


Finance_时间序列分析_贝叶斯滤波&卡尔曼滤波
卡尔曼滤波的原理
https://space.bilibili.com/287989852?from=search&seid=10742836651514724908
https://www.bilibili.com/video/BV1QE411y7jb?from=search&seid=8397173496726970618
卡尔曼滤波 配对交易
https://zhuanlan.zhihu.com/p/47471981
卡尔曼滤波pykalman的example:
一维:https://zhuanlan.zhihu.com/p/23670413
二维:
https://blog.csdn.net/coming_is_winter/article/details/79048700
卡尔曼滤波及其在配对交易中的应用: https://cloud.tencent.com/developer/article/1358311
https://xbuba.com/questions/55228609
总结:
1)卡尔曼滤波浓缩版
贝叶斯滤波:
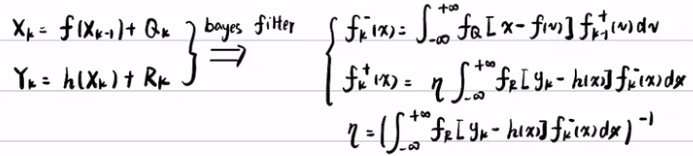
贝叶斯滤波--> 卡尔曼滤波:
 --》
--》 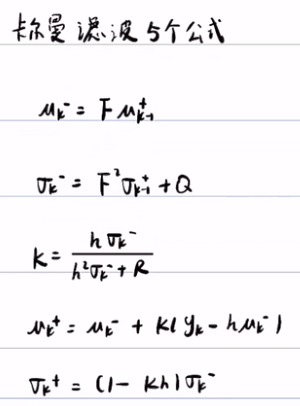
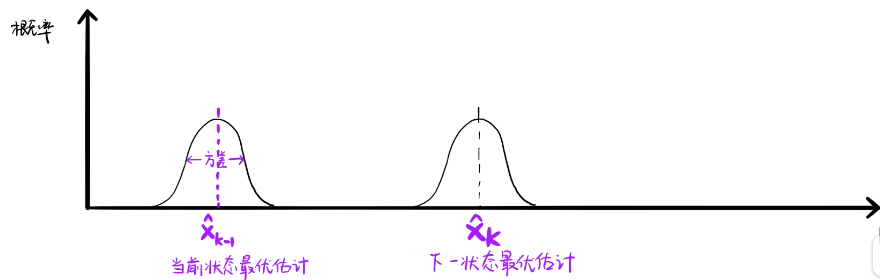
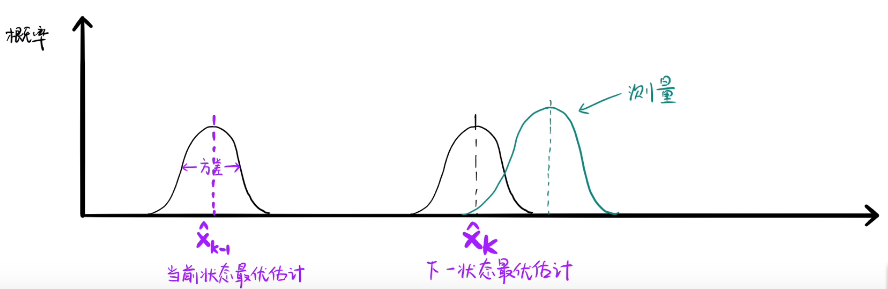
卡尔曼滤波是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。如图所示,xk_hat是下一个状态的最优估计,每个最优估计都是有期望和方差,其中某些估计是很贴合真实的状态。但每次预测不能是特别准确的,需要用观测来优化我们的预测,这就是卡尔曼滤波总更新的操作。测量的方差代表我们测量的噪声,同样测量的部分数据也是在真实值里面的。所以我们可以利用预测和测量来找的更准确的估计。由于卡尔曼滤波的前提是高斯分布,所以我们可以融合这两个分布,得到更新后的下一状态的最优估计。

卡尔曼的核心思想就是:上面的那5个公式。
F是状态转移矩阵,μ是随机变量的期望,σ是随机变量x的方差/协方差矩阵,预测/转换方程为:
uk- =F*uk-1+
(σk-)2 = F*(σk-1-)2 + Qk Q~N(0,1) 若是协方差矩阵:Σk= F Σk-1 F+ Qk
我们预测时,通过F(状态矩阵)转换为新的状态,期望/均值 u 是不变的,但由于外界的不确定性,状态转移时会有偏差,这些不确定性就叫做噪声Qk。
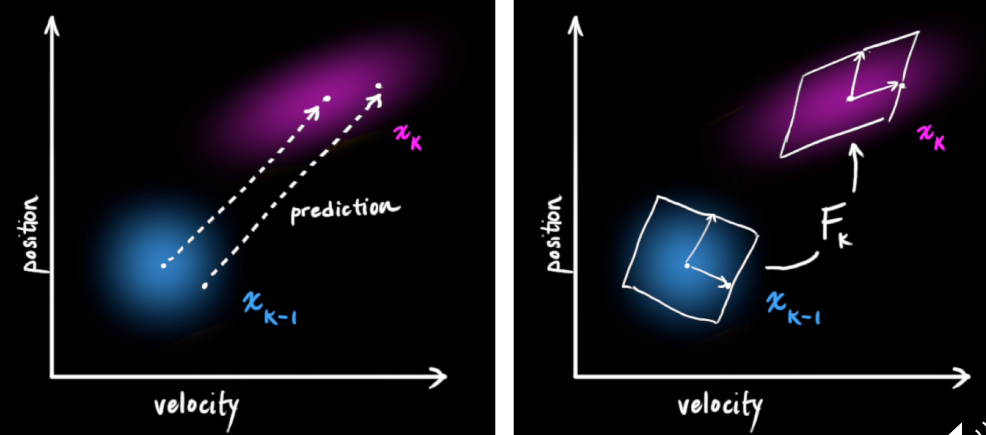
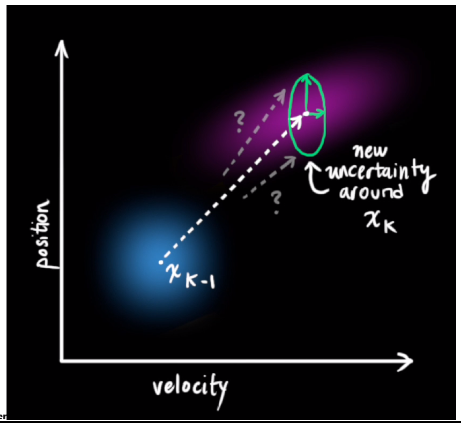
预测完之后,我们还需要用观测值来优化我们的预测。观测就需要用到传感器来观测数据。矩阵 Hk 来表示传感器的数据。同样,由于外界因素,传感器的信息也是完全准确,所以传感器读到的数据也有一定的方差。通过观测值我们可以大致猜到真实状态。

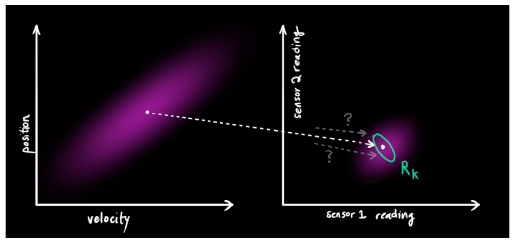
现在我们有了两个高斯分布,一个是预测值的高斯分布,一个传感器读数的高斯分布。这样我们就可以通过这两组数据/分布,来找到最优解。由于两个高斯分布相乘还是一个高斯分布。 通过化简后的到一个相同部分K,这个K就是卡尔曼增益。



μ‘是更新后的均值,σ’是更新后的方差, μ0和σ0是预测的均值和方差,而 μ1和σ1是观测的均值和方差
K = σ02/σ02+σ12 = hσk2/(hσk2+R) R = σ12 是观测值的方差,hσk
μ‘= μ0+K( μ1-μ0) = 》 μ+ = μk- +K( yk - hμk-)
σ’ = σ12-Kσ02 =》 σk+ = (1-Kh)σk-2
2)卡尔曼滤波详细版
离散型随机变量的贝叶斯公式:P(X|Y) = P(Y|X)*P(X) /P(Y)
连续型随机变量的贝叶斯公式:f(X|Y) = f(Y|X)*f(X) / f(Y) -- f(Y) =η --> η = 1/ ∫f(Y|X)*f(X) ,所以f(y)是常数η ,与三大概率无关。
后验概率 = η * 似然概率 * 先验概率 --> f(X|Y) = η*f(Y|X)*f(X)
预测方程:Xk = f(Xk-1) + Q
观测方程:Yk = h(Xk) + R
贝叶斯滤波:
- 将预测方程带入到先验概率得到先验概率:P(X<x) = fk-(x) = ∫fQ [x-f(v)] * fk-1(v)dv
- 将观测方程带入到似然概率得到后验概率:P(X|Y) = fk+(x) = η * ∫fR [yk-h(x)] * fk-(x)
- 从而得到常数η :η = ( ∫fR [yk-h(x)] * fk-(x)dx )-1
卡尔曼滤波:
1) 相对于贝叶斯滤波,多了几个假设:
- f(x)与h(x)都是线性函数
- fQ(x)与fR(x)都是服从正态分布
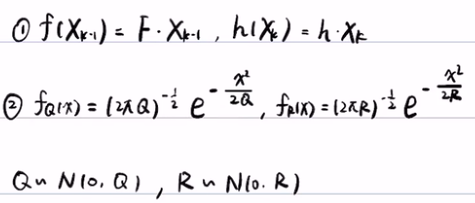
2)预测步(求先验概率):根据贝叶斯滤波,第一步是写出预测 步公式,然后将相应得正态分布的概率密度带入积分就行了。最后得到 u-k和σ-k。

