Redis之初识篇
前置常识:
读取速度
磁盘:
- 寻址:
ms级别 - 带宽:G/M
内存:
- 寻址:
ns级别 - 带宽:很大
从寻址的速度上,磁盘比内存慢了10W倍
I/O buffer
磁盘有磁道、扇区,一扇区为512 Byte,如果每次从磁盘读取512 Byte会带来一个成本问题,即索引体积太大,所以操作系统无论读多少数据,最少从磁盘读取4K大小的数据。
一般操作系统
4K,不会造成浪费,也支持存储一些小文件,假如说服务器想做视频录像之类的,4K大小的话,就有点得不偿失,不如换的大一点,一次性读的东西多一些,减少磁盘寻址时间。4K大小其实取决于上层应用对IO的使用量,是IO密集型还是一些小文件。
前言
开始数据是存储在文件中的,随着文件变大,数据增多,查询会变慢。为什么?磁盘I/O成为瓶颈,数据库出现,定义每个data page 大小为4K,把数据存储到一个个的data page中,与操作系统读取数据大小一致,即每次都是一次I/O,但是此时还是全量IO,并没有加快查询速度,必须建立索引,索引也是4K大小,指向每个data page。数据和索引都是存储在磁盘中的,在内存中还有一个B+树(树干),流程为:用户请求,命中索引,索引加载到内存,然后解析完,得知下次该读取哪一页上的数据,再将其加载到内存读取。充分利用内存读取快,磁盘存储容量大的特点。
关系型数据库在建表的时候,都必须给出
schema,类型:字节宽度,即固定大小,即使没有给出具体值,也会用占位来填充,存储的时候倾向于行级存储,这样每次修改数据的时候,直接填充或覆盖数据,不会造成移动数据。
这里引出一个问题:数据库表数据量大的时候,性能下降?(从寻址和带宽两个方面回答)
前提:如果表有索引
-
增删改:会变慢,因为要维护索引,即索引中的数据需要移动。
-
查询速度:
-
如果是1个或少量请求的话,查询速度依然很快。
-
如果是大量并发请求,而刚好查询的数据又落在不同的
page页上,磁盘的带宽会影响查询速度。原因是需要依次把page页上的数据加载到内存,当数据量大的时候,就会很慢。
-
基于纯磁盘速度慢,纯内存数据库SAP HANA太奢侈,缓存技术诞生。
Memcached与Redis的区别是什么?
Memcached也是k,v存储形式,但是value没有类型的概念,而Redis的value有类型的概念。
通常存储数据的方式有三种:
- k = 1 k = a
- k = [1,2,3] k = [a,b,c]
- k = {k=a} k =
但从存储结构来看,k,v也可以存储复杂类型数据,即满足所有需求,为什么value要分类型呢?可以拿一个client从缓存中取出某一个元素来分析:
- Memcached
- 第一,返回value所有的数据到client,server端网卡IO会拖慢
- 第二,客户端需要编写复杂的代码解码返回的数据
- Redis
- value的类型并不是最重要的,重要的是
Redis的server中有对应每种类型的方法,客户端只需调用对应方法即可,不需要编写复杂代码。(计算向数据移动)
- value的类型并不是最重要的,重要的是
Redis是单进程,单线程,单实例的,为什么速度很快?
