机器学习基础
机器学习的数据
数据集(data set):https://en.wikipedia.org/wiki/Iris_flower_data_set
| 萼⽚长度 | 萼⽚宽度 | 花瓣长度 | 花瓣宽度 | 种类 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | se(0) |
| 7.0 | 3.2 | 4.7 | 1.4 | ve(1) |
| 6.3 | 3.3 | 6 | 2.5 | vi(2) |
-
样本(sample):每一行数据。
-
特征(feature):除去最后一列。
-
标记(label):最后一列。
- \(X^{(i)}\):第 \(i\) 个样本(特征向量)
- \(X_j^{(i)}\):第 \(i\) 个样本第 \(j\) 个特征值
- \(y^{(i)}\):第 \(i\) 个样本的标记
\[\left(\begin{array}{c}
\left(X^{(1)}\right)^T \\
\left(X^{(2)}\right)^T \\
\left(X^{(3)}\right)^T \\
\cdots
\end{array}\right)
\]
特征空间(feature space)
机器学习的任务
- 分类任务
- 二分类
- 判断邮件是垃圾邮件;不是垃圾邮件
- 判断发放给客户信⽤用卡有风险;没有风险
- 判断病患良性肿瘤;恶性肿瘤
- 判断某⽀支股票涨;跌
- ...
- 多分类
- 数字识别
- 图像识别
- 判断发放给客户信⽤用卡的风险评级
- ...
- 多标签分类
- 二分类
- 回归任务