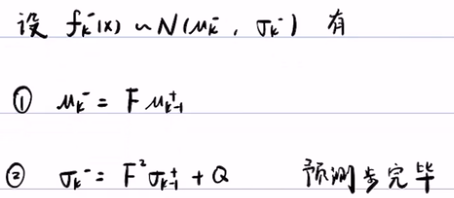
3) 更新步(求后验概率):已知 fk-(x) (先验概率)服从正态分布,那么fk+(x)后验概率就是常数 η 乘以似然概率 fR(yk-h*x)(似然概率也服从正态分布)和先验概率fk-(x)。
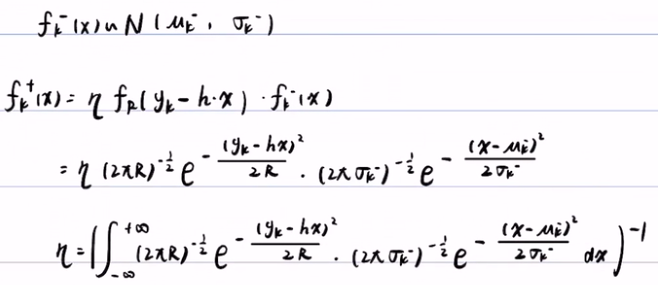
最后得出卡尔曼滤波5公式:
卡尔曼滤波的应用:
模型1


# loding modules import numpy as np import pandas as pd from pandas import * import matplotlib.pyplot as plt #X(k) = F*X(K-1)+Q #Y(k) = H*X(K)+R #第一个问题,生成一段随机信号,并滤波 #生成一段时间t,每隔0.01秒进行采样一次。 t = np.arange(0.1,1,0.01) L = len(t) #有了时间,就可以生成真实信号x,以及观测y。 #首先初始化 x=pd.Series(np.zeros(L)) y=pd.Series(np.zeros(L)) #不能将x赋值给y(即y=x),这样只会将x与y用做同一内存空间。 #生成信号,设x=t^2 for i in range(L): x[i]=t[i]**2 y[i]=x[i]+np.random.normal(0,0.1) plt.plot(t,x) plt.plot(t,y) #滤波算法 #预测方程怎么写: #观测方程:Y(K)=X(K)+R R~N(0,1),贝叶斯滤波也卡尔曼滤波的难点就是Q和R的方差的取值,它的难点在于没有规律性,只能不停的去试。 #预测方程不好写,画图(plt.plot(t,y))后,可以看出曲线的一些规律性,可以猜一猜是线性增长,但是大多数问题,信号是杂乱无章的,怎么办。 #模型一,最粗糙的建模: #X(k)=X(k-1)+Q #Y(k)=X(k)+R #猜Q~N(0,1),弄成正态分布,相对好处理一些。 F1=1 H1=1 Q1=1 R1=1 #初始化X(k)+,要设置一个数组来装这个X(k)+,因为卡尔曼滤波是递推的,X(k)+需要X(k-1)+。 Xplus1=Series(np.zeros(L)) Pplus1=Series(np.zeros(L)) Xminus1=Series(np.zeros(L)) Pminus1=Series(np.zeros(L)) K1=Series(np.zeros(L)) #设置一个初值,假设Xplus1(1)~N(0.01,0.01^2) Xplus1[0]=0.01 Pplus1[0]= 0.01**2 #卡尔曼滤波算法:它是期望与方差之间的递推关系,用前一时刻plus的期望和方差,推出这一时刻minus的期望和方差。以及这一时刻minus的期望和方差,推出这一时刻plus的期望和方差。再加上一个卡尔曼增益。X(0)是没有minus,且带plus的先验概率的,除了X(0)外所有X(k)的minus为先验概率,而plus为后验概率。 #X(k)minus = F*X(k-1)plus #P(k)minus = F*P(k-1)plus*F+Q #K = P(k)minus*H*inv(H*P(k)minus*H'+R) #X(k)plus = X(k)minus+K*(y(k)-H*X(K)minus) #P(k)plus = (1-K*H)*P(k)minus for i in range(1,L): ##预测步: Xminus1[i]=F1*Xplus1[i-1] Pminus1[i]=F1*Pplus1[i-1]*F1'+Q1 #F1'是Matlab求转置。 ##更新步: K1[i] = (Pminus1[i]*H1')/(H1*Pminus1[i]*H1'+R1) Xplus1[i] = Xminus1[i]+K1[i]*(y[i]-Xminus1[i]*H1) Pplus1[i]=(1-K1[i]*H1)*Pminus1[i] plt.plot(figsize=(20,12)) plt.plot(t,x,'r') plt.plot(t,y,'g') plt.plot(t,Xplus1,'b') #Q1,R1=0.01,控制噪声的方差。 #Xplus1[0]控制初始值,初始值的大小对滤波影响不大,最后滤波会调整。
模型2
###### 模型2 ########## #模型2相对于模型1相比,观测方程还是一样,但预测方程一项,把X(k)写成用X(k-1)展开的一些项(泰勒展开式)。 #X(K)=X(K-1)*dt+X'(K-1)*dt+X''(K-1)*dt^2*(1/2!) #Y(K)=X(K)+R R~N(0,1) #此时状态变量不再是标量了,而是向量:X=[X(k) X'(K) X''(K)]T 列向量 #Y(K)=H*X+R H=[1 0 0] 行向量 #预测方程 #X(K)=X(K-1)+X'(K-1)*dt+X''(K-1)*dt^2*(1/2!)+Q2 #X'(K)=0*X(K-1)+X'(K-1)+X''(K-1)*dt+Q3 #X''(K)=0*X(K-1)+0X'(K-1)+X''(K-1)*dt+Q3 多项式信号多求多阶导数,总会比较平缓,而 #X'''(K)=X''(k-1)+Q3正是描述平衡的随机过程,这种建模相对精细一些,适用范围也较广。它的原理就是无论是什么函数,多求几次导,总会求到0,0就比较平缓了。对导数建随机平稳得模型,要比直接对多项式函数建平稳得模型相对来说精细一点。但有可能信号是指数,那么怎么建都不平缓。一般来说,信号不会增长太快,一般物理规律,信号不会增长太快。 #F= 1 dt 0.5*dt^2 #F是一个矩阵,在计算中要注意行向量和列向量。 # 0 1 dt # 0 0 1 #H=[1 0 0] #Q = Q2 0 0 #Q是一个噪声的协方差矩阵,Q协方差是用来描述他们随机变量的噪声的相互关系。由于状态变量X是由3个元素组成,Xk,Xk',Xk'',他们是多维随机变量,有各自的方差。而他们之间的关系,若两个随机变量的相关性为0,那么他们是不相关,若Xk增大了,Xk’是否会有变化,这需要用协方差来表述。 # 0 Q3 0 # 0 0 Q4 dt = t[2]-t[1] F2 = np.mat([[1,dt,0.5*dt**2],[0,1,dt],[0,0,1]]) #此处要注意矩阵是否病态,若dt特别小,易导致矩阵病态或精度丢失 H2 = np.mat([[1,0,0]]) Q2 = np.mat([[1,0,0],[0,0.01,0],[0,0,0.001]]) R2 = 20 #只有一个观测,所以只有是标量,如果有多个观测,得写成矩阵形式。 #设置初始值 Xplus2 = np.matrix(np.zeros((3,L))) Xplus2[0,0]=0.1**2 Xplus2[1,0]=0 Xplus2[2,0]=0 Pplus2=np.mat([[0.01,0,0],[0,0.01,0],[0,0,0.0001]]) #一般来说,初始得协方差矩阵都写成是对角矩阵形式。 #K2 = np.mat(np.zeros((3,1))) for i in range(1,L): #预测步 Xminus2[:,i]=F2*Xplus2[:,i-1] Pminus2=F2*Pplus2*F2.T+Q2 #更新步 K2=(Pminus2*H2.T)*np.linalg.inv(H2*Pminus2*H2.T+R2) Xplus2[:,i]=Xminus2[:,i] +K2*(y[i]-H2*Xminus2[:,i]) Pplus2=(np.identity(3)-K2*H2)*Pminus2 Xplus2_0=np.zeros(L) for i in range(L): Xplus2_0[i]=Xplus2[0,i] plt.plot(figsize=(20,12)) plt.plot(t,x,'r') plt.plot(t,y,'g') plt.plot(t,Xplus1,'b') plt.plot(t,Xplus2_0,'m') # 可以进行在线滤波,实时滤波 ### 问题2,两个传感器,进行滤波 ### # Y1(K) = X(K)+R # Y2(K) = X(K)+R # H=[1 1]T (列向量) X=X(K) # H=[[1 0 0], [1 0 0]]
模型2 中预测方程为:X(K)=X(K-1)+X'(K-1)*dt+X''(K-1)*dt^2*(1/2!)+Q2,可以将其分解为:
X'(K)=0*X(K-1)+X'(K-1)+X''(K-1)*dt+Q3
X''(K)=0*X(K-1)+0X'(K-1)+X''(K-1)*dt+Q3
X'''(K)=X''(k-1)+Q3
用矩阵表示为 Xk- = F*Xk-1
#F= 1 dt 0.5*dt^2 #F是一个矩阵,在计算中要注意行向量和列向量。
# 0 1 dt
# 0 0 1
3)卡尔曼滤波的扩展
预测方程和观测方程的框架不变都是
预测方程:Xk = f(Xk-1) + Q
观测方程:Yk = h(Xk) + R
在普通卡尔曼滤波时,假设f(Xk-1) 和h(Xk) 是线性的。f(Xk-1) = F*Xk 和 h(Xk) = H*Xk,其中F和H是系数。所以带入预测步,得到f(v) = F*v,以及带入更新步,得到h(x) = H*x。最终得到他们的期望,方差和增益,5个等式。
 --》
--》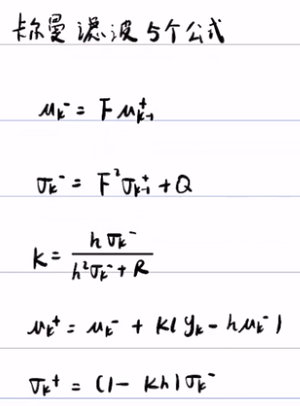
而在扩展的卡尔曼滤波时,假设f(Xk-1) 和h(Xk) 是非线性的。f(xk-1)=f'(xk-1)Xk-1+f(xk-1+)-f(xk-1+)xk-1+=AXk-1+B,带入到了预测步,并利用软件计算
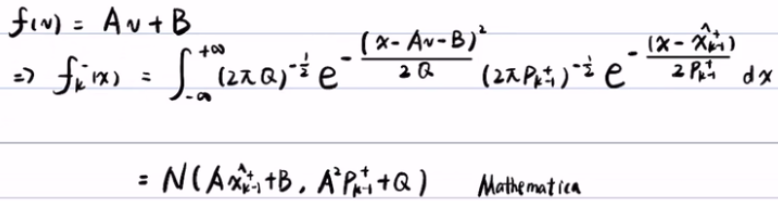 -软件->
-软件-> 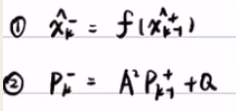
EKF算法的总结:
- 设Xk-1服从N(xk-1+, Pk-1+)的正态分布。
- 预测步:先算A,再通过上一步的期望和方差,推出这一步的期望和方差
- 更新步:先算C,再算EKF增益,然后再算后验的期望和方差。

