Python_Note_Day 9_threading.Thread_multiprocessing.Process_Queue
Python多线程 不适合cpu密集操作型的任务,适合io操作密集型任务。
注1:如果是I/O操作密集型,就用多线程,如果计算密集型,就用多进程去处理。
注2:进程之间不能资源共享,但线程间可以资源共享。
注3:线程只能自己控制线程数量,而多进程,则可以放入一个进程池里,可以控制线程的数量。所以可以利用Queue来控制线程的数量。
内容:
一、线程
二、进程
三、队列
一、协程
A,B,C进程依次请求CPU计算:
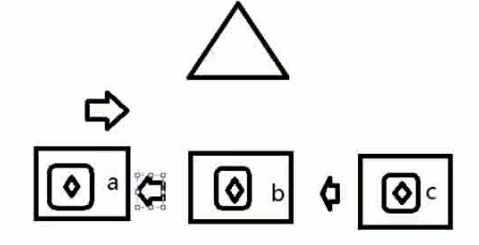
1. 单CPU,多进程,分片式循环执行多个进程。
A->B->C
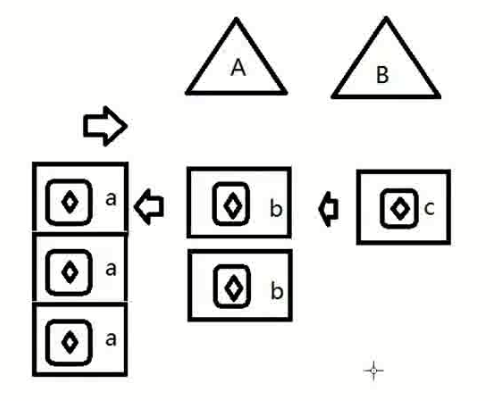
2. 单CPU,多核,多进程,每个逻辑的核分片式循环行执行多个进程。现在物理最多18个核,逻辑最多36个核。
CPU CORE1: A1->B2->C1
CPU CORE2: B1->A2->A3
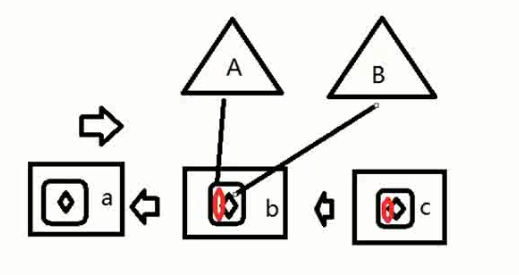
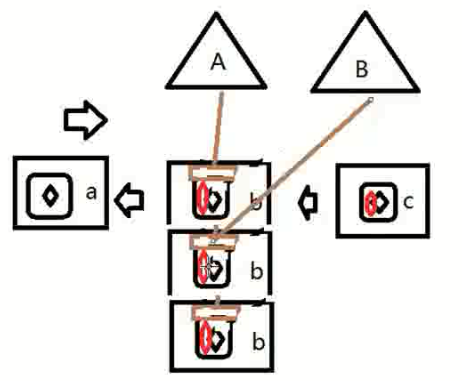
3. 多CPU,多核,多个进程,每个进程中多线程,每CPU的每个逻辑核循环分片行执行多个进程中的多个线程。进程A的多线程可在多CPU的多核上并行执行。
CPU1 CORE1: A1->B2
CPU2 CORE1: B1->C2
CPU1 CORE2: A2
CPU2 CORE2: C1
线程锁(Lock、RLock)
由于线程之间是进行随机调度,并且每个线程可能只执行n条执行之后,当多个线程同时修改同一条数据时可能会出现脏数据,所以,出现了线程锁 - 同一时刻允许一个线程执行操作。(所以说,Python是假线程,同一时刻,cpu只能运行一个线程。但是在处理I/O操作时,Python线程的并发,还是比串行要快,因为在大量的I/O操作的时候,线程并发且不太占用CPU资源,无需等待(虽只能一次只能运行一个线程,但cpu的资源在进程中多线程共享),而串行的进程,cpu资源不能共享,要等待上一个进程运行等待完I/O操作,在进行下一个进程。20个线程,每个进程等待1s,等待时间是1s,而20个进程,等待时间是20s)==>I/O操作密集型,用线程,CPU密集型,用进程。
防止锁的功能是:即使在一个进程里有多个线程,要求只有一个线程被读出来,其他等待。(只有一个线程能被一个CPU核调用。)

解决方案:创建多个相同的进程,让多个进程中的不同线程被多个CPU调用。
缺点:线程是可以共享一个进程内的资源,但多进程之间是不能共享内存资源的。造成内存浪费。
1. 基本的多线程:
threading.Thread模块
- start() #线程准备就绪,等待CPU调度
- getName() #获取线程名称
- setName() #为线程设置名称
- isDaemon()
- setDaemon() #设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止
- join(timeout) #逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
- run() #线程被cpu调度后自动执行线程对象的run方法
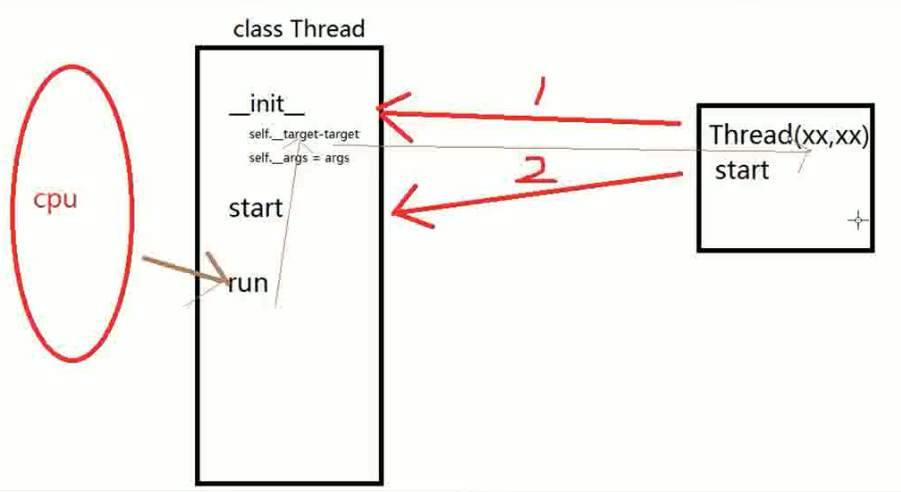
Thread执行过程:
1. 创建实例,执行构造函数,并把target和args赋值到Thread的构造函数中。
2. 调用了start方法。
3. run操作被触发时,执行了target方法(target方法是从Thread调用的方法)。
直接调用
1 import threading 2 import time 3 4 def run(n): #run的名字可以换 5 print("running %s" %n) 6 7 for i in range(10): 8 t = threading.Thread(target=run, args=(i,)) #逗号很重要,当只有一个参数时,一定加逗号才能正确解析出它是元组。 9 t.start() 10 11 print('finished')
#Outcome:
/usr/bin/python3.5 "/home/tlfox/PycharmProjects/PyScr/Day 9/Thread03.py"
running 0
running 1
running 2
running 3
running 4
running 5
running 6
running 7
running 8
finished
running 9 #子线程和主线程是并列执行的。有时子线程执行比主线程慢
继承式调用
