
第二周作业
1. 总结学过的文本处理工具,文件查找工具,文本处理三剑客, 文本格式化命令(printf)的相关命令及选项,示例。
文本处理工具
cat:查看文件内容
格式:cat [OPTION]… [FILE]…
常见选项:

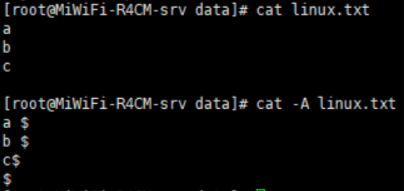
nl:相当于cat -b用于显示行号
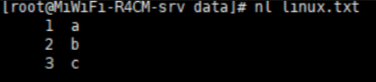
tac:逆向显示文本内容
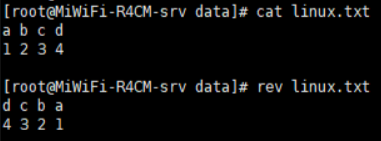
rev:将同一行内容逆向显示
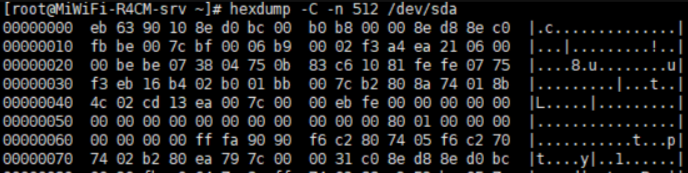
hexdump:查看非文本文件内容
less:实现分页显示内容

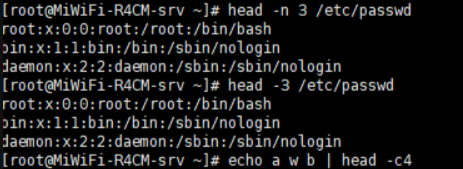
head:显示文本前面或后面的行内容
格式:head [OPTION]… [FILE]…
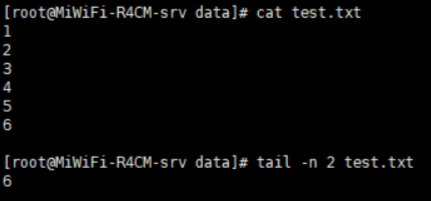
tail:查看文件或标准输入的倒数行
格式:tail [OPTION]… [FILE]…
cut:按列抽取文本
格式:cut [OPTION]… [FILE]…
常用选项:


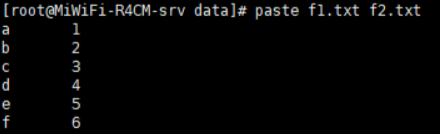
paste:合并多个文件
格式:paste [OPTION]… [FILE]…
常用选项:
-d #分隔符:指定分隔符,默认用TAB
-s #所有行合成一行显示
wc:收集文本统计数据

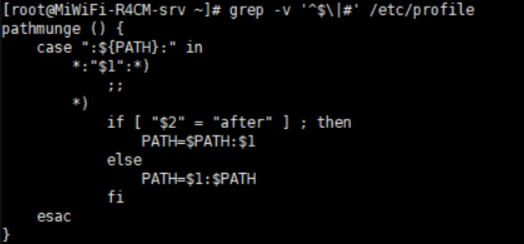
在这里插入图片描述
sort:文本排序
格式:sort [options] file(s)
常用选项:
-r 执行反方向(由上至下)整理
-R 随机排序
-n 执行按数字大小整理
-h 人类可读排序,如: 2K 1G
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique),合并重复项,即去重
-t c 选项使用c做为字段界定符
-k # 选项按照使用c字符分隔的 # 列来整理能够使用多次