第二讲 随机过程与主观概率
随机试验的定义,满足以下三个条件为随机实验:
1. 在相同条件下,试验可重复进行,即随机试验之间的独立性(如:抛硬币,第一次和第二次抛硬币之间没有任何影响,这样才能保证随机实验可重复进行,这样才可以通过多次实验来给概率赋值。若随机实验的独立性没有了,则无法再通过大数定律给概率赋值。)
2. 一次试验,结果不确定,所有可能的结果已知,
3. 试验之前,试验结果预先未知。所以无随机试验,就无法对概率赋值。
由于随机过程中的随机变量是不独立的,一般来说是无法做随机实验的,也就无法对概率赋值,但如果有了随机变量间的关系,且有了初始值,还是可以做随机试验的。即便如此,还得分情况,如果是与时间相关的随机过程是无法做随机试验,如股票,分子扩散,气温变化等(无法创造出随机实验的环境)。
概率分成两个学派:主观概率(贝叶斯学派)和大数定律(用频率代替概率,频率学派)
贝叶斯滤波的基本思想:引入外部的观测(证据、信息),来对主观的概率进行修正或更新。即主观概率(先验概率(先于实验之前的概率))通过外部观测(即贝叶斯公式),变为相对客观的概率,称这个概率叫做后验概率(实验之后的概率)
第三讲 贝叶斯滤波的三大概率
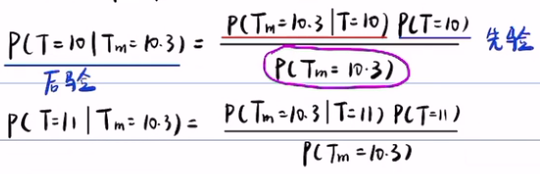
先验概率靠猜(主观判断),后验概率靠测(测量结果推导出来),这两个概率分布之和都必须等于1,而似然概率则不需要,它只表示传感器的精度,与误差有关,而与真实温度。
1. 先验概率:没有做实验,通过学习等途径,得到的概率。包括主观概率(靠猜)
2. 后验概率:主观概率(先验概率(先于实验之前的概率))通过外部观测(即贝叶斯公式),变为相对客观的概率,称这个概率叫做后验概率(实验之后的概率)
3. 似然概率:似然概率代表着观测/传感器的精度,它衡量的是传感器的误差概率,叫似然概率。似然概率与先验/后验概率不一样,它在不同的真实值情况下的测量结果的概率无需加总为1。似然概率只是表示传感器的精度,只与传感器本身的误差有关,而与温度的真实值无关,不受其影响。例如:温度计的误差有可能是正负0.1,那么P(Tm=10.3|T=10),真实温度为10的条件下,测量温度为10.3的概率就非常小,因为误差为正负0.1,那么真实值应该在10.2到10.4之间,所以Tm=10.3,而真实的值为10的概率很小。然而如果误差为正负0.5,那么P(Tm=10.3|T=10)就很大了。它是对两个不同真实值,进行不同的测量,他们两个不同的事件,所以他们之间的概率没有任何关系。
4. 最后,随机变量的取值与随机变量的分布概率无关,这对P(Tm=10.3)是一个常数起着至关重要的作用。因为P(Tm=10.3),即测量值为10.3是一个结果,随机变量的概率分布对其无关(即,抛硬币,正面/反面朝上只是一次抛硬币的结果,与其概率分布(0.5)无关)。P(Tm=10.3)可以通过全概公式得到,如果先验概率定了,且似然概率也定了,那么P(Tm=10.3)的概率也就定了,是一个常数。
既然P(Tm=10.3)是一个常数(设这个常数为η),我们可以把上面这个贝叶斯公式进行改写:后验=η*似然*先验。所以常数η=1/Σ先验*似然。
第四讲 连续随机变量的贝叶斯公式
状态看成原因,观测看成结果,要先有状态,才能有观测,所以说状态是因(温度,Y),而观测是果(测量值,X)。
后验概率就是由果推因(观测值->真实值的概率),看到了观测得结果,去推出最有可能的原因是什么?观测值是10度,那么它最有可能的状态(真实值),是11度的概率多大,是10度的概率是多大,还是9度的概率多大呢?
似然概率是由因去推果(真实值->观测值的概率),真实的温度是10度,看导致观测值是10度的概率,观测值是11度的概率呢?
连续随机变量的贝叶斯公式: 
先验概率:fx(x)
似然概率:fy|x(y|x),由因(X)推果(Y)
后验概率:先验概率*似然概率 = fx|y(x|y) = fy|x(y|x) * fx(x) / fy(y)= f(x,y)/f(y)
f(x,y) 的边缘密度为:fx(x) = ∫ f(x,y)dy, fy(y) = ∫ f(x,y)dx。
最后连续变量的贝叶斯公式:P(X<x|Y=y) = fX|Y(x|y) = η*fX|Y(y|x)*fX(x),其中 η = fY(y) 是一个常数。

第五讲 似然概率与狄拉克函数
引例:测温度
第一步,先猜一个先验概率密度,猜它是服从N(10,1)的正态分布。fx(x)~N(10,1),其中,期望是对温度的猜测,即猜测10度的概率最大,而方差是对主观猜测的误差。通过温度计测的的观测值为9度:y=9。如果有了先验概率,再得到似然概率,根据贝叶斯公式就可以算出后验概率。
第二步,要求解似然概率 fY|X(y|x),就是要求解P(Y<y|X=x)的概率密度(pdf),那么就是对P(Y<y|X=x)求导,即对∫ fY|X(y|x)dy 求导,但这个积分求完后是一个关于x 的函数 f(x),求导后为0。所以我们 要做一个转化:将这个似然概率的密度 fY|X(y|x),乘以一个很小的数 ε,这样的话,它就有明确的意义了,它代表的就是P(y<Y<y+ε|X=x),即在X=x的情况下,y<Y<y+ε的概率,即传感器的精度。![]()
所以说似然概率就是![]() (由中值定理可得:P(y<Y<y+ε|X=x)=fY|X( ξ1|u) * ε)。
(由中值定理可得:P(y<Y<y+ε|X=x)=fY|X( ξ1|u) * ε)。