1 import threading 2 import time 3 4 class MyThread(threading.Thread): 5 def __init__(self,num): 6 threading.Thread.__init__(self) #继承threading.Thread函数,也可以写成:super(MyThread,self).__init__(self) 7 self.num = num 8 9 def run(self): #定义每个线程要运行的函数 10 print("running on number:%s" %self.num) 11 12 time.sleep(3) 13 14 if __name__ == '__main__': 15 16 t1 = MyThread(1) 17 t2 = MyThread(2) 18 t1.start() 19 t2.start()
2. join:
1 import threading 2 import time 3 4 def run(n): 5 print("running %s" %n) 6 time.sleep(1) 7 print('task done') 8 9 t_res = [] 10 for i in range(10): 11 t = threading.Thread(target=run, args=(i,)) 12 t.setDaemon(True) 13 t.start() 14 t_res.append(t) 15 #print('starting thread', t.getName()) 16 17 for k in t_res: 18 k.join() #等待线程结束 ,即使设置了守护进程,但是有了join(),就会等待子线程实行完后,再去执行主线程。k.join(5)等待5秒。
19 print('finished')
#outcome:
/usr/bin/python3.5 "/home/tlfox/PycharmProjects/PyScr/Day 9/Thread03.py"
running 0
running 1
running 3
running 4
running 2
running 5
running 6
running 7
running 8
running 9
task done
task done
task done
task done
task done
task done
task done
task done
task done
task done #必须等待所有线程都执行完,再执行主程序。
finished
3. setDaemon:
1 import threading 2 import time 3 4 def run(n): 5 print("running %s" %n) 6 time.sleep(1) 7 print('task done') 8 9 t_res = [] 10 for i in range(10): 11 t = threading.Thread(target=run, args=(i,)) 12 t.setDaemon(True) #守护进程,当主进程结束,子进程也随之结束。默认情况下,守护进程是false。可以用isDaemon()来查看。 13 t.start() 14 t_res.append(t)
15 print('finished')
#outcomes:
/usr/bin/python3.5 "/home/tlfox/PycharmProjects/PyScr/Day 9/Thread03.py"
running 0
running 1
running 2
running 3
running 4
running 5
running 6
running 7
running 8
running 9
finished #主程序结束了,子线程就会结束,不会再继续进行了。task done将无法再打印。
4. run()
1 from threading import Thread 2 import time 3 class MyThread(Thread): #继承Thread的构造函数(__init__()) 4 def run(self): 5 time.sleep(10) 6 print(‘I am a Thread’) 7 8 def Bar(): 9 print('bar') 10 11 t1 = MyThread(target = Bar) #执行了Thread的构造函数,并将bar赋值给了Thread构造函数__target(self.__target=target(__xx为私有字段,只能在函数内部调用。))。 12 t1.start() 13 print('over')
#Outcome:
5. Mutex Locks
注:不要在3.x上运行,不知为什么,3.x上的结果总是正确的,可能是自动加了锁
1 import time 2 import threading 3 4 def addNum(): 5 global num #在每个线程中都获取这个全局变量 6 print('--get num:',num ) 7 time.sleep(1) 8 lock.acquire() #修改数据前加锁 9 num -=1 #对此公共变量进行-1操作 10 lock.release() #修改后释放 11 12 num = 100 #设定一个共享变量 13 thread_list = [] 14 lock = threading.Lock() #生成全局锁 15 for i in range(100): 16 t = threading.Thread(target=addNum) 17 t.start() 18 thread_list.append(t) 19 20 for t in thread_list: #等待所有线程执行完毕 21 t.join() 22 23 print('final num:', num )