文件查找工具
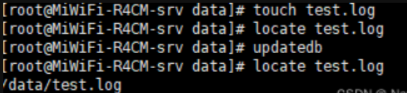
locate:非实时查找(数据库查找)
格式:locate [OPTION]… [PATTERN]…
常用选项:
-i 不区分大小写的搜索
-n N 只列举前N个匹配项目
-r 使用基本正则表达式
find:实时查找
格式:find [OPTION]… [查找路径] [查找条件] [处理动作]
工作特点:
查找速度略慢
精确查找
实时查找
查找条件丰富
可能只搜索用户具备读取和执行权限的目录
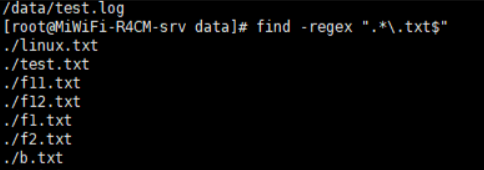
根据文件名查找:
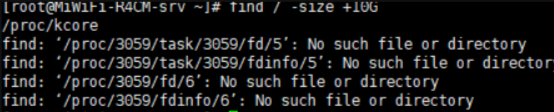
根据文件大小来找:
文本处理三剑客
grep 命令主要对文本的(正则表达式)行基于模式进行过滤
sed:stream editor,文本编辑工具
awk:Linux上的实现gawk,文本报告生成器
文本处理三剑客之 grep
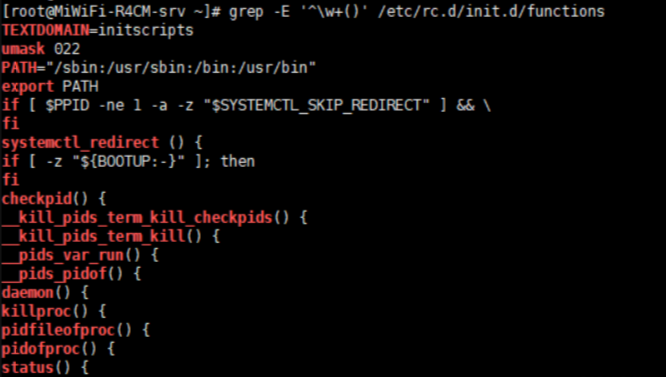
格式:grep [OPTIONS] PATTERN [FILE…]
常见选项:-
-color=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行,即取反
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ’ -e ‘dog’ file
-w 匹配整个单词
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-P 支持Perl格式的正则表达式
-f file 根据模式文件处理
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接

分区利用率最大值

文本处理三剑客之sed
格式:sed [option]… ‘script;script;…’ [inputfile…]
常用选项:
-n 不输出模式空间内容到屏幕,即不自动打印
-e 多点编辑
-f FILE 从指定文件中读取编辑脚本
-r, -E 使用扩展正则表达式
-i.bak 备份文件并原处编辑
-s 将多个文件视为独立文件,而不是单个连续的长文件流
默认sed将输入信息直接输出
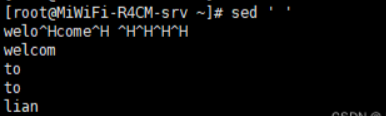
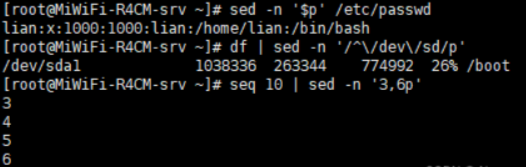
显示前10行
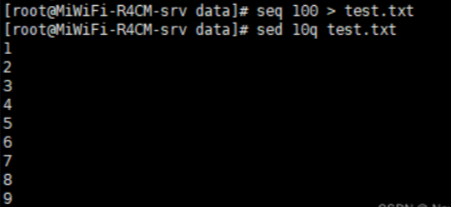
文本处理三剑客之 awk
awk:报告生成器,格式化文本输出
格式:
awk [options] ‘program’ var=value file…
awk [options] -f programfile var=value file…
常见选项:
-F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符
-v var=value 变量赋值
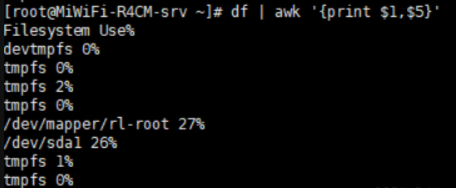
取出分区利用率
提取“.magedu.com”前面的主机名部分并写入到文件中

