-
统计活跃用户(去重),窗口随机
以每天的日期作为key,每个用户是一个二进制位,举个例子:假如说20200101这一天,用户A(第一个bit位)登录了,用户B(第7个bit位)登录了,20200102这一天,只有用户A登录,那么统计20200101-2020-01-02这两天的活跃用户数。即可用以下命令计算:
-
第一天:
setbit 20200101 1 1setbit 20200101 7 1 -
第二天:
setbit 20200102 1 1
统计:
先去重:
bitop or destkey 20200101 20200102 获取结果:
bitcount destkey 0 -1 -
-
List 类型
- 描述栈:
- 同向命令
lpush+lpop或者rpush+rpop
- 同向命令
- 描述队列:
- 反向命令
lpush+rpop或者rpush+lpop
- 反向命令
- 描述数组:
lindex、lset对索引进行操作
- 阻塞单播队列(FIFO):
blpop、brpop如果有十个客户端阻塞着,当有数据之后,先服务先到的,剩下的继续阻塞。
Hash 类型
相当于Java中的HashMap。可以对field进行数值计算,场景:点赞、收藏、详情页等。与文档型存储的区别是,value是个hash类型,但hash中的value不能再嵌套,只能是单一类型。
Set 类型
-
无序去重
-
集合操作:交集、并集等,并提供存储到目标
key的方法。 -
随机事件
SRANDMEMBER命令 [key] [count]- 如果
count是个正数:取出一个去重的结果集(不能超过已有集) - 如果
count是个负数:取出一个带重复的结果集,一定满足count值 - 如果是
count是0:不返回结果
- 如果
使用场景:抽奖需求。
根据奖品数量、用户数量的不同,使用姿势也不同。排列组合。
有10个奖品,20个用户,且不可重复。则可以使用
SRANDMEMBER k1 10来抽取10个用户。SPOP命令 随机弹出一个值
使用场景:例如公司年会抽奖,每轮只抽取一个人,且不可重复,相当于中奖后被剔除抽奖资格。
Sorted Set 类型
-
维护顺序,按