这个积分的意思:当真实值(X)取x的时候,你的观测值(Y)误差在正负0.2,即正负ε,之间,和似然概率密度fy|x(y|x)围成的面积是1。红色的竖线代表fy|x(y|x),即似然概率密度。但要求似然概率密度还要通过假设似然概率的模型:等可能型,阶梯型和正态分布型(正态分布的好处:1.期望和方差独立,相对好控制(可以独立调整)。2. 中心极限定理:传感器的误差的来源相互独立的话,那么他们误差叠加的平均值就会满足正态分布)。
假设先验概率满足期望是10,方差为1的正态分布模型:![]()
观测值为9,即u=9,精度为0.2,即σ=0.2,由于似然概率概率为![]()
第三步,后验概率是通过先验概率与似然概率相乘,然后对后验概率做无穷积分,然后算出η ,最后的到后验概率。后验概率=(先验*似然概率)/f(y)= fx|y(x|y) = f(x,y)/f(y) = fy|x(y|x)*f(x)/f(y) = η*fy|x(y|x)*f(x) ![]() =1, 其中f(y) = η(常数)。
=1, 其中f(y) = η(常数)。
由于归一化,所以: ![]()
最后得出后验概率为:![]()
后验概率是通过先验概率与似然概率相乘,然后对后验概率做无穷积分,然后算出η ,最后的到后验概率
![]()
方差有明显的降低,不确定性减小,从而达到滤波的效果。
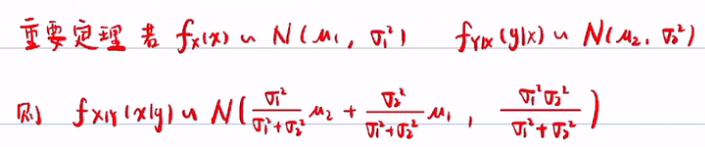
重要定理:若先验概率服从正态分布:fx(x)~N(u1,σ12),且似然概率也服从正态分布:fy|x(y|x)~N(u2,σ22),那么后验概率就会服从正态分布。后验概率的重要定理中u1与u2前面的系数相加为1,说明他们的系数为权重,u1和u2哪个方差大,占的权重就小(可以通过暴力证明)。所以若σ12远大于σ22,那么后验概率就近似服从N(u2,σ22),反之亦然。
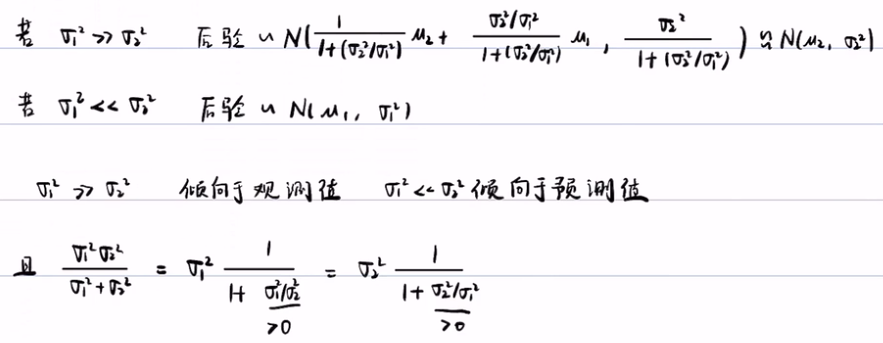
得到结论:σ12》σ22 时,后验概率倾向于观测值,而σ12《σ12时,后验概率倾向于预测值(先验概率)。并且,后验概率的方差中分别提取了σ12和σ22,新的滤波方差比原来的任何一个方差都要小,这带来一个很大的好处:尽可能削弱先验概率的影响,只要观测足够准确的话,你的后验概率的方差就可以非常的小,因为后验概率比先验概率和似然概率的方差任何一个都要小。哪怕预测和观测都不是很准,且似然概率的方差无论大/小,后验概率都可以通过滤波,都能得到相对准确,且比较小的方差。
方差越小,正态分布的区间就越短,当方差趋于0,曲线在期望上趋于无穷,而其他地方都是0,所以狄拉克函数是是一个陡峭的曲线。 狄拉克函数 δ(x) 的定义是当x=0的时候δ(x)=oo,而x != 0的时候,δ(x)=o。而狄拉克函数的积分为1(归一化):∫δ(x)dx=1。狄拉克函数最重要的特征是选择性:∫ f(x)*δ(x)dx =f(0),看上去就像是用积分把f(0)选出来一样,因为f(x)只有在x=0的时候f(x)!=0,其他积分都等于0。
第六讲 随机过程的贝叶斯滤波
1. 简介:随机过程的贝叶斯滤波。在随机过程中,有多个随机变量x,且不独立,有一个初始值x0(靠猜),有k个观测值y1,y2,...yk对应于每个变量。

2. 求解随机过程的解决方法:
- 1. 对所有的 x0... xk的先验概率都靠猜。
- 2. 只有x0的概率式猜的,X1....Xk的先验概率是递推的。
3. 贝叶斯滤波的步骤
随机过程的贝叶斯滤波的状态方程和观测方程

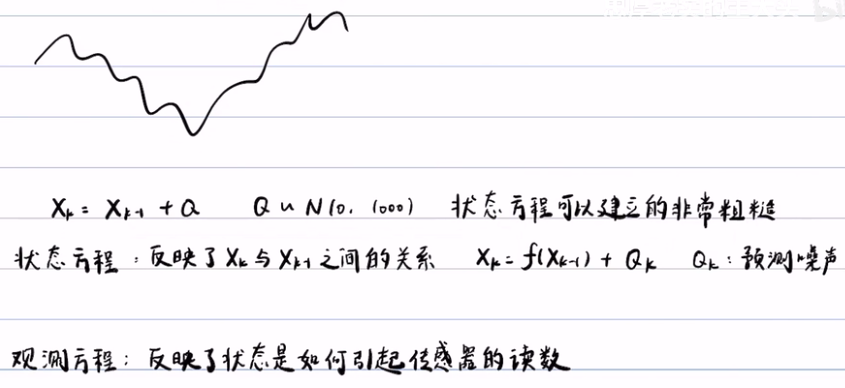
- 状态方程(预测方程)反映了Xk与Xk-1之间的关系, Xk=f(Xk-1) + Q,而Q是预测噪声。
- 观测方程就可以写成:Yk=h(Xk)+Rk,表示状态如何引起的传感器的读数Yk。
如何递推?贝叶斯滤波的基本思想:

首先设置初始值X0 ~ N(0,1),对这个状态方程做预测(预测步),得到X1-~N(0,22),若没有观测的话,直接利用X1-~ N(0,1),去做预测,那么方差会越来越大,所以观测从这里开始引入(更新步),利用传感器所采集到的数据,对先验的数据进行更新(更新方法就是利用贝叶斯公式进行更新:后验=先验*似然(观测)),得到X1+~ N(0,0.8)。再利用后验概率X1+ 做为下一步得先验概率进行在预测,得到X2-~ N(0,3.2),再根据观测数据Y2,对X2-进行再更新,得到X2+,以此类推。

X0+~N(0,1) --预测步(通过状态方程X1=2*X0)--> X1--~N(0,22) --更新步/后验步(观测方程:后验=先验*似然N(0,0.8))-->X1+~N(0,3.2) --再预测(状态方程)--> X2-~N(0,6.4)
递推分两步,第一步是预测步,是上一时刻的后验概率,通过状态方程,求出这一时刻的先验概率;第二步叫更新步,这一时刻的先验概率,通过观测方程以及观测数据,推出这一时段的后验概率,这一时刻的后验概率可以被当作下一时刻的先验概率。
4. 贝叶斯滤波算法:
贝叶斯滤波的前提(原料和条件):

具体步骤:
1) 预测步(求先验概率):
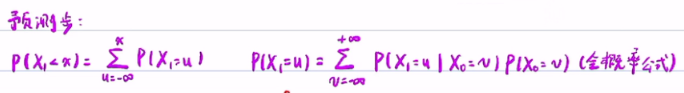
- 利用离散转连续的方式:P(X1<x)=ΣP(X1=u),其中u是变量属于(-oo,x)。
- 而通过全概公式:P(X1=u)=P(X1=u|X0=v)*P(X0=v)。

- 由于X0=v,所以可以条件概率的等式两边,同减去f(X0)和f(v)。 并将将状态方程带入,整理后,得到
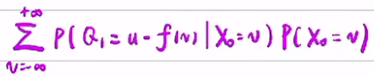
- 已知Q1与X0是独立的,所以可以将X0=v从条件概率中取出,得到P(Q1=u-f(v)|X0=v)=P(Q1=u-f(v)。
- 利用中值定理(P(Q1=u-f(v)=fQ1[u-f(v)]*ε,p(X0=v)=f0(v)*ε)
- 随机变量的概率公式:P=∫ f(x)*ε,其中ε 趋向于0。将概率化为概率密度乘以ε,然后再取极限。
所以P(X1<x)的公式可得(上式漏掉一个ε,而下式中u属于(-oo,x),而不是(-oo,+oo)):
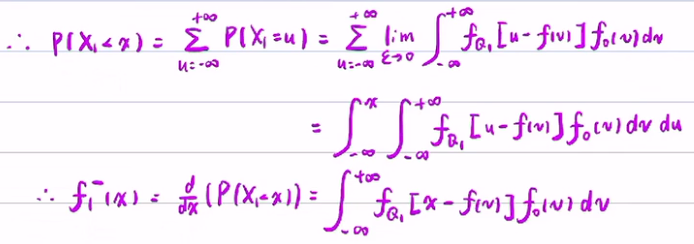
2) 更新步(求似然概率):
观测方程和更新步,主要是求似然概率

将观测方程带入,得P(y1-h(x)<Y1-h(x1)<y1-h(x)+ε)。

总结:递推公式推到过程。

f0(x) --预测步(通过状态方程)--> f1-(x) --更新步/后验步(通过观测方程,且后验=先验*似然)--> f1+(x) --预测步(通过状态方程)--> f2-(x)。
注:f1得后验概率与f2得后验概率是不相等的,所以他们的η也不一样。
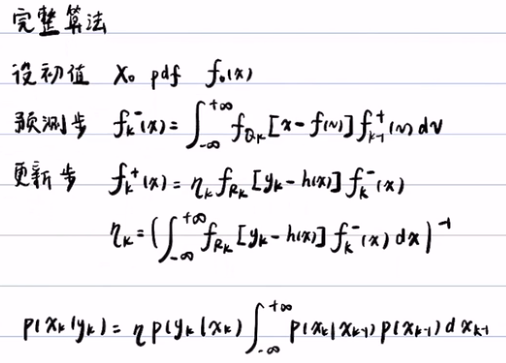
预测步就是求先验概率,而更新步就是求似然概率,并求η。得到先验概率,似然概率和常数η,就可以得到后验概率。
贝叶斯滤波只是思想,虽然看上去算法很完美,但缺点就是无穷积分,在大多数情况下无法解析。
第七章 贝叶斯滤波与卡尔曼滤波
1. 贝叶斯滤波:
1) 状态方程和观测方程,以及他们得前提假设:X0,Q1...Qk,R1...Rk相互独立
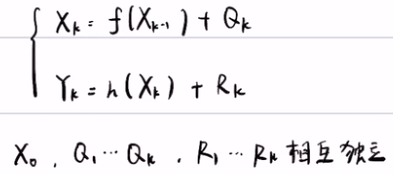
2) 贝叶斯滤波得三个公式:

2. 卡尔曼滤波
1)相对于贝叶斯滤波,多了几个假设:
- f(x)与h(x)都是线性函数
- fQ(x)与fR(x)都是服从正态分布。

2)预测步(求先验概率):根据贝叶斯滤波,第一步是写出预测 步公式,然后将相应得概率密度带入积分就行了。最后得到 u-k和σ-k。
3) 更新步(求似然概率):已知fk-(x)服从正态分布,那么fk+(x)后验概率就是常数 η 乘以似然概率 fR(yk-h*x)和先验概率fk-(x)。
利用数学公式去算,得到一个随机变量Xk+,但这个随机变量服从一个比较复杂的正态分布。通过变形得到uk+和σk-。

