
第一章 爬虫入门
第一章 爬虫入门
1.1 第一个爬虫程序
基础代码
# 制作者:tlott
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url) # resp是response的意思
with open("mybaidu.html", mode="w", encoding="utf-8") as f: # utf-8可由源代码中获取得知
f.write(resp.read().decode("utf-8")) # 读取网页的源代码
print("over!")
1.2 web请求过程剖析
渲染方式:
1)服务器渲染:
定义:在服务器端直接将数据和html整合在一起,统一返回给浏览器
特点:在页面源代码中能看到数据
2)客户端渲染:
定义:第一次请求只返回html骨架,第二次请求拿到数据,进行数据展示
特点:在页面源代码中看不到数据
1.3 HTTP协议
请求:
1)请求行—>请求方式(get/post)请求URL地址 协议
2)请求头—>放一些服务器要使用的附加信息
3)请求体—>一般放一些请求参数
响应:
1)请求行—>协议 状态码
2)响应头—>放一些客户端要使用的附加信息
3)响应体—>服务器返回的真正客户端要用的内容(HTML,json)等。
在后⾯我们写爬⾍的时候要格外注意请求头和响应头. 这两个地⽅一般都隐含着⼀些⽐较重要的内容
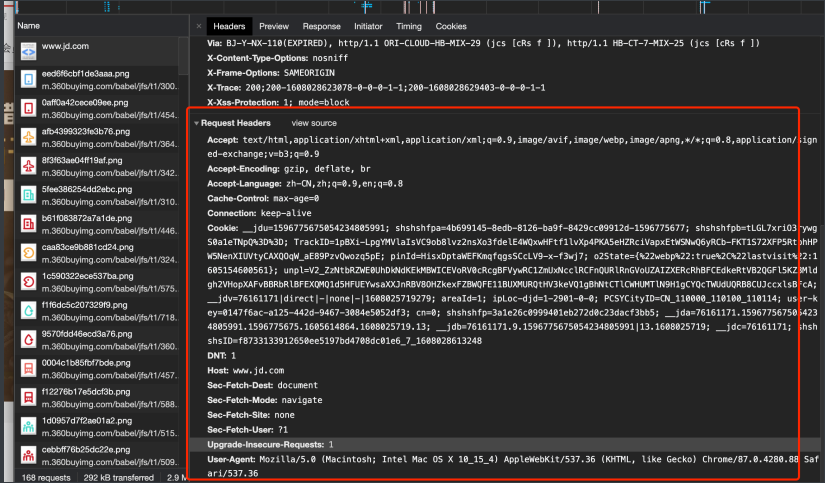
请求头中最常⻅的⼀些重要内容(爬⾍需要):
1.User-Agent : 请求载体的身份标识(⽤啥发送的请求)
2.Referer: 防盗链(这次请求是从哪个⻚⾯来的? 反爬会⽤到)
3.cookie: 本地字符串数据信息(⽤户登录信息, 反爬的token)
响应头中⼀些重要的内容:
1.cookie: 本地字符串数据信息(⽤户登录信息, 反爬的token)
2.各种神奇的莫名其妙的字符串(这个需要经验了, ⼀般都是token 字样, 防⽌各种攻击和反爬)
请求⽅式:
GET: 显示提交
POST: 隐示提交
1.4 Requests入门
import requests
url = "https://movie.douban.com/j/chart/top_list"
# 如果url值过长,可将?及其之后的内容删除,并在之后的内容中加入负载参数
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start" : 0,
"limit": 20
}
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.55"
}
resp = requests.get(url = url, params = param, headers=headers)
print(resp.json())
resp.close() # 关掉resp
⼀些⽹站在进⾏请求的时候会校验你的客户端设备型号,所以要注意headers的内容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号