
第二章 数据解析
第二章 数据解析
2.1 re 解析
2.1.1 re解析
Regular Expression, 正则表达式, ⼀种使⽤表达式的⽅式对字符串 进⾏匹配的语法规则。
正则的语法: 使⽤元字符进⾏排列组合⽤来匹配字符串 在线测试正 则表达式https://tool.oschina.net/regex/
元字符: 具有固定含义的特殊符号
常用元字符:
. 匹配除换⾏符以外的任意字符
\w 匹配字⺟或数字或下划线
\s 匹配任意的空⽩符
\d 匹配数字
\n 匹配⼀个换⾏符
\t 匹配⼀个制表符
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配⾮字⺟或数字或下划线
\D 匹配⾮数字
\S 匹配⾮空⽩符
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示⼀个组
[...] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符
量词: 控制前⾯的元字符出现的次数。
* 重复零次或更多次
+ 重复⼀次或更多次
? 重复零次或⼀次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
贪婪匹配和惰性匹配:
.* 贪婪匹配
.*? 惰性匹配 # 爬虫中使用最多的匹配方式
例:
str: 玩⼉吃鸡游戏, 晚上⼀起上游戏, ⼲嘛呢? 打游戏啊
reg: 玩⼉.*?游戏
此时匹配的是: 玩⼉吃鸡游戏
reg: 玩⼉.*游戏
此时匹配的是: 玩⼉吃鸡游戏, 晚上⼀起上游戏, ⼲嘛呢? 打游戏
str: <div>胡辣汤</div>
reg: <.*>
结果: <div>胡辣汤</div>
str: <div>胡辣汤</div>
reg: <.*?>
结果:
<div>
</div>
str: <div>胡辣汤</div><span>饭团</span>
reg: <div>.*?</div>
结果:
<div>胡辣汤</div>
2.1.2 re模块
1.findall 查找所有. 返回list
lst = re.findall("m", "mai le fo len, mai nimei!")
print(lst) # ['m', 'm', 'm']
lst = re.findall(r"\d+", "5点之前. 你要给我5000万")
print(lst) # ['5', '5000']
2.search 会进⾏匹配. 但是如果匹配到了第⼀个结果. 就会返回这 个结果. 如果匹配不上search返回的则是None.
ret = re.search(r'\d', '5点之前. 你要给我5000万').group()
print(ret) # 5
3.match 只能从字符串的开头进⾏匹配
ret = re.match('a', 'abc').group()
print(ret) # a
4.finditer, 和findall差不多. 只不过这时返回的是迭代器(重点)
it = re.finditer("m", "mai le fo len, mai nimei!")
for el in it:
print(el.group()) # 依然需要分组
5.compile() 可以将⼀个⻓⻓的正则进⾏预加载. ⽅便后⾯的使⽤
obj = re.compile(r'\d{3}') # 将正则表达式编译成为⼀个正则表达式对象, 规则要匹配的是3个数字
ret = obj.search('abc123eeee') # 正则表达式对象调⽤search, 参数为待匹配的字符串
print(ret.group()) # 结果: 123
6.正则中的内容如何单独提取? 单独获取到正则中的具体内容可以给分组起名字
s = """
<div class='⻄游记'><span id='10010'>中国联通
</span></div>
"""
obj = re.compile(r"<span id='(?P<id>\d+)'>(?P<name>\w+)</span>", re.S)
result = obj.search(s)
print(result.group()) # 结果: <spanid='10010'>中国联通</span>
print(result.group("id")) # 结果: 10010 # 获取id组的内容
print(result.group("name")) # 结果: 中国联通 #获取name组的内容
这⾥可以看到我们可以通过使⽤分组. 来对正则匹配到的内容进 ⼀步的进⾏筛选.