得到卡尔曼滤波的五个公式:预测步2个,更新步2个,外加卡尔曼增益。分别是代表从k-1的后验,通过两个独立的正态分布相加,推导出k的先验,再利用k的先验乘以似然概率(两个正态分布相乘再乘以常数η),推导到k的后验(其结果也是正态分布)。卡尔曼滤波之所以简单就是无需算积分,通过对期望和方差的计算,无需知道后验概率是什么形式。
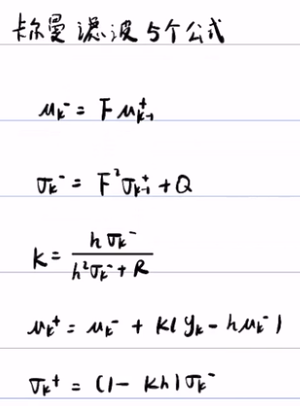
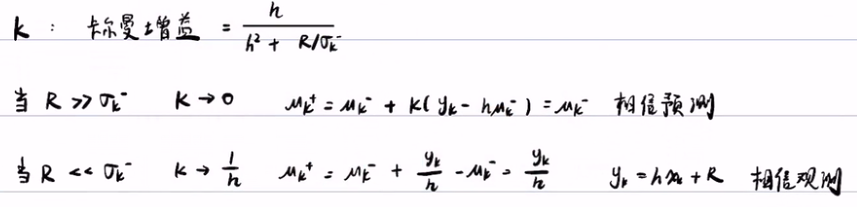
第一讲绪论
1. 基本概率
HMM -- 隐马尔可夫模型
MCMC -- 可尔科夫-蒙特卡罗方法
马尔可夫链:未来与现在有关,而与过去无关。
MAP -- 最大后验估计
最小均方差估计
贝叶斯滤波

第二讲 随机过程与主观概率
1. 基本概念
贝叶斯滤波的基本思想:通过概率统计的方法,利用贝叶斯公式,对随机信号进行处理,然后减小它的不确定性。
随机过程:x1,x2,x3....xn,其中x1,x2..xn..是一组随机变量,且彼此之间不独立的。(就无法做随机实验了。)
确定过程:v=gt(重力加速落体),通过重力加速度公式可以推出确定的过程:v1=g, v2=2g, v3=3g, .... vn
概率论和统计(大数定律、中心极限定理,数理统计(三大分布:卡方分布、T分布、F分布)等 )都是以iid为前提的,但随机过程中的随机变量相互不独立,把独立性给去掉了,就无法做随机实验了。
2. 随机试验是什么?随机试验没了之后又什么影响?
随机试验是概率论的基础,它的最大的作用是个概率赋值的。比如,抛硬币,正面/反面朝上的概率是0.5。即怎么给一个概率事件赋一个数。赋值方法又两种:1.主观概率:概率是由主观定的,不是客观的东西,如:我自己主观认为抛硬币正面朝上的概率是0.5,2.大数定律:通过大量试验,得到正面朝上的次数与总次数之比,即正面朝上的频率,通过看次数增多的时候,看频率的趋势,抛硬币的正面朝上的频率在0.5附加波动,说明概率是0.5。第二种方法的基础就是随机试验。大数定律的例子如下(通过大量实验,当n(实验次数)趋向于+oo时,u/n(频率)依概率收敛于P1(0.5),所以说这个频率0.5是这么来的,是通过大量实验做出来的。):

随机试验的定义,满足以下三个条件为随机实验:
1. 在相同条件下,试验可重复进行,即随机试验之间的独立性(如:抛硬币,第一次和第二次抛硬币之间没有任何影响,这样才能保证随机实验可重复进行,这样才可以通过多次实验来给概率赋值。若随机实验的独立性没有了,则无法再通过)
2. 一次试验,结果不确定,所有可能的结果已知,
3. 试验之前,试验结果预先未知。所以无随机试验,就无法对概率赋值。
随机过程:x1,x2,x3...xn 不独立,所以无法做随机试验,一般来说与时间相关无法做随机试验,如股票,分子扩散,气温变化等。这些随机过程是无法创造可以重复实验的环境出来。

随机过程:x1,x2,x3...xn.随机变量之间是 不独立,如果我们找到了xk与xk-1之间关系,那么就可以找到p(xk)与p(xk-1)之间的关系。但还需要一个这个随机过程的起点,即x1。否则,你只是知 道他们之间的关系,而没有初始值,仍然不能研究这个随机过程。即随机变量不独立,虽有了随机变量间的关系,但初值的选取很重要。

由于不独立性,所以没有办法通过大数定律给P(x1)一个初始值(无法定初始值),但这也得分情况看。
1. 有些随机过程,是可以主观给一个初始值,则是可以做随机试验的,比如说:随机游走:Xk=Xk-1+D,这个随机游走,有1/2的概率往前走,也有1/2的概率往后走。那么Xk与Xk-1代表着不同时间段,随机游走的位移。这是一个随机游走的过程,可以主观上设置初始值P(x0=0)=1。(独立性是不能通过逻辑来证明,P(AB)=PA*PB,公式中的PA和PB要通过概率赋值,这就牵扯到了随机实验,是否独立是做随机实验的关键。)
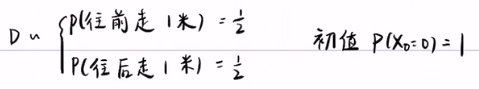
2. 有的初始值是不可以做随机实验的。那就只能使用主观概率,猜一个大致得概率。例如,我们找到了随机变量间得关系,但由于选取初始值是主观的,所以不同的主观概率导致不同的结果。

如 分子扩散、气温变化等过程本质上是客观过程,不是主观的东西,我们希望尽可能削弱这个主观概率的差异,可以有多种方法解决这样的问题,如贝叶斯滤波。
3. 贝叶斯滤波
贝叶斯滤波的基本思想:引入外部的观测(证据、信息),来对主观的概率进行修正或更新。即主观概率(先验概率(先于实验之前的概率))通过外部观测(即贝叶斯公式),变为相对客观的概率,称这个概率叫做后验概率(实验之后的概率)

主观概率与先验概率的区别:先验概率可以通过看书或学习,大致得到一个概率,这种概率不是猜的,所以它不是主观概率,但是没有做实验,所以是先验概率。在此课程里,不区分主观概率与先验概率,视为等同。
第三讲 贝叶斯概率的三大概率
1. 先验概率:没有做实验,通过学习等途径,得到的概率。包括主观概率(靠猜)
2. 后验概率:主观概率(先验概率(先于实验之前的概率))通过外部观测(即贝叶斯公式),变为相对客观的概率,称这个概率叫做后验概率(实验之后的概率)
概率知识回顾,及用于规范:
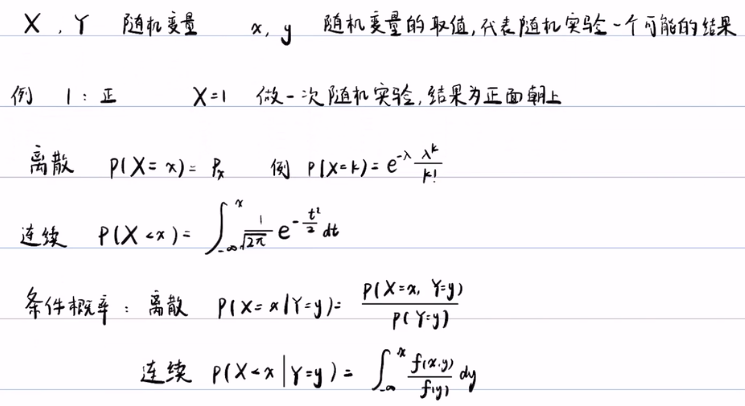
3. 似然概率
引例:测温。首先,若无测量工具,就要猜一下今天的温度,即猜一个先验概率P(T=10)=0.8。但还要给出一个完整的先验概率分布,10度的概率是0.8,而11度的概率是0.2,即 ΣP(X=10) + ΣP(X=11) = ΣP(X=x) = 1(对于连续随机变量,其概率密度积分为1。如果给的是离散的先验概率,就要把完整的先验概率分布写出来),其次,利用设备测量,得到后验概率,但测量设备的精准度及测量误差等因素,会导致测量结果的偏差,从而观测结果不一定是真实结果,它也具有不确定性。所以才引入了第三个概率,似然概率。

首先,先验概率分布为,主观感觉温度为10度的概率P(T=10)为0.8,而主观感觉温度为11度的概率P(T=11)为0.2,先验概率分布的总和为1。
其次,观测到的测量结果Tm为10.3度,与先验概率一样,后验概率也是一个概率分布,所以它的概率分布总和为1,即P(T=10|Tm=10.3)+P(T=11|Tm=10.3)=1。但温度计有误差概率,所以引入了似然概率。

第三,似然概率代表着观测/传感器的精度,它衡量的是传感器的误差概率,叫似然概率。温度计的误差有可能是正负0.1,那么P(Tm=10.3|T=10),真实温度为10的条件下,测量温度为10.3的概率就非常小,因为误差为正负0.1,那么真实值应该在10.2到10.4之间,所以Tm=10.3,而真实的值为10的概率很小。然而如果误差为正负0.5,那么P(Tm=10.3|T=10)就很大了。
似然概率与先验/后验概率不一样,它在不同的真实值情况下的测量结果的概率无需加总为1,因为P(Tm=10.3|T=10) 的本质意思是真实值是10的时候,测量温度为10.3的概率,而P(Tm=10.3|T=11)的本质意思是真实值是11的时候,测量温度为10.3的概率。所以说它是对两个真实值做的不同的测量,他们是两个不同的事件/随机试验,他们的概率没有关系。所以似然概率只是表示传感器的精度,只与传感器本身的误差有关,而与温度的真实值无关,不受其影响。
最后,随机变量的取值与随机变量的分布概率无关。这对P(Tm=10.3)是一个常数至关重要。

