【推荐算法】数据集处理
ml-100k
MovieLens 100K movie ratings. Stable benchmark dataset. 100,000 ratings from 1000 users on 1700 movies. Released 4/1998.
包含文件
- u.data:943个用户对1682个电影的100000条评分。
| 列名 | user_id | item_id | rating | timestamp |
|---|---|---|---|---|
| 数据范围 | 1~943 | 1~1682 | 1~5 | 874724710~893286638 |
- u.genre:19种体裁。
| 列名 | genre | genre_id |
|---|---|---|
| 数据范围 | 例:Action、Sci-Fi | 0~18 |
- u.item:电影具体信息。
| 列名 | item_id | item_name | release_date | IMDb_URL | genre |
|---|---|---|---|---|---|
| 数据范围 | 1~1682 | 例:Toy Story (1995) | 例:01-Jan-1995 | URL | 例:0001110000000000000 |
- u.user:用户信息。
| 列名 | user_id | age | gender | occupation | zip_code |
|---|---|---|---|---|---|
| 数据范围 | 1~943 | 7~73 | 男、女 | 例:technician、writer | 例:85711、02215 |
前处理
输入网络的特征可以分为三个大类:
- token类特征: 不同取值较少(low-cardinality)或ID类特征,本数据集使用user_id、item_id、release_date、age、gender、occupation。
- float类特征: 不同取值较多(high-cardinality)或连续特征,本数据集使用timestamp。
- seq类特征: 序列或multi-hot类特征,本数据集使用genre。
具体的代码为:
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
def ml100k_prepocess():
data_csv = 'dataset/ml-100k/u.data'
user_csv = 'dataset/ml-100k/u.user'
item_csv = 'dataset/ml-100k/u.item'
le = LabelEncoder()
mms = MinMaxScaler()
# u.data
data_df = pd.read_csv(data_csv, sep='\t', header=None)
data_df.columns = ['user_id', 'item_id', 'label', 'timestamp']
data_df['label'] = (data_df['label'] > 3).astype(int)
data_df['timestamp'] = mms.fit_transform(data_df['timestamp'].values.reshape(-1, 1))
# u.user
user_df = pd.read_csv(user_csv, sep='|', header=None)
user_df.columns = ['user_id', 'age', 'gender', 'occupation', 'zip_code']
user_df.drop(columns='zip_code', inplace=True)
# u.item
item_df = pd.read_csv(item_csv, sep='|', header=None, encoding='latin-1')