score值从小到大,且不随命令而改变。用于排序的值叫做score,实际存储的值叫做member。ZINCRBY可以对数值进行计算,且改变score后自动维护顺序。使用ZREVRANGE倒序获取应用场景 :歌曲排行榜,根据播放量 或者下载量去衡量,排出前十。
-
集合操作:交集、并集。带权重/聚合指令
-
排序实现:
ziplist压缩链表 +skip list跳跃表在Redis中有序集合的实现,不完全是使用跳表,在数据量少的情况下,Redis会使用压缩链表
ziplist来实现,当数据量超过阈值才会使用跳表。存储结构如图:
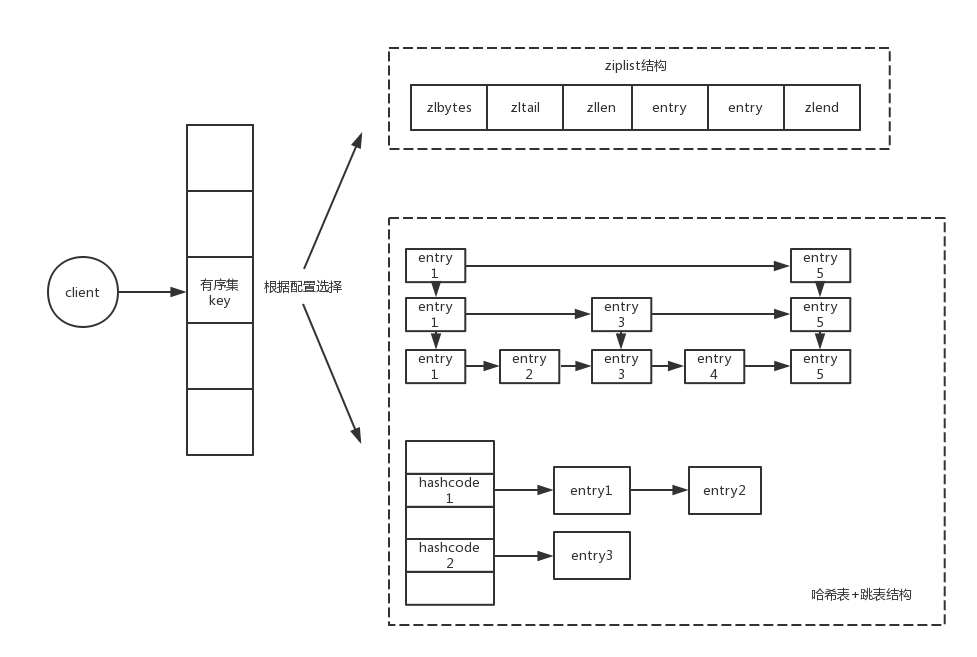
每个entry都是由score+member组成,链表加多级索引的结构,就是跳表
跳表这个动态数据结构,不仅支持查找操作,还支持动态的插入、删除操作,而且插入、删除操作的时间复杂度也是 O(logn)。
Redis发布订阅:pubsub
只有先开启publish监听,再发布消息才可以收到。
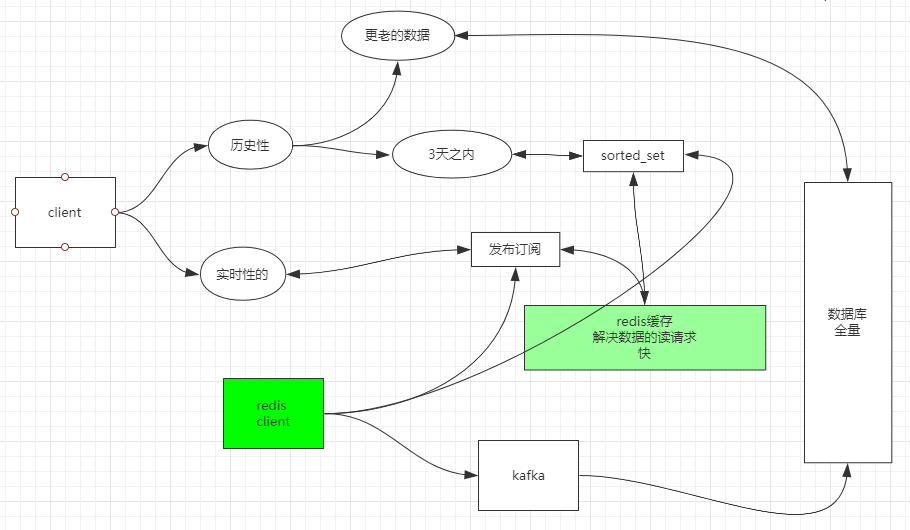
场景:除了聊天室事实监控消息外,QQ聊天记录怎么存,三天以内的存哪,历史的存哪?
第一种方案:
-
存储数据:一个Redis客户端往三个方向写
PUBLISH命令,向channel实时的发布消息。- 几天之内的可以用
sorted_set实现,把日期时间作为score,消息内容作为member,保证了有序性。 - 全量性必须由关系型数据库来满足,某
service发送到kafka,DB Service从kafka消费消息并写入数据库。
-
读取数据:
SUBSCRIBE命令,从一个或多个channel读取消息。- 几天内的可以用
ZRANGE命令从sorted_set中读取。 - 更老的消息查询数据库。
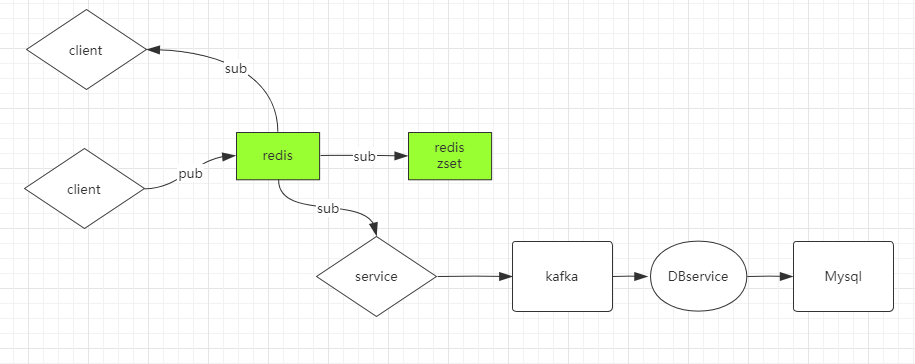
第二种方案:
此种方案在第一种的基础上,用了两个Redis客户端,客户端B订阅客户端A,并存入sorted_set,预防单点故障问题。
Redis事务
Redis的事务并不是一个完整的事务,因为Redis追求的是快!