P(Tm=10.3) 代表观测值为10.3的概率。教程中,经常认为P(Tm=10.3)与T无关。但其实不然。
我们假设温度计测量的温度为10.3, 那么温度为10.3 不是一个已发生的事件吗?所以P(Tm=10.3) 观测值为10.3的概率应该等于1。这样的疑惑是因为把随机变量的取值与随机变量的概率搞混了。如抛硬币,不能把一次正面朝上的结果看成是随机变量的概率,正面朝上只是随机试验的其中一个结果而已,不能把这一次的结果就把它当成是事件的概率,这一次的结果不能改变抛硬币的随机性的性质(也就是说随机事件:正面朝上和反面朝上的概率是0.5),不能把这个结果看成随机变量的概率,所以说随机变量的取值与随机变量的分布率没有关系。随机变量的取值代表一次随机试验的可能的结果,而随机变量的分布率代表你对随机变量的不确定性程度的刻画。
可以利用全概率公式来计算P(Tm=10.3)的概率:P(Tm=10.3) = P(Tm=10.3|T=10)P(T=10) + P(Tm=10.3|T=11)P(T=11)。公式的含义:Tm=10.3,它是结果,T=10,T=11,它是原因。这个全概公式的含义是:当真实值T=10或T=11的时候,测出的温度为Tm=10.3的概率之和,即P(Tm=10.3) 等于T=10的概率乘以传感器的精度+T=11时乘以传感器的精度。

P(Tm=10.3)是一个常数,是因为测试温度的概率P(Tm=10.3)与T 的取值无关,与T的分布律有关。 因为T的分布律时不会受实验的结果所影响,正如:抛硬币,无论是正面还是反面,它都不会影响它的分布率。T的分布率是先验概率,即实验前定的/猜的;而似然概率属于传感器的精度,它属于传感器本身固有的性质,所以说似然概率也是客观存在。如果先验概率定了,且似然概率也定了,那么P(Tm=10.3)的概率也就定了,是一个常数。
既然P(Tm=10.3)是一个常数(设这个常数为η),我们可以把这个贝叶斯公式进行改写:后验=η*似然*先验。

第四讲 连续随机变量的贝叶斯公式
1. 似然概率得概念:
问:为什么叫把准确度叫做似然概率?
这是从最大似然估计那里借来的概念,似然的英语为likelihood,意思叫可能性,似然还有一个意思叫相似,相像,似然概率表示当我的观测值为10.3时,他最有可能,最像是哪个原因引起的,我们认为是因为有温度客观存在,才有对温度的观测,温度是因,观测是果,如果后验概率是说已知观测结果问原因的话,似然就是问哪个原因最像是引起观测是10.3这个结果,所以后验概率:T在条件概率前面,Tm在后面,表示已知结果问原因,而似然概率相反,T在后面,表示已知原因问结果。

从A/B班抽一个人出来,观测结果是一个女孩,这个女孩有可能从A班或B班出来,最大似然得意思就是这个女孩最大得可能是从B班出来。而后验概率就是知道这个女孩是从A/B班出来的,去寻找什么原因导致的(由果推因)。
2. 后验与似然的因果关系

一般把状态看成原因,观测看成结果,要先有状态,才能有观测,得先有温度,才可以观测。所以说状态是因,而观测是果。
后验概率就是由果推因(观测值->真实值的概率),看到了观测得结果,去推出最有可能的原因是什么?观测值是10度,那么它最有可能的状态(真实值),是11度的概率多大,是10度的概率是多大,还是9度的概率多大呢?
似然概率是由因去推果(真实值->观测值的概率),真实的温度是10度,看导致观测值是10度的概率,观测值是11度的概率呢?
3. 独立未必没有函数关系
如果两个随机变量存在一定的函数关系,他们是不是一定不独立?
答:不一定。
等价命题:如果两个随机变量相互独立,他们是不是一定没有函数关系?
答:不一定。
独立,无关,没有影响。
独立,但又函数关系:1.必然事件,2. 随机事件中正态分布的 u 和 σ 就是独立,但有函数关系。而且只有在正态分布上有这个得关系,在其他分布上是没有这样得关系的。

证明:https://www.bilibili.com/video/av63950352/
4. 连续随机变量的贝叶斯
贝叶斯公式无法直接运用于连续随机变量,要将连续变量化积分为求和,即化积分的区域(-oo,x)为Δx点的累加求和。

连续随机变量X,Y的某个点的概率为0,即P(X=x)=0 或 P(Y=y)=0,严格来说不是0,算是无穷小,可以将无穷小写成极限的形式,这样就可以将离散的表达形式转化为积分形式:
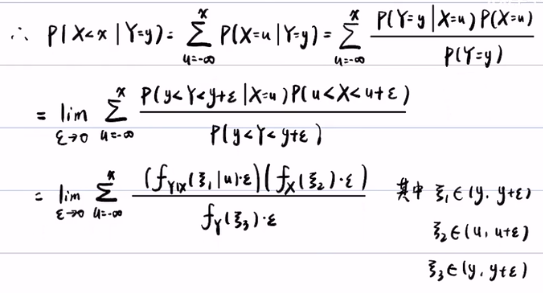
P(y<Y<y+ε) = ∫ fY|X(y|u)dy -写成中值定理的形式-> fY|X( ξ1|u) * ε,其中ξ1属于(y,y+ε)。
中值定理:如果函数f(x)满足:(1)在闭区间[a,b]上连续;(2)在开区间(a,b)内可导;那么在开区间(a,b)内至少有一点 使等式
使等式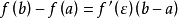 成立。上式转化中ξ1,ξ2,ξ3采用了中值定理。
成立。上式转化中ξ1,ξ2,ξ3采用了中值定理。

先验概率:fx(x)
似然概率:fY|X(y|x)
后验概率:先验概率*似然概率 = fx|y(x|y) = fy|x(y|x) * fx(x) / fy(y)= f(x,y)/f(y)
f(x,y) 的边缘密度为:fx(x) = ∫ f(x,y)dy, fy(y) = ∫ f(x,y)dx。
最后连续变量的贝叶斯公式:P(X<x|Y=y) =求导=》 fX|Y(x|y) = η*fX|Y(y|x)*fX(x),其中 η = fY(y) 是一个常数。

第五讲 似然概率与狄拉克函数
例子:测温度,先给一个先验的概率密度,数学期望是10,方差为1的标准正态分布。这样就意味着x=10的概率最大,方差是对你猜的不确定性的把握,方差就是误差的精度,这里的方差是1,所以容错的空间为[9,11]。本例中观测的温度为9度。如果有了先验概率,再得到似然概率,根据贝叶斯公式就可以算出后验概率。
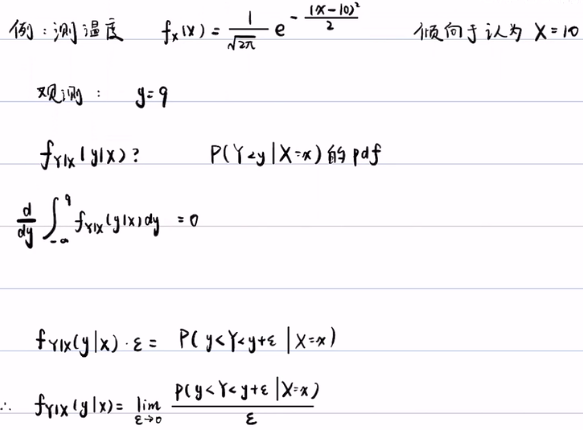
例子中要求解似然概率 fY|X(y|x),就是要求解P(Y<y|X=x)的概率密度(pdf),那么就是对P(Y<y|X=x)求导,即对∫ fY|X(y|x)dy 求导,但这个积分求完后是一个关于x 的函数 f(x),求导后为0。所以我们要做一个转化:将这个似然概率的密度,乘以一个很小的数 ε,这样的话,它就有明确的意义了,它代表的就是传感器的精度。
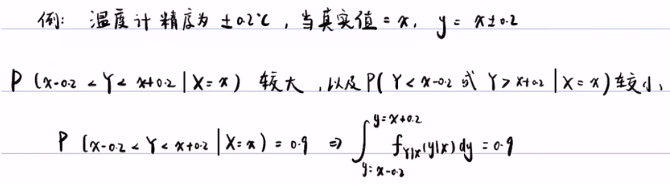
y=x+-0.2 的意思就是观测值在0.2上下波动。利用概率的语言表述就是在X=x的情况下,Y在(x-0.2,x+0.2)区间的概率较大,而在这个区间之外的概率较小。即,在真实值 (X) 等于x的情况下,观测值(y)在0.2上下波动的概率很大。其实说的就是传感器的精度。0.9代表传感器的精度,表明还有10%的可能,误差超出0.2的范围。
这个积分的意思:当真实值(X)取x的时候,你的观测值(Y)在正负0.2之间,和似然概率密度fy|x(y|x)围成的面积是1。红色的竖线代表fy|x(y|x),即似然概率密度。这个似然概率密度 fy|x(y|x) 具体是什么值,一般来说是不知道的,一般来说传感器的精度是正负0.2或0.3,这样一个精度的范围,通过这个精度0.2/0.3,也只能推导似然概率密度的面积等于1,这一步,不能求出似然概率密度fy|x(y|x)具体等于多少。 只能通过人为假设似然概率模型,再继续往下算。以下为似然概率的模型:
- 等可能型:它所有的概率都相等。当真实值X=x的情况下,Y在[x-0.2,x+0.2]的区间内取得每一个值都是相等的,而超出部分概率为0。说明Y服从均匀密度,即 fy|x(y|x)=C 。∫fy|x(y|x) = 1 => C=2.5 ==》 |y-x|<=0.2时,似然概率fy|x(y|x)=2.5,而当|y-x|>2的时候,似然概率fy|x(y|x)=0。