6. 信号量(Semaphore)
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
1 import threading,time 2 3 def run(n): 4 semaphore.acquire() 5 time.sleep(1) 6 print("run the thread: %s" %n) 7 semaphore.release() 8 9 if __name__ == '__main__': 10 num= 0 11 semaphore = threading.BoundedSemaphore(5) #最多允许5个线程同时运行 12 for i in range(20): 13 t = threading.Thread(target=run,args=(i,)) 14 t.start()
7.事件(event): traffic_light
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
- clear:将“Flag”设置为False
- set:将“Flag”设置为True
1 import threading,time 2 3 def traffic_light(): 4 counter = 0 5 event.set() 6 while True: 7 if counter < 10: 8 print('green light') 9 elif counter < 13: 10 print('yellow light') 11 elif counter < 20: 12 if event.is_set(): 13 event.clear() 14 print('red light') 15 else: 16 counter = 0 17 event.set() 18 time.sleep(1) 19 counter += 1 20 21 def car(name): 22 while True: 23 if event.is_set(): 24 print("car[%s] is running" %name) 25 else: 26 print("car[%s] is waiting" %name) 27 time.sleep(0.5) 28 29 if __name__ == '__main__': 30 event=threading.Event() 31 Light = threading.Thread(target=traffic_light) 32 Light.start() 33 for i in range(4): 34 Car = threading.Thread(target=car,args=(i,)) 35 Car.start()
8. 条件(Condition)
使得线程等待,只有满足某条件时,才释放n个线程
1 import threading 2 3 def run(n): 4 con.acquire() 5 con.wait() 6 print("run the thread: %s" %n) 7 con.release() 8 9 if __name__ == '__main__': 10 11 con = threading.Condition() 12 for i in range(10): 13 t = threading.Thread(target=run, args=(i,)) 14 t.start() 15 16 while True: 17 inp = input('>>>') 18 if inp == 'q': 19 break 20 con.acquire() 21 con.notify(int(inp)) 22 con.release()


1 def condition_func(): 2 ret = False 3 inp = input('>>>') 4 if inp == '1': 5 ret = True 6 7 return ret 8 9 def run(n): 10 con.acquire() 11 con.wait_for(condition_func) 12 print("run the thread: %s" %n) 13 con.release() 14 15 if __name__ == '__main__': 16 con = threading.Condition() 17 for i in range(10): 18 t = threading.Thread(target=run, args=(i,)) 19 t.start()