MULTI指令开启一个事务,EXEC指令执行所有的commands
由于Redis是单进程的,所以开启事务后,假如说有多个client连接,哪一个客户端的exec先到达就会先执行哪个事务。Redis是不支持事务回滚的,但是有个watch命令,用法就是在开启事务之前,先执行一个watch。原理是利用乐观锁CAS来监控一个或多个key,如果在事务提交之前key被修改了,在执行exec的时候将撤销监控的key相关的所有commands。

插曲:布隆过滤器
缓存穿透问题:
正常情况下,我们去查询数据都是存在。那么请求去查询一条压根儿数据库中根本就不存在的数据,也就是缓存和数据库都查询不到这条数据,但是请求每次都会打到数据库上面去。这种查询不存在数据的现象我们称为缓存穿透。
解决方案:
-
缓存空值
之所以会发生穿透,就是因为缓存中没有存储这些空数据的key。从而导致每次查询都到数据库去了。那么我们就可以为这些key对应的值设置为null 丢到缓存里面去。后面再出现查询这个key 的请求的时候,直接返回null 。这样,就不用在到数据库中去走一圈了,但是别忘了设置过期时间。
-
BloomFilter
用法:把数据库已有的数据全部映射到
bitmap中,当有请求来查询的时候,bloom判定不存在,直接返回给业务系统;如果判定存在,有可能是真的有此数据,也有一定几率会被误判为数据存在,所以说并不是百分百拦截的,但是可以阻止大量恶意请求,而且成本很低。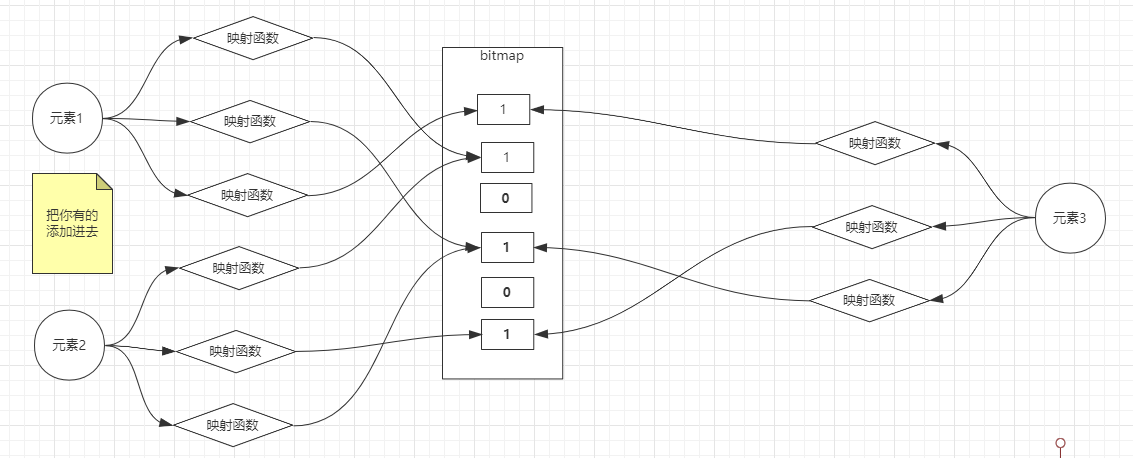
业务使用流程:
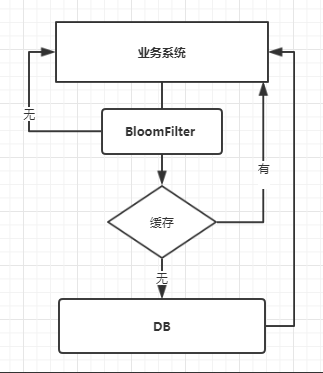
Redis作为缓存
缓存数据“不重要”,缓存不是全量数据,缓存应该随着访问而变化,即热数据,减少数据库访问压力。因为内存大小是有限的,所以Redis里的数据应该随着业务变化,只保留热数据。
当Redis作为缓存使用时:
-
根据业务逻辑需求,设置key的有效期。
-
倒计时:
set k1 key ex seconds或EXPIRE key seconds设置多少秒后过期,并且不会随着访问延长时间。但是当重新设置该key的值时,会直接剔除过期时间。
-
定时:
EXPIREAT key timestamp在某个时间点过期
-
-
根据业务运转,随着访问的变化应该淘汰冷数据。
- 总内存大小,可以在配置文件中配置maxmemory。
- 淘汰策略
- noeviction:当内存达到限制后返回错误。
- allkeys-lru: 最少使用
- allkeys-lfu: 访问次数最少
- volatile-lru: 最少使用,但仅限于在过期集合的键。
- volatile-lfu: 访问次数最少,但仅限于在过期集合的键。
- allkeys-random: 回收随机的键
- volatile-random: 回收随机的键,但仅限于在过期集合的键。
- volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键。
作为缓存来使用的话,一般会在allkeys-lru和 volatile-lru之间选择其中一种。如果只有少部分是设置了过期的话,那么就采用allkeys-lru的方式,提高回收效率。
过期判定原理:
Redis keys过期有两种方式:
-
被动
当一些客户端尝试访问它时,key会被发现并主动的过期。
-
主动轮询
不断重复过期检测,直到过期的key的百分比低于25%
Redis每秒做十次的事情:
- 测试随机的20个keys进行相关过期检测。
- 删除所有已经过期的keys。
- 如果有多于25%的keys过期,重复步奏1
这意味着在任何给定时刻,使用内存的已经过期的键的最大数量等于每秒写入操作的最大数量除以4
两种持久化方式
1.快照/副本:在某个时间点记录一份,当出现问题时可以按照存储的时间点恢复数据。比如游戏存储点。
2.日志:对服务发生增删改的时候,会记录在日志里,便于恢复数据。
RDB
时点性:当截止到8点需要写入磁盘时,数据并不是瞬间写入的,那么写入的数据是什么时间点的呢?如果是8点的,是如何实现的?
方案一:阻塞,开始写入时Redis不对外提供服务,如果写入时间过长,Redis服务相当于停服,此种方法显然不合适。
方案二:非阻塞,Redis一边提供服务,一边持久化数据。那么如何保证已经写入的数据不会再次被修改呢?也就是怎么保证时点不混乱。
补充知识:
管道 | 命令:
-
前一个命令的输出作为后一个命令的输入
-
管道|会触发创建子进程
验证:$$和$BASHPID都是打印当前进程ID
-
echo $$ | more:可以看到输出的进程ID跟直接
echo $$的打印值一样,好像并没有开启子进程,原因是$$的优先级要高于管道|,相当于先输出了当前进程ID,又开启了左右两个子进程。 -
echo $BASHPID | more:可以看到每次打印的进程ID都不一样,因为管道命令会开启两个子进程,每次打印的都是开启的子进程的进程ID。
引出父子进程的概念:
常规思想:进程之间数据是隔离的。
进阶思想:父进程是可以让子进程看到数据的。
通过验证,Linux中通过export的环境变量,子进程的修改不会破坏父进程,父进程的修改也不会破坏子进程。
那么就可以解决上面的时点性问题了,在8点的时候Redis父进程开启一个子进程,父进程负责对外提供服务,子进程负责复制一份数据写入文件。那么又会有两个问题,一是创建子进程的速度多快?二是完全复制一份数据的话,内存空间够不够?
引出系统调用fork(),速度相对快,占用空间小。使用写时复制实现,唯一的损失是复制所需的时间和内存。创建子进程的时候并不发生复制,使得创建进程变快,根据经验,父子进程不可能把所有数据都修改一遍,玩的是指针。
在Redis进程中有虚拟内存跟实际内存中会有一个映射关系,子进程只需要复制一份指针指向内存的同一位置即可,父子进程之间的修改是互不影响的,所以在修改时在物理内存中先生成新的数据,再把父进程指针指向新的数据,而子进程还是指向原来的位置。
RDB触发方式:
save,阻塞。 关机维护时可以使用save。bgsave,后台处理,调用fork- 配置文件编写规则:在配置中标识为
save,实际执行的是bgsave。
弊端:
- 不支持拉链,只有一个dump.rdb。需要人为去干预,比如定时复制一份到其他地方。
- 丢失数据相对多一些,时点与时点之间窗口数据容易丢失。
优点:类似Java中的序列化,恢复的速度相对快
AOF
优点:
丢失数据少,在Redis中,RDB和AOF可以同时开启,但是如果开启了AOF,只会用AOF恢复,4.0版本以后,AOF中包含RDB全量,增加记录新的写操作。
弊端:体量无限增大,导致恢复慢。
为了让日志足够小,所以需要一个解决方案:
-
4.0之前,重写,删除抵消的命令,合并重复的命令,最终也是一个纯指令的日志文件。
-
4.0之后,重写,将老的数据RDB到AOF文件中,将增量的以指令的方式Append到AOF中,AOF是一个混合体,利用了RDB的快和日志的全量。