seq_len = item_df[range(5,24)].sum(axis=1).max()
def func(x):
genre = list(np.where(x.iloc[5:].values)[0])
genre.extend([0] * (seq_len - len(genre)))
return genre
item_df = pd.read_csv(item_csv, sep='|', header=None, encoding='latin-1')
item_df['genre'] = item_df.apply(func, axis=1)
item_df.drop(columns=[1, *range(3, 24)], inplace=True)
item_df.columns = ['item_id', 'release_year', 'genre']
fill_na = item_df['release_year'].mode()[0][-4:]
item_df['release_year'] = item_df['release_year'].apply(lambda x: x[-4:] if pd.notnull(x) else fill_na).astype(int)
# merge
df = data_df.merge(user_df, on='user_id', how='left').merge(item_df, on='item_id', how='left')
df = df.sort_values(by=['user_id', 'timestamp'], ascending=[1, 1]).reset_index(drop=True)
token_col = ['user_id', 'item_id', 'age', 'gender', 'occupation', 'release_year']
for i in token_col:
df[i] = le.fit_transform(df[i])
return df
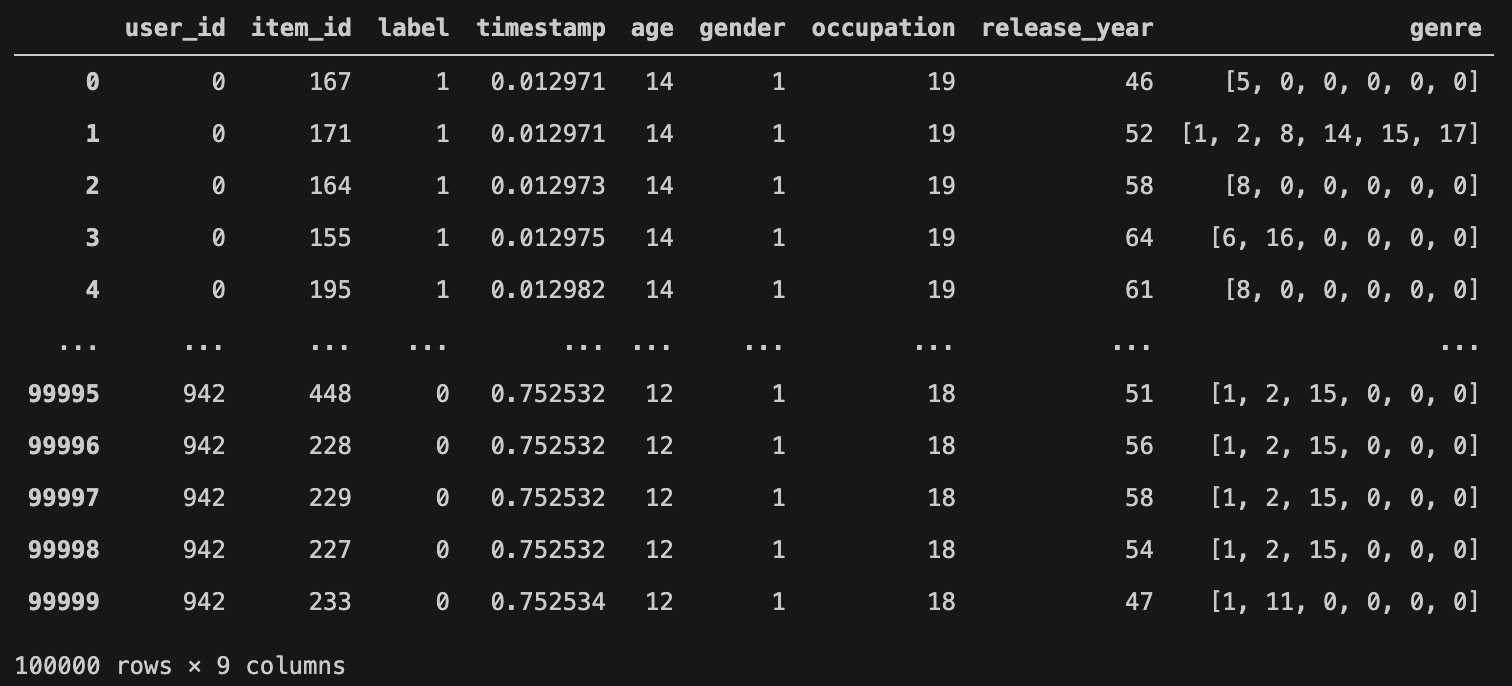
df即处理后的数据集:
数据集划分
我们将数据集划分为train、validate、test三部分。为避免特征穿越,我们按时间排序,将每个用户前80%作为train,后10%作为validate,最后10%作为test。
def dataset_split(df, val_test_ratio=0.1):
train_idx = []
val_idx = []
test_idx = []
for i in df['user_id'].unique():
df_tmp = df[df['user_id'] == i]
cnt = df_tmp.shape[0]
val_test_cnt = int(cnt * val_test_ratio)
train_cnt = cnt - 2 * val_test_cnt
idx = df_tmp.index.tolist()
train_idx.extend(idx[: train_cnt])
val_idx.extend(idx[train_cnt : train_cnt + val_test_cnt])
test_idx.extend(idx[train_cnt + val_test_cnt :])
train_df = df.iloc[train_idx].reset_index(drop=True)
val_df = df.iloc[val_idx].reset_index(drop=True)
test_df = df.iloc[test_idx].reset_index(drop=True)
return train_df, val_df, test_df

 浙公网安备 33010602011771号
浙公网安备 33010602011771号