• 有⼀一些算法只能解决回归问题;
• 有⼀一些算法只能解决分类问题;
• 有⼀一些算法的思路路既能解决回归问题,⼜又能解决分类问题。
监督学习,非监督学习,半监督学习和增强学习
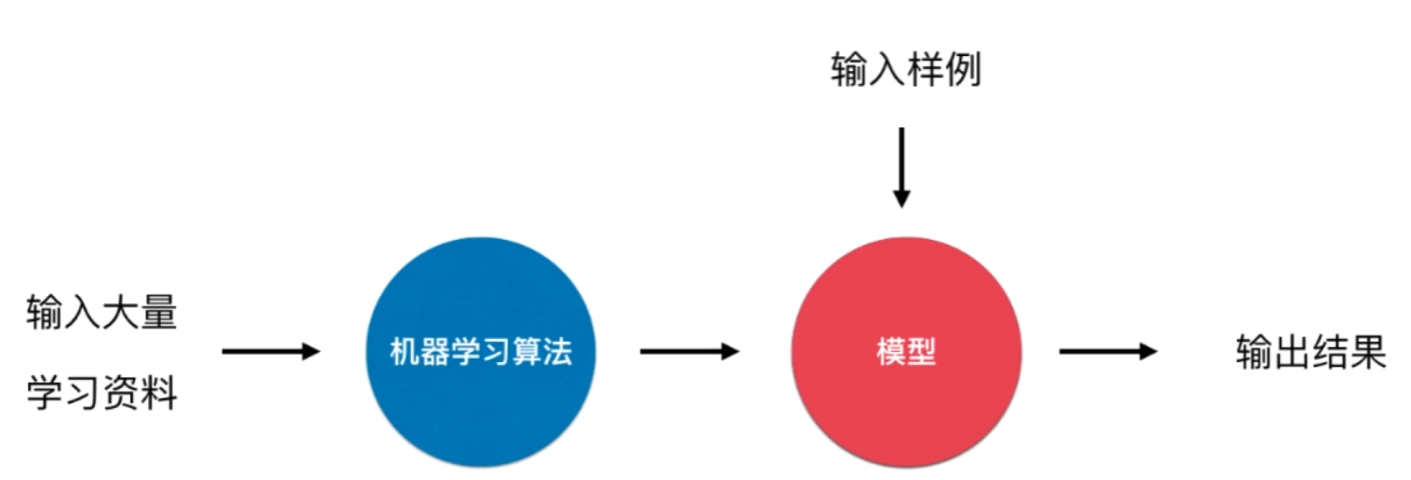
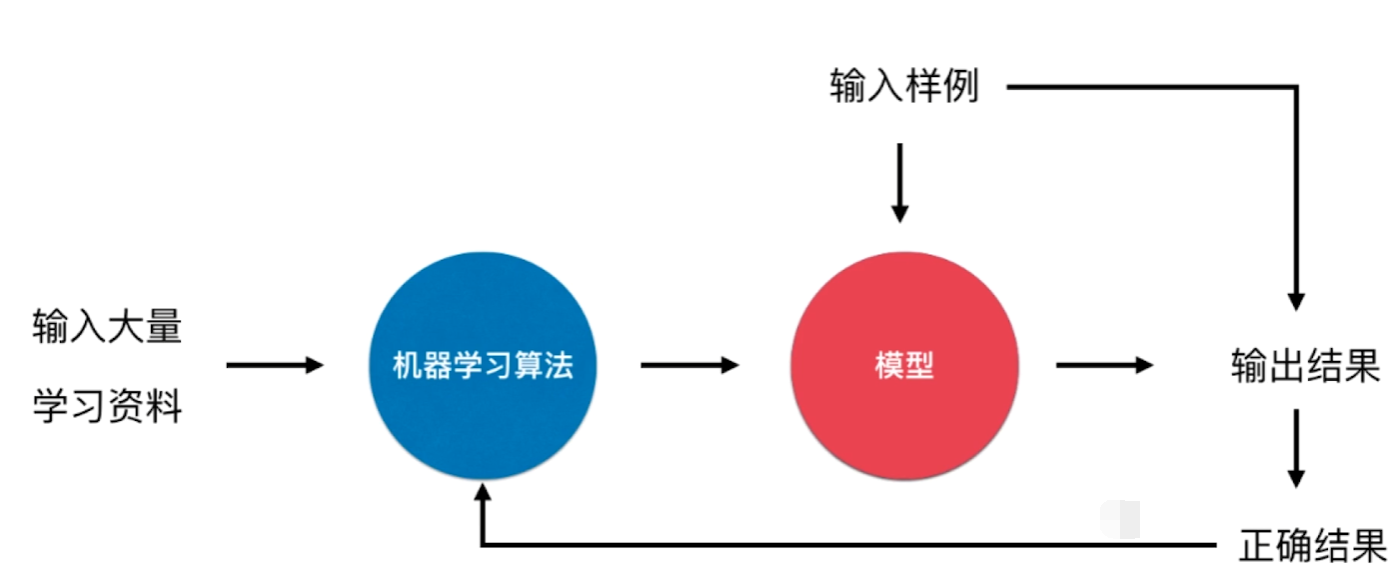
监督学习(supervised learning):给机器的训练数据拥有“标记”或者“答案”。
- 举例:
- K近邻
- 线性回归
- 多项式回归
- 逻辑回归
- SVM
- 决策树
- 随机森林
非监督学习(unsupervised learning):给机器的训练数据没有任何“标记”或者“答案”。
- 意义:对数据进行降维处理。
- 特征提取
- 特征压缩
- 方便可视化
- 异常检测
半监督学习(semi-supervised learning):一部分数据有“标记”或者“答案”,另一部分数据没有。
- 处理方式:
- 先使用无监督学习手段对数据做处理;
- 后使用监督学习手段对模型进行训练和预测。
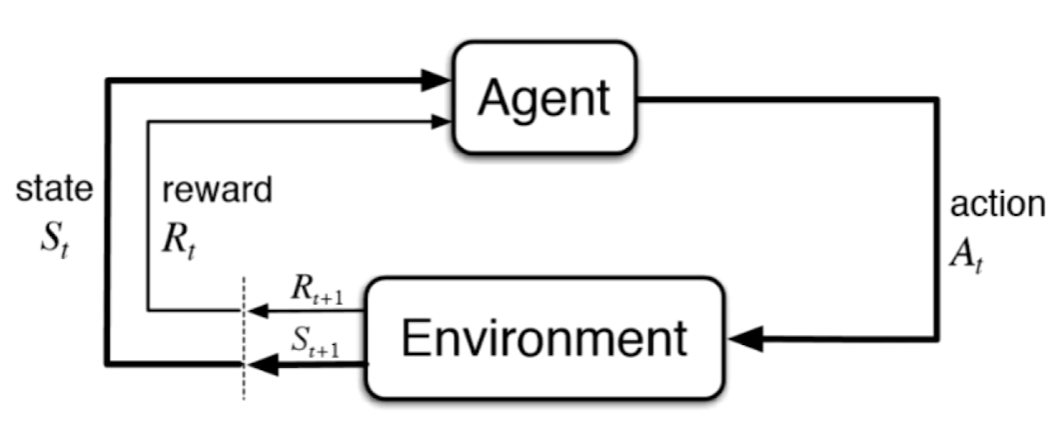
强化学习(reinforcement Learning):根据周围环境的情况,采取⾏行行动,根据采取⾏行行动的结果,学习⾏行行动⽅方式。
批量学习,在线学习,参数学习和非参数学习
批量学习(Batch Learning)

在线学习(Online Learning)
参数学习(Parametric Learning)
非参数学习(Nonparametric Learning)