Redis实际上并不是单线程的,只是处理用户请求是单线程来处理,保证了处理的顺序性(每个连接内的命令顺序执行),所以一般称为单线程的。
操作系统都有kernel,每个client连接都会先连接到kernel,Redis进程与内核之间使用的是epoll,非阻塞多路复用,epoll是系统内核提供的一种系统调用,来遍历多个client连接,谁有请求就处理谁。
插曲(内核演变过程)
-
BIO:早期的BIO模型,客户端连接系统内核后,线程从内核中读取文件,只能是
read读取(socket blocking),如果没有数据,则会一直阻塞,所以只能开辟多个线程/进程处理。如果只有一个cpu的话,某一时间片上的某一时间点的cpu是空闲的,并不是一直在处理,导致资源浪费,线程过多的话,切换上下文需要成本,硬件没有被充分利用。问题:上下文切换成本高,资源浪费。Linux系统中一切皆文件,都由文件描述符
fd(file descriptor)来表示,0是标准输入,1是标准输出,2是错误输出,再开启新的IO会产生更多的描述符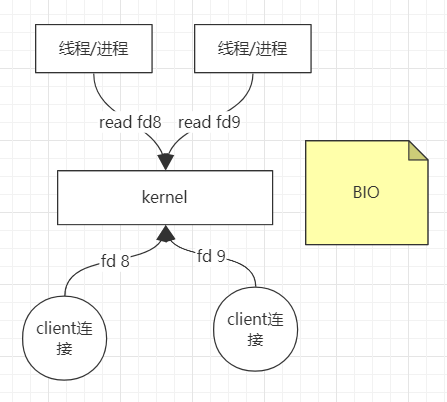
-
NIO:于是内核发生变化,内核中的socket可以是non-block的,此时只需要一个线程/进程处理,轮询文件描述符,轮询发生在用户空间。此时是同步非阻塞
NIO。此时出现了一个成本问题,如果有1000个fd,用户进程需要调用1000次kernel。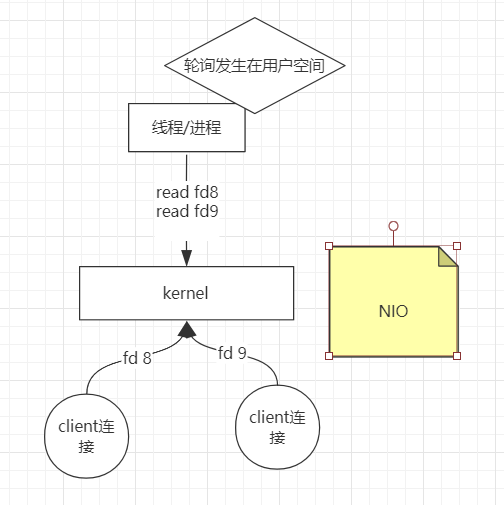
-
多路复用NIO:于是内核继续升级,内核增加了一个系统调用
select,(用man指令看select),支持一次性传多个fds,把1000个fd传给kernel之后,由kernel来确定哪些连接建立,然后再返回给线程/进程,此时再循环去读返回的fds。此时为多路复用NIO。**此时的问题是,用户态和内核态之间fd拷来拷去。 **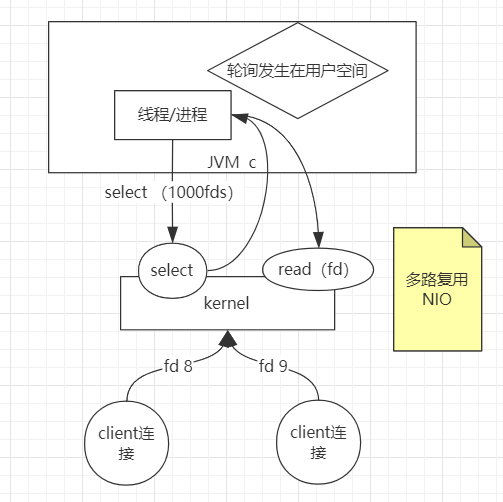
-
共享空间:进程有进程的内存空间,内核有内核的内存空间,进程是无法访问内核空间的,所以内核提供了系统调用方法。为了解决这个问题,于是内核与用户之间有了共享空间,系统调用为
mmap内存映射,共享空间数据结构为红黑树+链表,线程/进程就可以把之前的1000个fds放到共享空间(红黑树)中,然后kernel从中读取fd通过所有的IO处理,把准备好的数据放到链表里,上层用户空间就可以直接从链表中读取。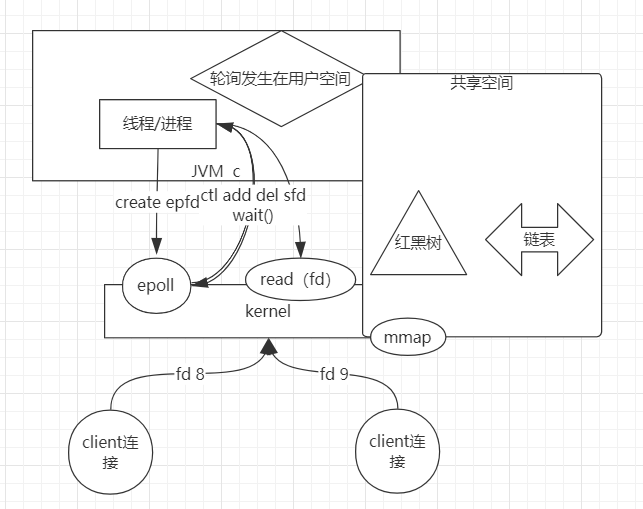
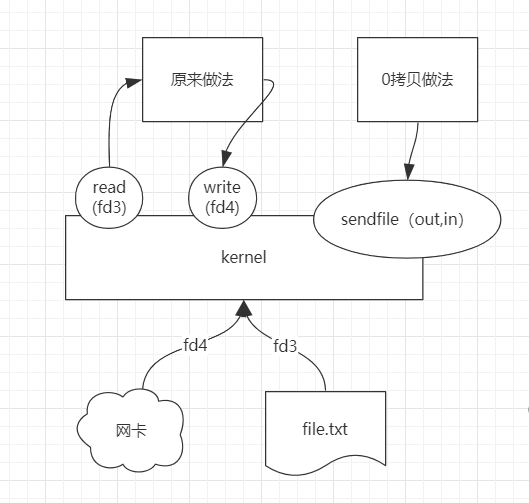
插曲中的插曲:零拷贝
网卡、文件都有IO,传统的用户去读写的时候,是先从kernel中read数据,再write到kernel,这个过程会有数据拷贝。内核提供了一个sendfile的系统调用,直接把out、in一块传入,由kernel直接读写,实现零拷贝。
epoll的两种触发方式
