
windows下在pycharm中开发pyspark的环境配置
1、安装pyspark
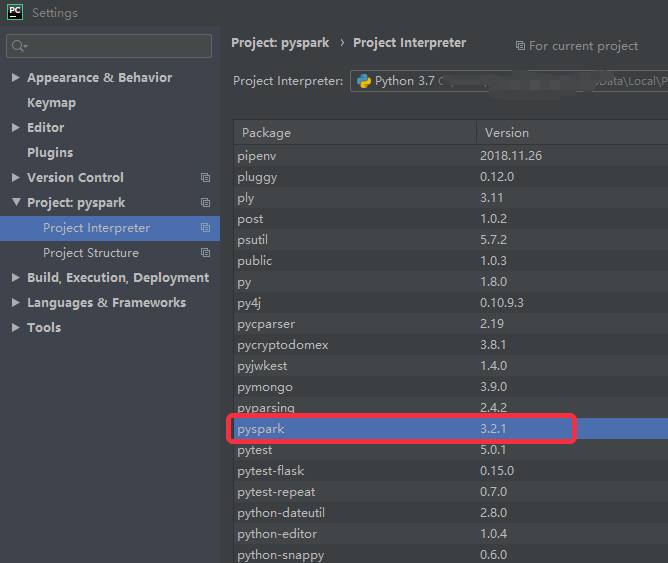
2、下载想要的hadoop版本,解决 missing WINUTILS.EXE 的问题
下载地址:https://github.com/steveloughran/winutils
比如,我保存的本地地址在这
3、pyspark程序中指定系统变量
from pyspark import SparkContext
import os
import sys
#指定系统变量
if sys.platform == "linux":
os.environ["PYSPARK_PYTHON"] = "/home/xxxxx/anaconda3/bin/python3.7"
os.environ["HADOOP_HOME"] = "/usr/bin/hadoop"
else:
os.environ["PYSPARK_PYTHON"]="C:\\Users\\xxxxxx\\AppData\\Local\\Programs\\Python\\Python37\\python.exe"
os.environ["HADOOP_HOME"]="E:\\pycharm-project\\winutils-master\\hadoop-2.6.0"
logFile = "test.txt"
sc = SparkContext("local","my first app")
sc.setLogLevel("ERROR")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'projtrtr' in s).count()
numBs = logData.filter(lambda s: 'd' in s).count()
temp = logData.first()
print(temp)
print("Lines with projtrtr: %i, lines with d: %i"%(numAs, numBs))
4、此时在pycharm中编写pyspark程序的配置就完成了
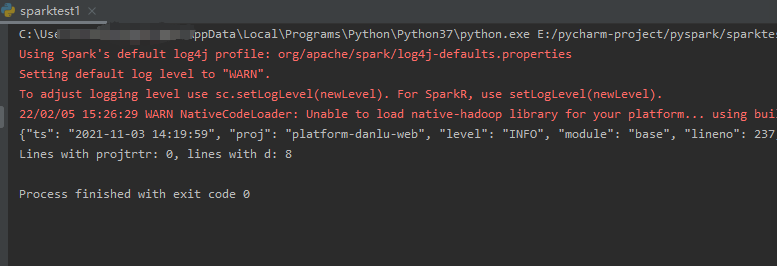
上述demo的运行结果:

参考:https://cwiki.apache.org/confluence/display/HADOOP2/WindowsProblems

 浙公网安备 33010602011771号
浙公网安备 33010602011771号