printf 可以实现格式化输出
格式:printf “FORMAT”, item1, item2, …

2. 总结文本处理的grep命令相关的基本正则和扩展正则表达式。
基本正则表达式
字符匹配
. 匹配任意单个字符(除了\n),可以是一个汉字或其它国家的文字
[] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z]
[^] 匹配指定范围外的任意单个字符,示例:[^wang]
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
**[:punct:] 标点符号
\s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\r\t\v]。注意 Unicode
正则表达式会匹配全角空格符
\S #匹配任何非空白字符。等价于 [^\f\r\t\v]
\w #匹配一个字母,数字,下划线,汉字,其它国家文字的字符,等价于[[:alnum:]字]
\W #匹配一个非字母,数字,下划线,汉字,其它国家文字的字符,等价于[[1]字
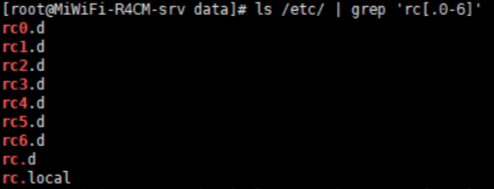
匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
#匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
. #任意长度的任意字符
? #匹配其前面的字符出现0次或1次,即:可有可无
+#匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
{n} #匹配前面的字符n次
{m,n} #匹配前面的字符至少m次,至多n次
{,n} #匹配前面的字符至多n次,<=n
{n,} #匹配前面的字符至少n次

匹配次数

位置锚定
可以用于定位出现的位置
^ #行首锚定, 用于模式的最左侧
$ #行尾锚定,用于模式的最右侧
^PATTERN$ #用于模式匹配整行
^$ #空行
<或\b #词首锚定,用于单词模式的左侧
*>或\b #词尾锚定,用于单词模式的右侧
*
注意: 单词是由字母,数字,下划线组成
扩展正则表达式字符匹配
. 任意单个字符
[wang] 指定范围的字符
[^wang] 不在指定范围的字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
3. 总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用。
变量命名要求
- 区分大小写
- 不能使程序中的保留字和内置变量:如:if, for
- 只能使用数字、字母及下划线,且不能以数字开头,注意:不支持短横线 “ - ”,和主机名相反
环境变量
- 可以使子进程(包括孙子进程)继承父进程的变量,但是无法让父进程使用子进程的变量
- 一旦子进程修改从父进程继承的变量,将会新的值传递给孙子进程
- 一般只在系统配置文件中使用,在脚本中较少使用
声明并赋值
- export name=VALUE
- declare -x name=VALUE
或者分两步实现
- name=VALUE
- export name
变量引用
$name
n a m e ∗ ∗ 显示所有环境变量: ∗ ∗ e n v p r i n t e n v e x p o r t d e c l a r e − x 查看指定进程的环境变量 c a t / p r o c / {name} 显示所有环境变量: env printenv export declare -x 查看指定进程的环境变量 cat /proc/name∗∗显示所有环境变量:∗∗envprintenvexportdeclare−x查看指定进程的环境变量cat/proc/PID/environ
删除变量
unset name
只读变量
只能声明定义,但后续不能修改和删除,即常量
声明只读变量:
readonly name
declare -r name
查看只读变量:
readonly [-p]
declare -r

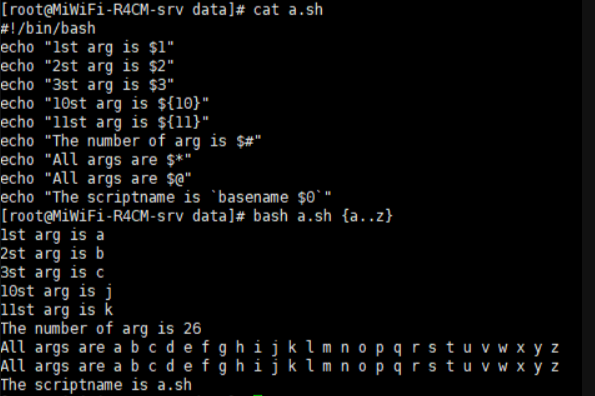
位置变量
在bash shell中内置的变量, 在脚本代码中调用通过命令行传递给脚本的参数
- 1, $2, … 对应第1个、第2个等参数,shift [n]换位置
- $0 命令本身,包括路径
- $* 传递给脚本的所有参数,全部参数合为一个字符串
- $@ 传递给脚本的所有参数,每个参数为独立字符串
- KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲ 传递给脚本的参数的个数 注意…@ $* 只在被双引号包起来的时候才会有差异
清空所有位置变量
set –
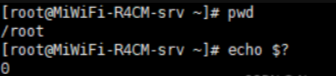
退出状态码变量
- 进程执行后,将使用变量 ? 保存状态码的相关数字,不同的值反应成功或失败, ? 保存状态码的相关数字,不同的值反应成功或失败,?保存状态码的相关数字,不同的值反应成功或失败,?取值范例 0-255
- $?的值为0 #代表成功
- $?的值是1到255 #代表失败