epoll监控多个文件描述符的I/O事件。epoll支持边缘触发(edge trigger,ET)或水平触发(level trigger,LT),通过epoll_wait等待I/O事件,如果当前没有可用的事件则阻塞调用线程。
select和poll只支持LT工作模式,epoll的默认的工作模式是LT模式。
-
水平触发的时机
对于读操作,只要缓冲内容不为空,LT模式返回读就绪。
对于写操作,只要缓冲区还不满,LT模式会返回写就绪。
当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait()时,它还会通知你在上没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你。如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率。 -
边缘触发的时机
- 对于读操作
- 当缓冲区由不可读变为可读的时候,即缓冲区由空变为不空的时候。
- 当有新数据到达时,即缓冲区中的待读数据变多的时候。
- 当缓冲区有数据可读,且应用进程对相应的描述符进行EPOLL_CTL_MOD 修改EPOLLIN事件时。
- 对于写操作
- 当缓冲区由不可写变为可写时。
- 当有旧数据被发送走,即缓冲区中的内容变少的时候。
- 当缓冲区有空间可写,且应用进程对相应的描述符进行EPOLL_CTL_MOD 修改EPOLLOUT事件时。
- 当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你。这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。
- 对于读操作
在ET模式下, 缓冲区从不可读变成可读,会唤醒应用进程,缓冲区数据变少的情况,则不会再唤醒应用进程。
举例1:
读缓冲区刚开始是空的
读缓冲区写入2KB数据
水平触发和边缘触发模式此时都会发出可读信号
收到信号通知后,读取了1KB的数据,读缓冲区还剩余1KB数据
水平触发会再次进行通知,而边缘触发不会再进行通知
举例2:(以脉冲的高低电平为例)水平触发:0为无数据,1为有数据。缓冲区有数据则一直为1,则一直触发。
边缘触发发:0为无数据,1为有数据,只要在0变到1的上升沿才触发。
JDK并没有实现边缘触发,Netty重新实现了epoll机制,采用边缘触发方式;另外像Nginx也采用边缘触发。
JDK在Linux已经默认使用epoll方式,但是JDK的epoll采用的是水平触发,而Netty重新实现了epoll机制,采用边缘触发方式,netty epoll transport 暴露了更多的nio没有的配置参数,如 TCP_CORK, SO_REUSEADDR等等;另外像Nginx也采用边缘触发。
epoll与select、poll的对比
-
用户态将文件描述符传入内核的方式
select:创建3个文件描述符集并拷贝到内核中,分别监听读、写、异常动作。这里受到单个进程可以打开的fd数量限制,默认是1024。
poll:将传入的struct pollfd结构体数组拷贝到内核中进行监听。