二、进程(Process)
1. 进程调用:
1 from multiprocessing import Process 2 import os 3 4 def info(title): 5 print(title) 6 print('module name:', __name__) 7 print('parent process:', os.getppid()) #父进程总是一个,子进程可以多个。 8 print('process id:', os.getpid()) 9 print("\n\n") 10 11 def f(name): 12 info('\033[31;1mfunction f\033[0m') 13 print('hello', name) 14 15 if __name__ == '__main__': 16 info('\033[32;1mmain process line\033[0m') 17 p = Process(target=f, args=('bob',)) 18 p.start() 19 p.join()
注意:由于进程之间的数据需要各自持有一份,所以创建进程需要的非常大的开销。
2. 进程数据共享
进程各自持有一份数据,默认无法共享数据
1 from multiprocessing import Process 2 from multiprocessing import Manager 3 import time 4 5 li = [] 6 7 def foo(i): 8 li.append(i) 9 print('say hi',li) 10 11 for i in range(10): 12 p = Process(target=foo,args=(i,)) 13 p.start() 14 15 print('ending',li)
- 方法一:Array:
1 from multiprocessing import Process,Array 2 temp = Array('i', [11,22,33,44]) 3 4 def Foo(i): 5 temp[i] = 100+i 6 for item in temp: 7 print(i,'----->',item) 8 9 for i in range(2): 10 p = Process(target=Foo,args=(i,)) 11 p.start()
- 方法二:manage.dict()共享数据
1 from multiprocessing import Process,Manager 2 3 manage = Manager() 4 dic = manage.dict() 5 6 def Foo(i): 7 dic[i] = 100+i 8 print dic.values() 9 10 for i in range(2): 11 p = Process(target=Foo,args=(i,)) 12 p.start() 13 p.join()
3. 进程池
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
1 from multiprocessing import Process,Pool 2 import time 3 4 def f(x): 5 time.sleep(0.5) 6 print(x*x) 7 return(x*x) 8 9 p = Pool(5) # 进程池中5个进程。 10 print(p.map(f,[1,2,3,4,5,6,7,8,9])) # 生成并去进程池里取进程。多个进程共同跑。
进程池中有两个方法:
- apply
- apply_async
1 from multiprocessing import Process,Pool 2 import time 3 4 def Foo(i): 5 time.sleep(2) 6 return i+100 7 8 def Bar(arg): 9 print arg 10 11 pool = Pool(5) 12 #print pool.apply(Foo,(1,)) #启动进程,并等待他完成。串行运行。 13 #print pool.apply_async(func =Foo, args=(1,)).get() #并行运行。 14 15 for i in range(10): 16 pool.apply_async(func=Foo, args=(i,),callback=Bar) #无需用.start()启用。 17 #等于Process(target=Foo, args=(i,)).start()。 18 print 'end' 19 pool.close() 20 pool.join()#进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
#上面的部分相当于 print pool.map(f,range(10))
4. 进程同步
Without using the lock output from the different processes is liable to get all mixed up.