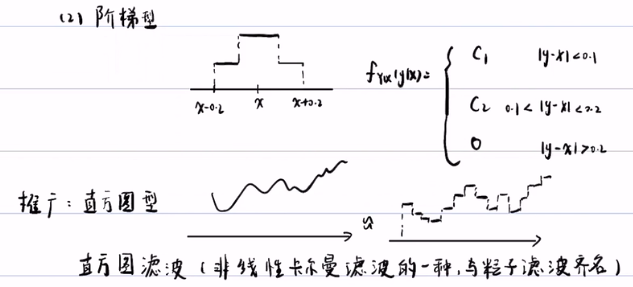
- 阶梯型:它的概率密度也是常数,但它的概率密度是分段的常数,它的精度是分段的,越靠近真实值,它的概率就越大,远离真实值,它的概率就越小。阶梯型更靠近真实情况。
- 直方图型:这是阶梯型的推广,就是将非线性的概率密度,模拟成多个阶梯型的叠加。化连续为离散型。这样做的好处就是积分比较好积。
- 直方图滤波:由直方图型可以发展出一个直方图滤波(它是非线性卡尔曼滤波的一种),这个模型的优点在于便于积分,它可以把概率密度分成很多段的常数,常数是很好积分的,特别是概率密度的非线性比较复杂。
- 正态分布型:以真实值为期望,0.2为方差的正态分布曲线,但这样的话,Y在[x-0.2,x+0.2]之间的积分会小于1。一般来说,方差就取传感器的精度。正态分布好处:
- 正态分布的均值和方差比较好控制,其期望和方差没有什么关联(独立的)。而不像均匀分布,它的期望和方差就不好控制,它的期望定了,方差也就定了,它的E(x)=x,而D(x)=0.42/12 != 22.
- 中心极限定理,只要误差是独立的,及泊松分布相互独立,有大量的误差累积,它的平均值就会满足这个正态分布。因为我们认为似然概率就是反映传感器的误差,那么传感器的误差的来源相互独立的话,那么他们误差叠加的平均值就会满足正态分布。

续前面正态分布的例子:

假设先验概率满足期望是10,方差为1的正态分布模型:![]()
观测值为9,即u=9,精度为0.2,即σ=0.2,由于似然概率概率为![]()
后验概率=(先验*似然概率)/f(y)= fx|y(x|y) = f(x,y)/f(y) = fy|x(y|x)*f(x)/f(y) = ![]() =1, 其中f(y) = η(常数)。
=1, 其中f(y) = η(常数)。
由于归一化,所以: ![]()
最后得出后验概率为:![]()
总结:后验概率是通过先验概率与似然概率相乘,然后对后验概率做无穷积分,然后算出η ,最后的到后验概率。

方差有明显的降低,不确定性减小,从而达到滤波的效果。
后验概率的重要定理中u1与u2前面的系数相加为1,说明他们的系数为权重,u1和u2哪个方差大,占的权重就小(可以通过暴力证明)。所以若σ12远大于σ22,那么后验概率就近似服从N(u2,σ22),反之亦然。

得到结论:σ12》σ22 时,后验概率倾向于观测值,而σ12《σ12时,后验概率倾向于预测值(先验概率)。并且,后验概率的方差中分别提取了σ12和σ22,新的滤波方差比原来的任何一个方差都要小,这带来一个很大的好处:尽可能削弱先验概率的影响,只要观测足够准确的话,你的后验概率的方差就可以非常的小,因为后验概率比先验概率和似然概率的方差任何一个都要小。哪怕预测和观测都不是很准,且似然概率的方差无论大/小,后验概率都可以通过滤波,都能得到相对准确,且比较小的方差。
2. 狄拉克函数
当σ趋于0的时候,这个正态分布的似然概率就会变成狄拉克函数。

方差越小,正态分布的区间就越短,当方差趋于0,曲线在期望上趋于无穷,而其他地方都是0,所以狄拉克函数是是一个陡峭的曲线。 狄拉克函数 δ(x) 的定义是当x=0的时候δ(x)=oo,而x != 0的时候,δ(x)=o。而狄拉克函数的积分为1(归一化):∫δ(x)dx=1。狄拉克函数最重要的特征是选择性:∫ f(x)*δ(x)dx =f(0),看上去就像是用积分把f(0)选出来一样,因为f(x)只有在x=0的时候f(x)!=0,其他积分都等于0。

δ(x)的本质:实质上为必然事件的概率密度。如P(X=0)=1,这是个离散的随机变量,是个必然事件,可以把这个 离散的随机事件连续化得到P(X<x)。它的概率分布的图像是单位阶跃函数:当x=0的时候,突然抬升为1。而H(x)的导数就是狄拉克函数:δ(x)=H'(x)=dH(x)/dx。
狄拉克函数的性质:
- 1. x=0的时候,δ(x)=00。
- 2. δ(x)的在-oo到+oo的积分等于1:∫δ(x)=1.
- 3. δ(x)的选择性。
选择性的证明:

H(x)在-oo到0上是0。H(x)在0到+oo是1,则1-0=1.
推论:只要0属于[a,b],那么就满足下列的积分,即选择性。
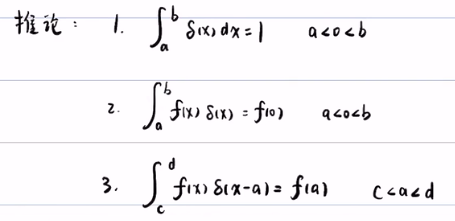
例子:
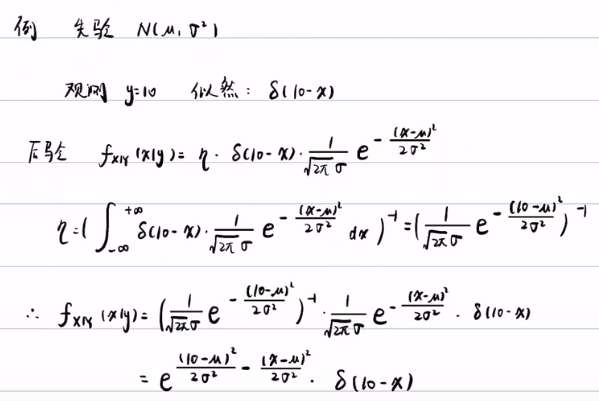
对这个后验概率进行积分,得出这个概率分布是一个必然事件,这也体现出这个传感器的精度是无限的,无论你的先验概率是怎么样的,我测到的是10,那么实际温度肯定就是10,这就是δ函数的应用。
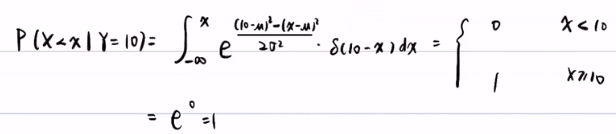
第六讲 随机过程贝叶斯滤波
前5讲,介绍了单个变量的贝叶斯滤波:通过随机变量x的先验概率和它的观测y,得到它的后验概率: 。
。
而第六讲要介绍随机过程的贝叶斯滤波。在随机过程中,有多个随机变量x,且不独立,有一个初始值x0(猜的),有k个观测值y1,y2,...yk对应于每个变量。
2. 求解随机过程的解决方法:
- 1. 对所有的 x0... xk的先验概率都靠猜。
- 缺点:过于依赖观测信息,放弃了预测信息取滤波,这样会导致无视随机过程的表达式,如这两个随机过程:xk=2xk-1+Qk,xk=xk-12+Qk ,这个方法会认为这两个表达式/随机过程是等同的。如果能写出Xk与Xk-1的关系式,哪怕是建模不准,它也是部分取反应随机过程的信息的,所以这个方法不是特别好。
- 2. 只有x0的概率是猜的,而X1....Xk的先验概率是递推的。
- 好处:保留了随机过程的特性,把Xk与Xk-1之间的关系给保留下来了。

3.贝叶斯滤波的基本思想
本文不涉及马尔可夫假设和观测独立假设,只利用状态方程和观测方程来推导贝叶斯滤波。

首先了解一下状态方程中,Xk与Xk-1是什么关系。例如:Xk=1/2*gt2+Q,Q可以认为是阻力或摩擦之类的随机扰动,可以认为是一个随机变量。我们可以利用一阶的泰勒展开,从而得到Xk与Xk-1的关系。 (泰勒公式:f(x)=f(x0)/0! + f'(x0)/1! * (x-x0)...),我们这只展开了泰勒公式的第一阶,而没有展开更高阶,这样的问题是不大,是因为可以认为把建模的误差放入到Q中,然后把Q的方差调大一点就行。
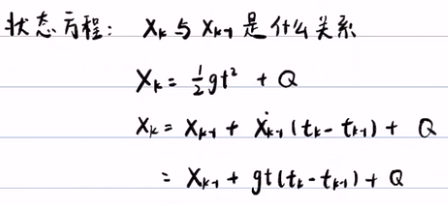
如果可以能把建模建的更精确固然是好的,但大量的问题是无法写出精确的表达式,大多数情况下,都不知道曲线有什么规律 。对于下面的曲线,我们用一个线性模型取建模是否是否合适?贝叶斯滤波的奥秘在于融合,融合先验和观测,先验是你没有做实验之前对这个问题的感性的认识,你主观认为的规律,观测是数据,数据可以给你带来信息,贝叶斯滤波就是这两个的融合。当你根本不知道这个问题是什么,或具体的形式,正如下面的曲线,无法预测随机过程或表达式,那么就贝叶斯滤波只能通过观测来帮你估一个大概的东西。只要写出一个大概的表达式出来,就有一些基本信息,贝叶斯滤波就有用武之地。
注:状态方程(预测方程)反映了Xk与Xk-1之间的关系, Xk=f(Xk-1) + Q,而Q是预测噪声。
观测方程反映了状态时如何引起传感器的读数

