3.K均值算法
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
第一次分类:

第二次分类,之后不断进行分类,直到中心不再改变为止

2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
import numpy as np
from sklearn.datasets import load_iris
#引入鸢尾花数据集
iris=load_iris()
x=iris.data[:,1]
y=np.zeros(150)
def initcent(x,k): #初始聚类中心数组
return x[0:k].reshape(k)
def nearest(kc,i): #数组中的值,与聚类中心最小距离所在类别的索引号
d=(abs(kc-i))
w=np.where(d==np.min(d))
return w[0][0]
def kcmean (x,y,kc,k): #计算各聚类新均值
l=list(kc)
flag=False
for c in range(k):
m=np.where(y==c)
n=np.mean(x[m])
if l[c] !=n:
l[c]=n
flag=True #聚类中心发生变化
return (np.array(l),flag)
def xclassify(x,y,kc):
for i in range (x.shape[0]): #对数组的每个值分类
y[i]=nearest(kc,x[i])
return y
k=3
kc=initcent(x,k)
flag = True
print(x,y,kc,flag)
while flag:
y = xclassify(x,y,kc)
kc,flag = kcmean(x,y,kc,k)
print(y,kc,type(kc))

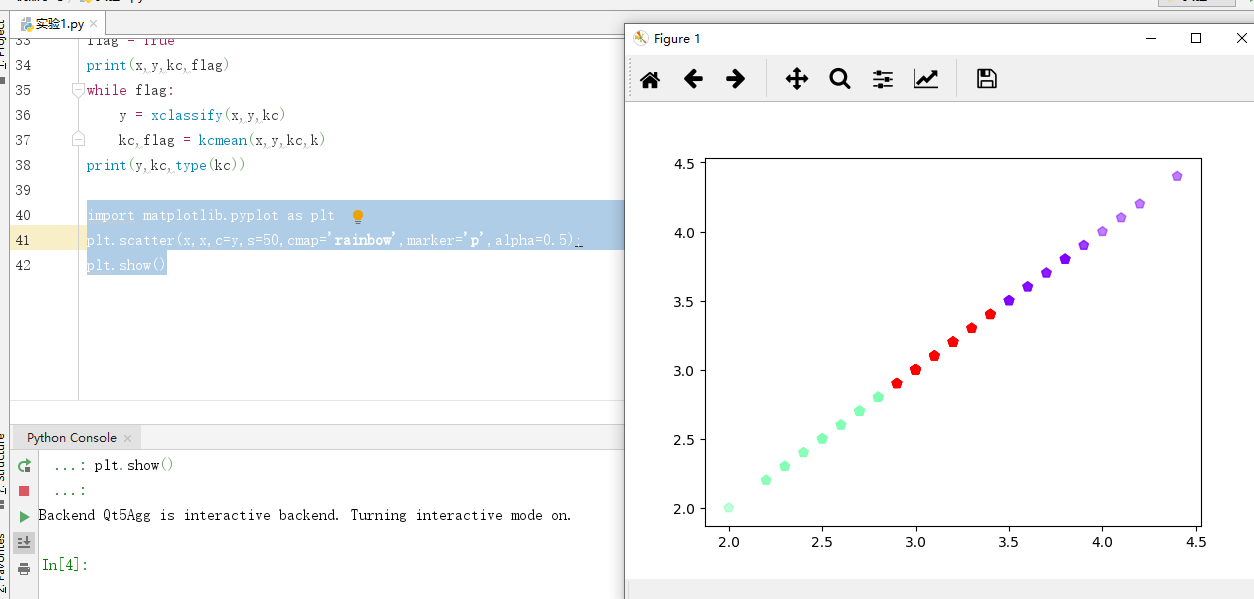
绘制散点图
import matplotlib.pyplot as plt
plt.scatter(x,x,c=y,s=50,cmap='rainbow',marker='p',alpha=0.5);
plt.show()