1 from multiprocessing import Process 2 from threading import Thread 3 import time 4 5 #Process 乱序输出 6 def f(i): 7 print('hello world',i) 8 9 for num in range(10): 10 Process(target=f,args=(num,)).start() 11 12 time.sleep(3) 13 14 #Thread正序输出 15 def f1(i): 16 print('hello world2',i) 17 18 for num in range(10): 19 Thread(target=f1,args=(num,)).start()
#Outcome:
tlfox@tlfox-virtual-machine:~/Homework/08day7$ python3.5 process_lock.py
hello world 0
hello world 1
hello world 3
hello world 2
hello world 4
hello world 8
hello world 5
hello world 6
hello world 9
hello world 7
hello world2 0
hello world2 1
hello world2 2
hello world2 3
hello world2 4
hello world2 5
hello world2 6
hello world2 7
hello world2 8
hello world2 9
解决方法:
- join()
1 from multiprocessing import Process 2 3 def f(i): 4 print('hello world',i) 5 6 for num in range(10): 7 p=Process(target=f,args=(num,)) 8 p.start() 9 p.join()
- Lock()
1 from multiprocessing import Process, Lock 2 3 def f(l, i): 4 l.acquire() 5 try: 6 print('hello world', i) 7 finally: 8 l.release() 9 10 if __name__ == '__main__': 11 lock = Lock() 12 13 for num in range(10): 14 Process(target=f, args=(lock, num)).start()
5. 进程间通信 ->可以先看Queue的例子
三、Queue
1. 线程Queue
- class
queue.Queue(maxsize=0) #First In First Out - class
queue.LifoQueue(maxsize=0) #last in fisrt out - class
queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
Queue.qsize() Queue.empty() #return True if empty Queue.full() # return True if full Queue.put(item, block=True, timeout=None) Put item into the queue. If optional args block is true and timeout is None (the default), block if necessary until a free slot is available. If timeout is a positive number, it blocks at most timeout seconds and raises the Full exception if no free slot was available within that time. Otherwise (block is false), put an item on the queue if a free slot is immediately available, else raise the Full exception (timeout is ignored in that case). Queue.put_nowait(item) Equivalent to put(item, False). Queue.get(block=True, timeout=None) Remove and return an item from the queue. If optional args block is true and timeout is None (the default), block if necessary until an item is available. If timeout is a positive number, it blocks at most timeout seconds and raises the Empty exception if no item was available within that time. Otherwise (block is false), return an item if one is immediately available, else raise the Empty exception (timeout is ignored in that case). Queue.get_nowait() Equivalent to get(False). Two methods are offered to support tracking whether enqueued tasks have been fully processed by daemon consumer threads. Queue.task_done() Indicate that a formerly enqueued task is complete. Used by queue consumer threads. For each get() used to fetch a task, a subsequent call to task_done() tells the queue that the processing on the task is complete. If a join() is currently blocking, it will resume when all items have been processed (meaning that a task_done() call was received for every item that had been put() into the queue). Raises a ValueError if called more times than there were items placed in the queue. Queue.join() block直到queue被消费完毕
FIFO, LILO,PirorityQueue