2.1.3 实例一:爬取豆瓣电影排行版前25信息
⽬标: 抓取"电影名称","上映年份","评分","评分⼈数"四项内容
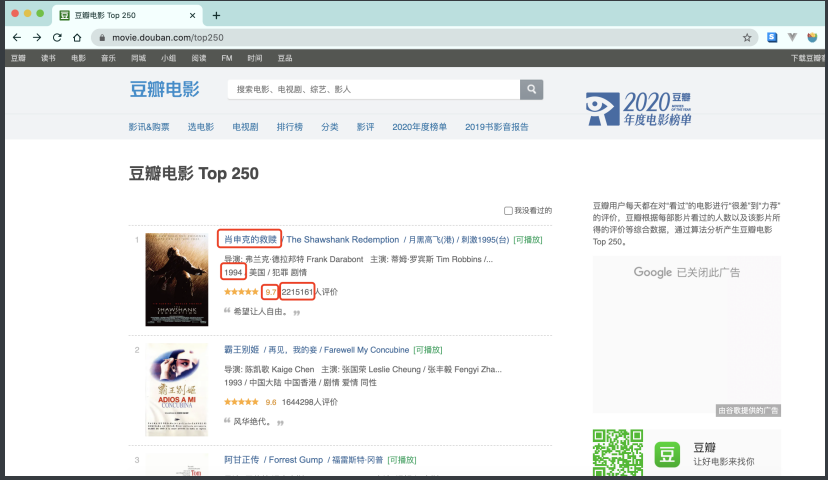
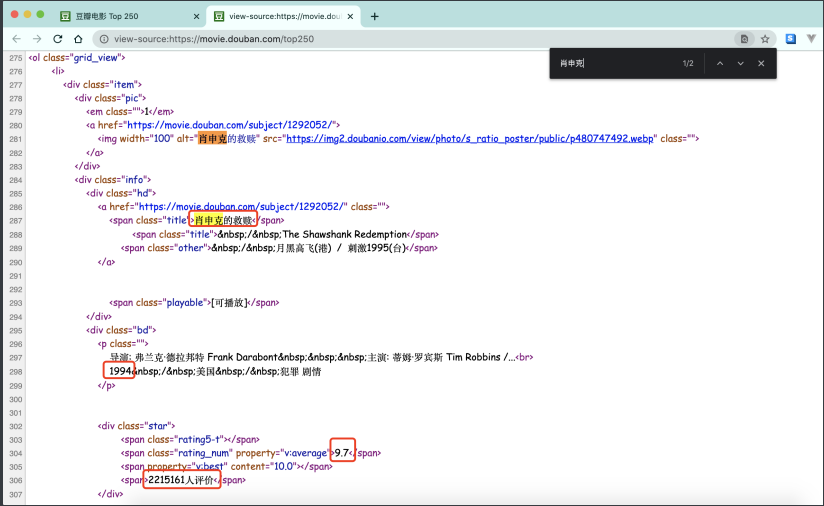
从页面源代码出发
最后,综上爬虫代码
import requests
import re
import csv
url = "https://movie.douban.com/top250"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36 Edg/100.0.1185.29"
}
resp = requests.get(url,headers=headers)
page_counter = resp.text
# 解析数据
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<br>(?P<year>.*?) '
r';/ .*?<span>(?P<num>.*?)人评价</span>', re.S)
# 开始匹配
result = obj.finditer(page_counter)
f = open ("data.csv", mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
for it in result:
# print(it.group("name"))
# print(it.group("num"))
# print(it.group("year").strip())
dic = it.groupdict()
dic['year'] = dic['year'].strip()
csvwriter.writerow(dic.values())
resp.close()
f.close()
print("OVER!")
2.1.4 实例二:爬取电影天堂推荐电影下载地址
流程:
1.定位到需要爬取的内容位置
2.从内容中提取到子页面的链接地址
3.请求子页面的链接地址,拿到我们想要的下载地址
代码如下:
import requests
import re
import csv
domain = "https://dytt89.com/"
reps = requests.get(domain, verify=False) # verify=False去掉安全验证
reps.encoding = "gb2312" # 指定字符型
# print(reps.text)
# 拿到ul里面的li
obj1 = re.compile(r"2022必看热片.*?<ul>(?P<ul>.*?)</ul>", re.S)
obj2 = re.compile(r"<a href='(?P<herf>.*?)'", re.S)
obj3 = re.compile(r'<div class="title_all"><h1>.*?《(?P<movie>.*?)》.*?'
r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">', re.S)
result1 = obj1.finditer(reps.text)
child_herf_list = []
for it in result1:
ul = it.group('ul')
# print(ul)
result2 = obj2.finditer(ul)
for itt in result2:
# 拼接子页面的url地址: 域名 + 子页面地址
child_herf = domain + itt.group("herf").strip("/")
# print(itt.group("herf"))
child_herf_list.append(child_herf) # 把子页面链接保存起来
f = open ("movie.csv", mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
# 提取子页面内容
for href in child_herf_list:
child_reps = requests.get(href, verify=False)
child_reps.encoding = "gb2312"
result3 = obj3.search(child_reps.text)
# print(result3.group("movie"))
# print(result3.group("download"))
dic = result3.groupdict()
csvwriter.writerow(dic.values())
child_reps.close()
print("OVER!")
reps.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号