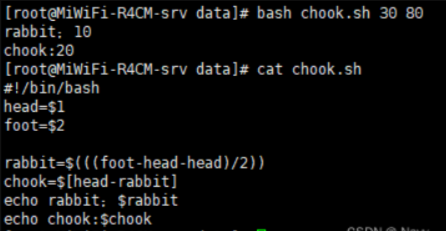
4. 通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?
5. 结合编程的for循环,条件测试,条件组合,完成批量创建100个用户,
1)for遍历1..100
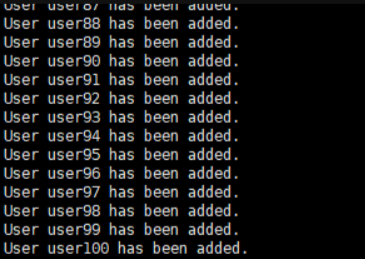
2)先id判断是否存在
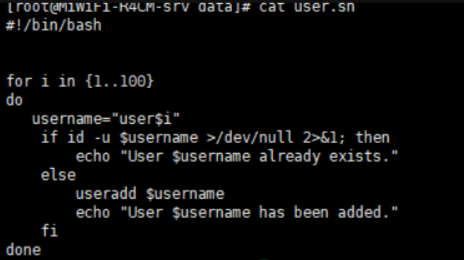
3)用户存在则说明存在,用户不存在则添加用户并说明已添加。

6. 磁盘存储术语总结: head, track, sector, sylinder.
- Head(磁头):磁头是用来读取和写入数据的关键部件。它附着在机械臂上,可以移动到磁盘的不同部分。每个磁头都可以独立地读取和写入数据,但在同一时间内,只有一个磁头可以访问给定的轨道。
- Track(磁道):磁道是磁盘上的一组同心圆,其中每一个都由一个磁头进行访问。这些磁道被组织成多个扇区,每个扇区包含一定数量的数据位。
- Sector(扇区):扇区是磁盘上最小的数据存储单元。每个扇区通常包含一个标识符(ID),用于识别该扇区,以及实际的数据。扇区的大小通常为512字节,但现代磁盘通常使用4KB的扇区大小。
- Cylinder(柱面):柱面是由同一磁道上的所有扇区组成的。在早期的硬盘驱动器中,磁头在访问同一柱面中的所有扇区时是不需要移动的。然而,现代硬盘驱动器使用旋转速度更快的磁盘和更先进的磁头技术,使得访问同一柱面中的不同扇区也需要移动磁头
7. 总结MBR,GPT结构。
- MBR(Master Boot Record)和GPT(GUID Partition Table)都是磁盘分区表,用于管理和描述磁盘分区。
- MBR是一个位于磁盘最开始的扇区,它记录了磁盘分区表的信息,包括分区的数量、大小和类型等。MBR通常只能容纳4个主分区,如果需要更多的分区,需要在扩展分区中创建逻辑分区。MBR的大小是固定的,为512字节。
- GPT是一个基于UEFI(Unified Extensible Firmware Interface)的磁盘分区表,它使用GUID(Globally Unique Identifier)作为分区的标识符。GPT可以容纳更多的分区,并且可以支持更大的磁盘容量。GPT的第一个扇区是GPT头,其中包含了磁盘分区表的信息,以及一个签名(GUID)来验证GPT表的完整性。GPT的分区表位于GPT头之后,每个分区都有一个GUID和一个类型(如系统、数据、恢复等)。GPT的大小不是固定的,可以根据磁盘的大小动态调整。
8. 总结学过的分区,文件系统管理,SWAP管理相关的命令及选项,示例fdisk, parted, mkfs, tune2fs, xfs_info, fsck, mount, umount, swapon, swapoff
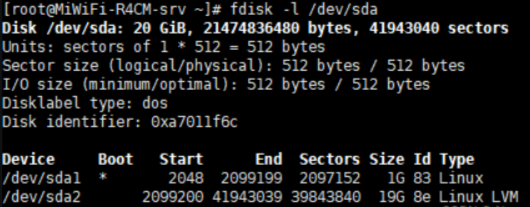
fdisk:用于创建、删除和修改磁盘分区。
常用选项:
-d:显示磁盘分区表信息。
-l:列出磁盘分区信息。
-n:创建一个新的分区。
-delete:删除一个分区。
-help:显示帮助信息。
-w:保存分区表更改
列出磁盘sda的分区信息
parted:类似于fdisk,可用于创建、删除和调整分区。
常用选项:
-l:列出磁盘分区表信息。
-i:显示磁盘分区详细信息。
-d:删除一个分区。
-n:创建一个新的分区。
列出磁盘分区表信息
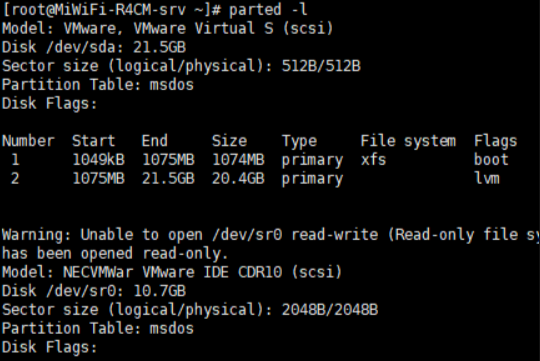
文件系统管理
mkfs:用于在磁盘分区上创建文件系统。
常用选项:
-t 文件系统类型:指定要创建的文件系统类型,如ext4、XFS等。
-L 标签:为文件系统指定一个标签
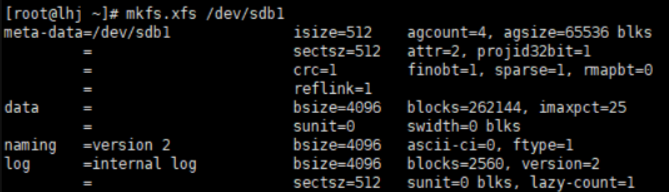

