7.逻辑回归实践
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
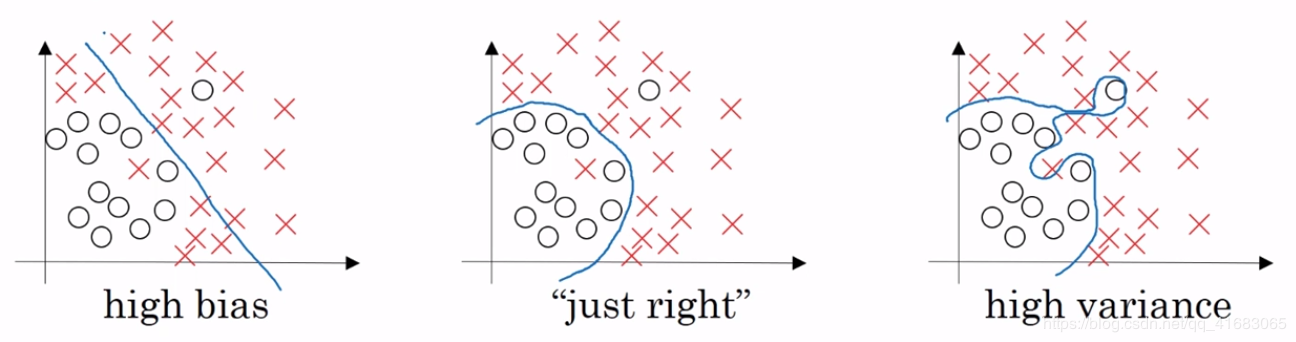
过拟合问题产生的原因便是数据量太少,而变量过多,导致虽然能够拟合所有的数据,但是曲线比较曲折。我们从以下几个方面防止过拟合:在数据层面,加大样本量;通过特征选择减少特征量。在算法层面,引入正则化。正则化可以提高泛化能力,如果正则化参数设置得足够大,权重矩阵被设置为接近于0的值,直观理解就是把多隐藏单元的权重设为0,于是基本上消除了这些隐藏单元的许多影响。如果是这种情况,这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是网络深度却很深,它会使这个网络从过度拟合的状态更接近高偏差状态。但是会存在一个中间值,于是会有一个接近“Just Right”的中间状态。

2.用logiftic回归来进行实践操作,数据不限。
使用逻辑回归算法预测学生是否被高校录取
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report import pandas as pd #1、加载数据集 data=pd.read_csv('./data/LogisticRegression.csv') x_data=data.iloc[:,1:] y_data=data.iloc[:,0] #2、划分训练集和测试集 x_train,x_test,y_train,y_test=train_test_split(x_data,y_data,test_size=0.2,random_state=5) #3、构建模型并训练模型 model_LR=LogisticRegression() model_LR.fit(x_train,y_train) #4、模型预测 y_pre=model_LR.predict(x_test) print('预测的录取情况:',y_pre) print('真实的录取情况:',y_test) print('分类报告:\n',classification_report(y_test,y_pre)) print('逻辑回归的准确率为:{0:.2f}%'.format(model_LR.score(x_test,y_test)*100))
运行结果:
预测的录取情况: [0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0] 真实的录取情况: 218 0 191 0 117 0 50 0 348 0 .. 184 0 140 0 107 0 241 1 48 0 Name: admit, Length: 80, dtype: int64 分类报告: precision recall f1-score support 0 0.68 0.93 0.79 54 1 0.43 0.12 0.18 26 accuracy 0.66 80 macro avg 0.56 0.52 0.48 80 weighted avg 0.60 0.66 0.59 80 逻辑回归的准确率为:66.25%