1 import queue,threading 2 3 #FIFO 4 q = queue.Queue(20) 5 for i in range(10): 6 q.put(i) 7 8 while not q.empty(): 9 print(q.get()) 10 11 #LILO 12 q = queue.LifoQueue(10) 13 for i in range(10): 14 q.put(i) 15 16 while not q.empty(): 17 print(q.get()) 18 19 #Priority Queue 20 class Task: 21 def __init__(self,priority,description): 22 self.priority= priority 23 self.description = description 24 25 def __lt__(self,other): 26 return(self.priority <other.priority) 27 q = queue.PriorityQueue() 28 q.put(Task(1, 'Important task')) 29 q.put(Task(10, 'Normal task')) 30 q.put(Task(100, 'Lazy task')) 31 32 def job(q): 33 while True: 34 task = q.get() 35 print('Task: %s\n' %task.description) 36 q.task_done() 37 38 threads = [threading.Thread(target=job, args=(q,)),threading.Thread(target=job, args=(q,))] 39 for t in threads: 40 t.setDaemon(True) 41 t.start() 42 q.join()
生产者消费者模型
- 为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
- 什么是生产者消费者模式
生产者消费者模型是解决效率和解耦。异步是在不同模块间,使独立性变的非常强,减少阻塞,他们之间的联系变成空耦合。这样,在分布式开发的时候(协作开发的时候),效率才更高,并且程序的运行速度也更高。
1 import threading 2 import queue 3 4 def producer(): 5 for i in range(10): 6 q.put("骨头 %s" % i ) 7 8 print("开始等待所有的骨头被取走...") 9 q.join() 10 print("所有的骨头被取完了...") 11 12 13 def consumer(n): 14 15 while q.qsize() >0: 16 17 print("%s 取到" %n , q.get()) 18 q.task_done() #告知这个任务执行完了 19 20 q = queue.Queue() 21 p = threading.Thread(target=producer,) 22 p.start() 23 24 c1 = consumer("李闯")
1 import time,random 2 import queue,threading 3 q = queue.Queue() 4 def Producer(name): 5 count = 0 6 while count <20: 7 time.sleep(random.randrange(3)) 8 q.put(count) 9 print('Producer %s has produced %s baozi..' %(name, count)) 10 count +=1 11 def Consumer(name): 12 count = 0 13 while count <20: 14 time.sleep(random.randrange(4)) 15 if not q.empty(): 16 data = q.get() 17 print(data) 18 print('\033[32;1mConsumer %s has eat %s baozi...\033[0m' %(name, data)) 19 else: 20 print("-----no baozi anymore----") #当吃比产快时候。 21 count +=1 22 p1 = threading.Thread(target=Producer, args=('A',)) 23 c1 = threading.Thread(target=Consumer, args=('B',)) 24 p1.start() 25 c1.start()
2.进程Queue
#不同进程间内存是不共享的,要想实现两个进程间的数据交换,可以用以下方法:Queues,Pipes,Managers
- MultiProcessing Queue #Process Queue 其实是不能共享内存的,他们之间得用序列化的方式传输数据。
1 from multiprocessing import Process, Queue 2 3 def f(q): 4 q.put([42, None, 'hello']) 5 6 if __name__ == '__main__': 7 q = Queue() 8 p = Process(target=f, args=(q,)) 9 p.start() 10 print(q.get()) # prints "[42, None, 'hello']" 11 p.join()
- Multiprocessing Pipe #Each connection object has
send()andrecv()methods (among others), by default is duplex (two-way).
1 from multiprocessing import Process, Pipe 2 3 def f(conn): 4 conn.send([42, None, 'hello']) 5 conn.close() 6 7 if __name__ == '__main__': 8 parent_conn, child_conn = Pipe() 9 p = Process(target=f, args=(child_conn,)) 10 p.start() 11 print(parent_conn.recv()) # prints "[42, None, 'hello']" 12 p.join()
- Managers
1 from multiprocessing import Process, Manager 2 3 def f(d, l): 4 d[1] = '1' 5 d['2'] = 2 6 d[0.25] = None 7 l.append(1) 8 print(l) 9 10 if __name__ == '__main__': 11 with Manager() as manager: 12 d = manager.dict() 13 l = manager.list(range(5)) 14 p_list = [] 15 for i in range(10): 16 p = Process(target=f, args=(d, l)) 17 p.start() 18 p_list.append(p) 19 for res in p_list: 20 res.join() 21 22 print(d) 23 print(l)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号