tune2fs
重新设定ext系列文件系统可调整参数的值

xfs_info
显示已挂载的xfs文件系统信息
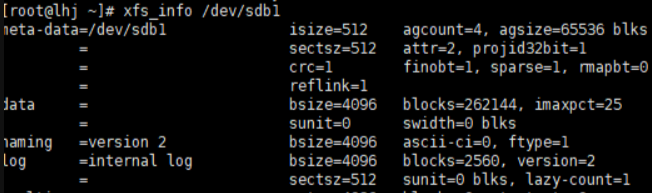
mount
挂载文件系统
格式:
mount [-lhV]
mount -a [options]
mount [options] [–source] | [–target]
mount [options]
mount []
常用命令选项
-a|–all #自动挂载所有支持自动挂载的设备(定义在了/etc/fstab
文件中,且挂载选项中有auto功能)
-B|–bind #绑定目录到另一个目录上
-c|–no-canonicalize #不对路径规范化
-f|–fake #空运行;跳过 mount(2) 系统调用
-F|–fork #对每个设备禁用 fork,配合-a 选项一起使用
-T|–fstab path #指定写文件,默认 /etc/fstab
-i|–internal-only #不调用 mount. 辅助程序
-l|–show-labels #显示文件系统的 labels
-n|–no-mtab #不更新/etc/mtab,mount不可见
-o|–options o1,o2 #挂载选项列表,以英文逗号分隔
-O|–test-opts o1,o2 #限制文件系统集合(和 -a 选项一起使用)
-r|–read-only #以只读方式挂载文件系统(同 -o ro)
-t|–types #指定要挂载的设备上的文件系统类型,如:ext4,xfs
–source device #指明源(路径、标签、uuid)
–target mountpoint #指明挂载点
-v|–verbose #显示过程
-w|–rw|–read-write #以读写方式挂载文件系统(默认)
-L LABEL #以卷标指定挂载设备

umount
卸载时:可使用设备,也可以使用挂载点

swapon用于激活交换分区(SWAP)

swapoff
用于关闭或禁用Linux系统中的交换空间
swapoff -a
:alnum: ↩︎