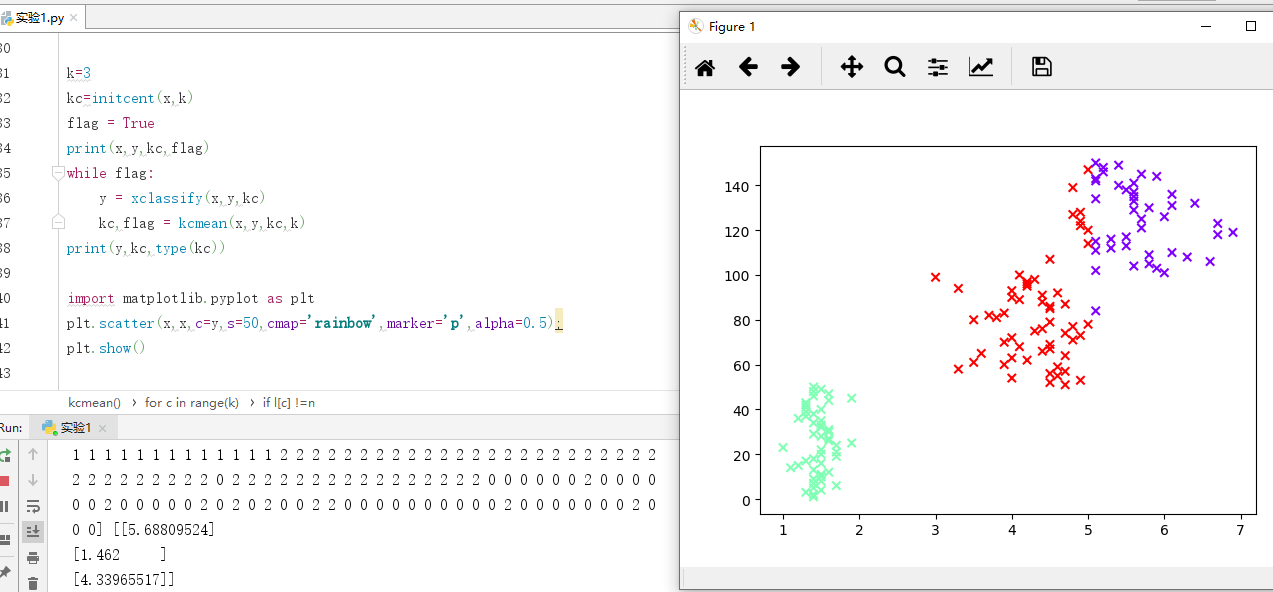
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
# 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类并用散点图显示.
data=load_iris()
data_length=data['data'][:,2:3]#取出鸢尾花花瓣的长度
x=data_length
#y=np.zeros(x.shape[0])
k1=KMeans(n_clusters=3)#将其类别分为3类
k1.fit(x)
kc1=k1.cluster_centers_
y_kmeans=k1.predict(x)#预测每个样本的聚类索引
print(y_kmeans,kc1)
plt.scatter(x,np.linspace(1,150,150),c=y_kmeans,marker='x',cmap='rainbow',linewidths=4)
plt.show()
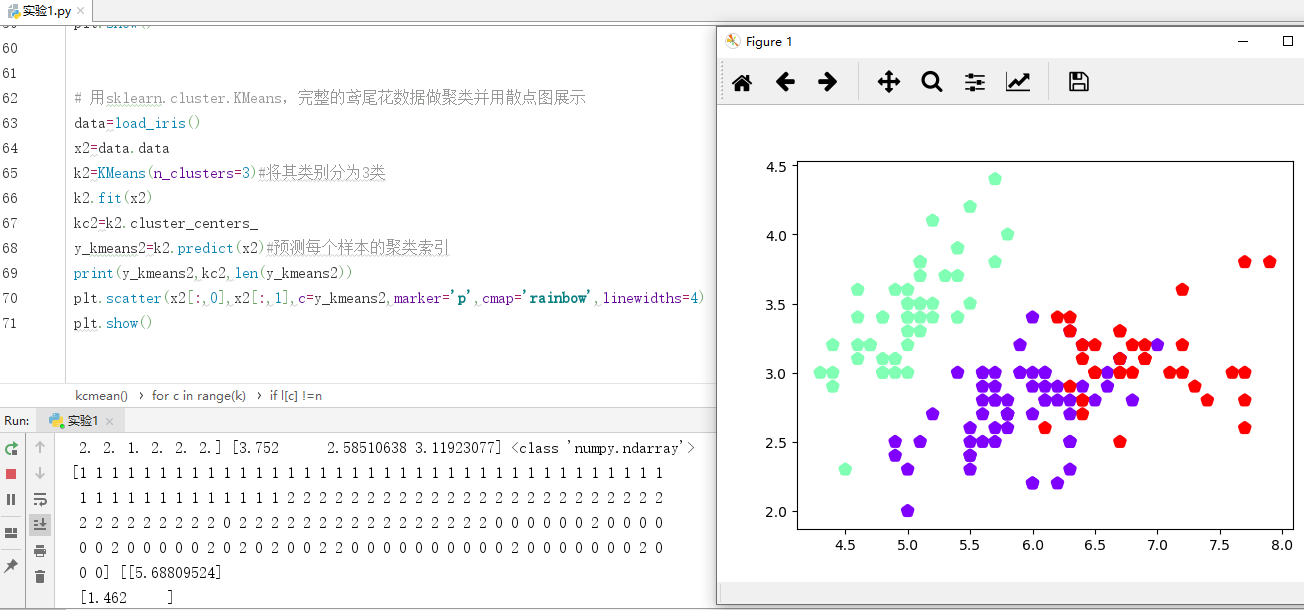
4). 鸢尾花完整数据做聚类并用散点图显示.
# 用sklearn.cluster.KMeans,完整的鸢尾花数据做聚类并用散点图展示
data=load_iris()
x2=data.data
k2=KMeans(n_clusters=3)#将其类别分为3类
k2.fit(x2)
kc2=k2.cluster_centers_
y_kmeans2=k2.predict(x2)#预测每个样本的聚类索引
print(y_kmeans2,kc2,len(y_kmeans2))
plt.scatter(x2[:,0],x2[:,1],c=y_kmeans2,marker='p',cmap='rainbow',linewidths=4)
plt.show()
5).想想k均值算法中以用来做什么?
我们可以利用K均值算法实现图像压缩、图像分割、以及聚类分析。我们日常生活中,实际应用的例子有处理图片时压缩图片,在医疗中按照算法将局部的图像分割开,在比赛自动分组中实现队伍的划分,将能力相近的队伍分为同一小组。

