【Python】Scrapy入门1-新建爬虫到爬取内容
之前使用requests模块和BeautifulSoup来写爬虫,虽然可以实现想要的功能,但每次要从头开始,设置请求头--进入第一个链接--爬取这一页的进入具体信息条目的链接和进入下一页的链接--进入具体的信息条目的链接--爬取自己想要的内容--储存。
每次都需要重复的做这些操作,不免有些麻烦。
Scrapy框架就可以完美的解决这些问题,新建一个Scrapy项目之后,只需写几行代码就可以爬取一级界面,简单修改items.py(类似于JavaBean)之后,就可以爬取二级界面。
下载Scrapy,安装了pip之后对,对这些的管理更为方便,直接使用pip install Scrapy下载安装。
安装好之后,scrapy startproject example
在当前目录就会新建一个项目,如果需要在D盘的xx目录下新建项目,则在D盘的xx目录下打开控制台(或PowerShell)。
然后输入cd example进入该项目的目录
以这个练习爬虫的网站为例:
http://books.toscrape.com/
最简单的爬取一级界面(书籍信息,点开每个书籍,可以进入书的详情界面):
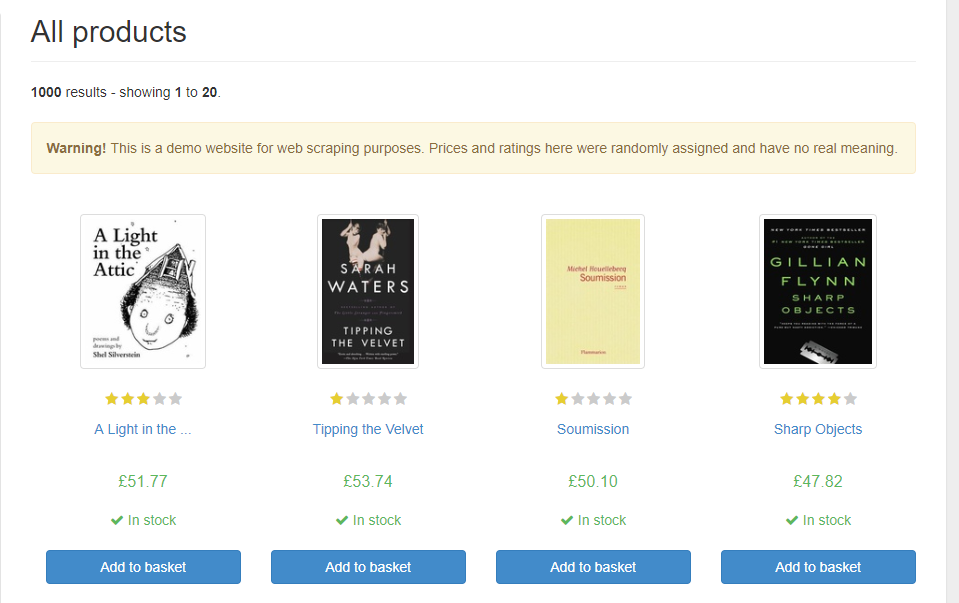
这时,对改站点新建一个爬虫,运行命令scrapy gen
这时,会根据你要爬取的网站生成一个爬虫
# -*- coding: utf-8 -*- import scrapy class ScrapebooksSpider(scrapy.Spider): name = 'scrapeBooks' allowed_domains = ['toscrape.com'] start_urls = ['http://books.toscrape.com/'] def parse(self, response): # 打印输出页面书籍名字的信息 self.log(response.xpath('//*[@id="default"]/div[1]/div/div/div/section/div[2]/ol/li/article/h3/a/text()').extract())
Xpath的获取通过Chrome的开发者工具,右键该元素,在copy选项里面有Copy Xpath,然后直接粘贴在response.xpath()中即可爬取该内容
self.log是在日志中打印信息
想要爬取二级界面:
在Item中设置两个字段,书名和书的简介:
class BooksItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() desc = scrapy.Field()
再在爬虫的文件中引用该Item:
from scrapy.http import Request from urllib import parse # 下方的为引用Item,ScrapyBooks为项目名,.items固定,BookItem见Items.py中定义的class后的名字 from ScrapeBooks.items import BooksItem
源码:
# -*- coding: utf-8 -*- import scrapy from scrapy.http import Request from urllib import parse from ScrapeBooks.items import BooksItem class ScrapebooksSpider(scrapy.Spider): name = 'manual' allowed_domains = ['toscrape.com'] start_urls = ['http://books.toscrape.com/'] def parse(self, response): # TODO 获取下一页的 URL 并提交到队列 next_selector = response.xpath('//li[@class=\'next\']/a/@href') for url in next_selector.extract(): yield Request(parse.urljoin(response.url,url)) # TODO 获取详情的 URL 提交到队列 item_seletor = response.xpath('//*[@id="default"]/div[1]/div/div/div/section/div[2]/ol/li[1]/article/h3/a/@href') for url in item_seletor.extract(): yield Request(parse.urljoin(response.url, url), callback=self.parse_item) def parse_item(self, response): # TODO 获取相应Item 获取名字 book = BooksItem() book['title'] = response.xpath('//h1/text()').extract() book['desc'] = response.xpath('//*[@id="content_inner"]/article/p/text()').extract() return book
只是爬取了,还并未储存,简单的储存,可以在运行爬虫的时候输入打印为csv,json,jl等格式
scrapy crawl example -o items.jl 即可输出到items.jl文件中
scrapy crawl example -s COLSESPIDER_ITEMCOUNT=90 即可设置爬取一定的数量就停止爬虫
更快速的双向爬虫方式
如果懂了前一种方式,这种简化的方式就非常容易理解了。
scrapy genspider -t crawl CrawlBooks books.toscrape.com
输入以上命令可以快速的继承crawl生成一个双向爬虫。不再是继承spider。
仔细观察,生成的没有parse方法,只有parse_item方法。
代码中的LinkExtractor是为了专门用来提取href中的链接的。因此正则表达式不需要在最后输入@href。
源代码:
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from ScrapeBooks.items import BooksItem class CrawlbooksSpider(CrawlSpider): name = 'CrawlBooks' allowed_domains = ['books.toscrape.com'] start_urls = ['http://books.toscrape.com/'] rules = ( Rule(LinkExtractor(restrict_xpaths= '//li[@class=\'next\']')), Rule(LinkExtractor(restrict_xpaths= '//*[@id="default"]/div[1]/div/div/div/section/div[2]/ol/li[1]/article/h3'), callback='parse_item') ) def parse_item(self, response): book = BooksItem() book['title'] = response.xpath('//h1/text()').extract() book['desc'] = response.xpath('//*[@id="content_inner"]/article/p/text()').extract() return book
CrawlSpider中的Rule参数有如下:
''' LinkExtractor : 设置提取链接的规则(正则表达式) allow=(), : 设置允许提取的url restrict_xpaths=(), :根据xpath语法,定位到某一标签下提取链接 restrict_css=(), :根据css选择器,定位到某一标签下提取链接 deny=(), : 设置不允许提取的url(优先级比allow高) allow_domains=(), : 设置允许提取url的域 deny_domains=(), :设置不允许提取url的域(优先级比allow_domains高) unique=True, :如果出现多个相同的url只会保留一个 strip=True :默认为True,表示自动去除url首尾的空格 ''' ''' rule link_extractor, : linkExtractor对象 callback=None, : 设置回调函数 follow=None, : 设置是否跟进 process_links=None, :可以设置回调函数,对所有提取到的url进行拦截 process_request=identity : 可以设置回调函数,对request对象进行拦截 '''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号