epoll:执行epoll_create会在内核的高速cache区中建立一颗红黑树以及就绪链表(该链表存储已经就绪的文件描述符)。接着用户执行的epoll_ctl函数添加文件描述符会在红黑树上增加相应的结点。 -
内核态检测文件描述符读写状态的方式
select:采用轮询方式,遍历所有fd,最后返回一个描述符读写操作是否就绪的mask掩码,根据这个掩码给fd_set赋值。
poll:同样采用轮询方式,查询每个fd的状态,如果就绪则在等待队列中加入一项并继续遍历。
epoll:采用回调机制。在执行epoll_ctl的add操作时,不仅将文件描述符放到红黑树上,而且也注册了回调函数,内核在检测到某文件描述符可读/可写时会调用回调函数,该回调函数将文件描述符放在就绪链表中。 -
找到就绪的文件描述符并传递给用户态的方式
select:将之前传入的fd_set拷贝传出到用户态并返回就绪的文件描述符总数。用户态并不知道是哪些文件描述符处于就绪态,需要遍历来判断。
poll:将之前传入的fd数组拷贝传出用户态并返回就绪的文件描述符总数。用户态并不知道是哪些文件描述符处于就绪态,需要遍历来判断。
epoll:epoll_wait只用观察就绪链表中有无数据即可,最后将链表的数据返回给数组并返回就绪的数量。内核将就绪的文件描述符放在传入的数组中,所以只用遍历依次处理即可。这里返回的文件描述符是通过mmap让内核和用户空间共享同一块内存实现传递的,减少了不必要的拷贝。 -
重复监听的处理方式
select:将新的监听文件描述符集合拷贝传入内核中,继续以上步骤。
poll:将新的struct pollfd结构体数组拷贝传入内核中,继续以上步骤。
epoll:无需重新构建红黑树,直接沿用已存在的即可。
epoll更高效的原因
-
select和poll的动作基本一致,只是poll采用链表来进行文件描述符的存储,而select采用fd标注位来存放,所以select会受到最大连接数的限制,而poll不会。
-
select、poll、epoll虽然都会返回就绪的文件描述符数量。但是select和poll并不会明确指出是哪些文件描述符就绪,而epoll会。造成的区别就是,系统调用返回后,调用select和poll的程序需要遍历监听的整个文件描述符找到是谁处于就绪,而epoll则直接处理即可。
-
select、poll都需要将有关文件描述符的数据结构拷贝进内核,最后再拷贝出来。而epoll创建的有关文件描述符的数据结构本身就存于内核态中,系统调用返回时利用mmap()文件映射内存加速与内核空间的消息传递:即epoll使用mmap减少复制开销。
-
select、poll采用轮询的方式来检查文件描述符是否处于就绪态,而epoll采用回调机制。造成的结果就是,随着fd的增加,select和poll的效率会线性降低,而epoll不会受到太大影响,除非活跃的socket很多。
epoll的边缘触发模式效率高,系统不会充斥大量不关心的就绪文件描述符
虽然epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。