状态一般是你想要研究的对象,如速度,温度,角度等,状态方程一般不是我们想要的状态数据,往往是一些跟状态有关的函数数据。例如,测温度,你想测的是温度,传感器的读数也是温度,那么观测方程就可以写成:Yk=Xk+Rk,意思是状态是温度,温度Xk加上了长期误差Rk 就变成了传感器的读数Yk。
但大多数情况下,状态跟观测往往不一致,比如说状态时位移,观测是角度的传感器,那么状态方程为:Yk=arcsinXk+Rk,也就是说位移和角度一一对应,将位移转化成角度,再将角度加上一个传感器的噪声误差,才会生成传感器的读数Yk。
那么观测方程就可以写成:Yk=h(Xk)+Rk,表示状态如何引起的传感器的读数Yk。
这样就可以把上面的状态方程(随机方程 )和观测方程联立起来,表示这个随机过程怎么引起我的观测:
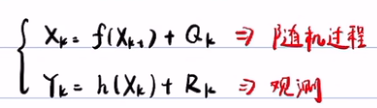
若只通过先验概率,没有观测,是无法滤波的。如下面的例子, 无观测方程,状态方程的方差越来越大,最终无法滤波。

那么我们得到联立方程,怎么引入观测来递推呢?
首先设置初始值X0+~ N(0,1),对这个状态方程做预测(预测步),得到X1-~N(0,22),若没有观测的话,直接利用X1-~ N(0,1),去做预测,那么方差会越来越大,所以观测从这里开始引入(更新步/后验步),利用传感器所采集到的数据y1=0,对先验的数据进行更新(更新方法就是利用贝叶斯公式进行更新:后验=先验*似然(观测)),得到X1+~ N(0,0.8)。再利用后验概率X1+ 做为下一步的先验概率进行再预测,得到X2-~ N(0,3.2),再根据观测数据Y2,对X2-进行再更新,得到X2+,以此类推。
递推分两步,第一步是预测步,是上一时刻的后验概率,通过状态方程,求出这一时刻的先验概率;第二步叫更新步,这一时刻的先验概率,通过观测方程以及观测数据,推出这一时段的后验概率,这一时刻的后验概率可以被当作下一时刻的先验概率。
4. 贝叶斯滤波的算法
贝叶斯滤波算法所需要的原料和条件:
- 1. 首先是状态方程和观测方程. 假设:X0,Q1...Qk,R1....Rk之间是相互独立的。{Qk}是预测噪声,是建模的误差,{Rk}是观测噪声,是传感器的误差。X0是主观猜的初始值。
- 3. 有一系列的观测值y1.y2...yk
- 4. 设初始值X0的概率密度pdf f0(x),Qk的概率密度pdf:fQk(x),Rk的概率密度fRk(x)。
- 重要定理:条件概率例的条件可以做逻辑推导。条件概率的转化,不能省略条件。

具体步骤:
1). 预测步(求先验概率):

P(X1<x)=ΣP(X1=u),其中u是变量属于(-oo,x),这是离散转连续的方式。而通过全概公式:P(X1=u)=P(X1=u|X0=v)*P(X0=v)。
由于条件概率中的条件是X0=v,所以可以条件概率的等式两边,同减去f(X0)和f(v)。然后将原料中的状态方程带入,整理后,得到![]() ,其中从原料和条件中,可知Q1与X0是独立的,所以可以将X0=v从条件概率中取出,得到P(Q1=u-f(v)|X0=v)=P(Q1=u-f(v)。并要证明Qk与Xk-1是相互独立的(证明后置)。若他们相互独立,从X0到X1,X1到X2....,Xk-1到Xk的递推逻辑才能成立。
,其中从原料和条件中,可知Q1与X0是独立的,所以可以将X0=v从条件概率中取出,得到P(Q1=u-f(v)|X0=v)=P(Q1=u-f(v)。并要证明Qk与Xk-1是相互独立的(证明后置)。若他们相互独立,从X0到X1,X1到X2....,Xk-1到Xk的递推逻辑才能成立。
接下来就是求上述的连续随机变量的概率(随机变量的概率公式:P=∫ f(x)*ε,其中ε 趋向于0。将概率化为概率密度乘以ε,然后再取极限。 ),并利用中值定理(P(Q1=u-f(v)=fQ1[u-f(v)]*ε,p(X0=v)=f0(v)*ε)就得到了下面的公式:

所以P(X1<x)的公式可得(下式漏掉一个ε,并且u属于(-oo,x)):
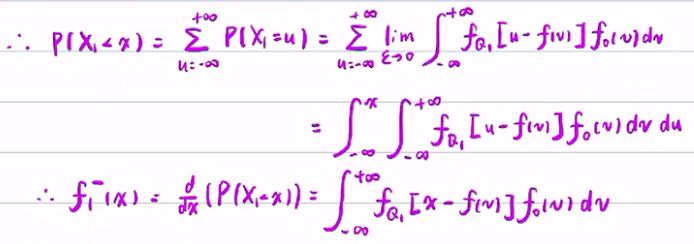
2). 更新步(求似然概率):
观测方程和更新步,主要是求似然概率
将观测方程带入,得P(y1-h(x)<Y1-h(x1)<y1-h(x)+ε)。
总结:递推公式推到过程。
f1得后验概率与f2得后验概率是不相等的,所以他们的η也不一样。
最后证明一下Qk与Xk-1的独立性,Xk与Rk独立

总结:预测步就是求先验概率,而更新步就是求似然概率,并求η。得到先验概率,似然概率和常数η,就可以得到后验概率。
贝叶斯滤波只是思想,虽然看上去算法很完美,但缺点就是无穷积分,在大多数情况下无法解析。

三大无穷积分:

解决方法:

卡尔曼率波就是对Qk,Rk做正态分布假设。基本思想:由上一时刻的期望和方差,推出这一时刻的期望和方差的先验,用这一时刻的方差的先验再推出这一时刻期望和方差的后验,再加上一个卡尔曼增益。
蒙特卡罗积分就是粒子滤波
直方图滤波:把曲线分成多段的常数,看起来就像直方图一样,这样就好积分了。

第七讲 贝叶斯滤波与卡尔曼滤波
1. 贝叶斯滤波:
1) 状态方程和观测方程,以及他们得前提假设:X0,Q1...Qk,R1...Rk相互独立
2) 贝叶斯滤波得三个公式:
2. 卡尔曼滤波
卡尔曼滤波相对于贝叶斯滤波,多了几个假设:
- f(x)与h(x)都是线性函数
- fQ(x)与fR(x)都是服从正态分布。
1) 首先假设Xk-1服从期望为uk-1,方差为σk-1,得正态分布。
![]()
2) 其次预测步:根据贝叶斯滤波,第一步是写出预测步公式,然后将相应得概率密度带入积分就行了。最后得到 u-k和σ-k。

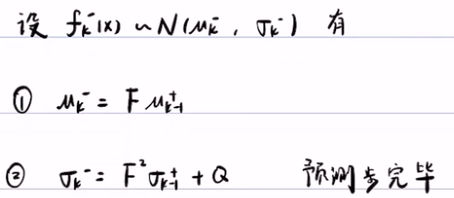
傅里叶变换:
- 前提假设:假设Xk-1服从正态分布, FXk-1也服从正态分布,Qk服从正态分布(0,Q),Xk-1与Qk之间是相互独立的。

- Xk=FXk+Qk,实际上是两个相互独立的的随机变量相加,它的概率密度实际上是这两个独立的随机变量的卷积。卷积有一个性质是:如果h是f与g的卷积的话,对h做傅里叶变换,就等于对f和g做傅里叶变换的乘积。那么我们只需要把FXk-1做傅里叶变换,再把Qk做傅里叶变换,然后把他们乘起来, 再做傅里叶逆变换,就会得到Xk的概率密度。虚部 iut 是期望,实部的分子σ2是方差,相对于正态分布的Fuk-1,F2σk-1+Q。

3)更新步:已知fk-(x)服从正态分布,那么fk+(x)后验概率就是常数 η 乘以似然概率 fR(yk-h*x)和先验概率fk-(x)。
利用数学公式去算,得到一个随机变量Xk+,但这个随机变量服从一个比较复杂的正态分布。通过变形得到uk+和σk-。
这样就可以得到了后验概率的期望和方差。它们有相同的因子:h*σk-/(h2σk-+R),这个因子K叫做卡尔曼增益。

这样我们我们就可以对上面的后验概率的期望和方差进行改写:

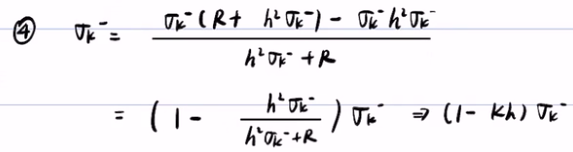
这样我们就可以得到卡尔曼滤波的五个公式:预测步2个,更新步2个,外加卡尔曼增益。分别是代表从k-1的后验,通过两个独立的正态分布相加,推导出k的先验,再利用k的先验乘以似然概率(两个正态分布相乘再乘以常数η),推导到k的后验(其结果也是正态分布)。卡尔曼滤波之所以简单就是无需算积分,通过对期望和方差的计算,无需知道后验概率是什么形式。
可以发现卡尔曼公式没有后验概率密度,没有积分之类的东西,而只是一些普通的数,进行加加减减。所以具有非常好的性质(这是由正态分布非常好的性质决定的)。正态分布具有封闭性,两个独立的正态分布,通过卷积,相乘,归一化,最终还是正态分布。但对于非线性就没有这么好的性质了,所以非线性的卡尔曼滤波就比较难,它的计算量比较大,因为它已经不再是正态分布,所以你必须计算出后验的概率分布出来 。
我们对卡尔曼增益做变形,将σk-除下去。
- 当R》σk-时,k就趋于0,uk+ ~= uk-,即相信预测结果。这是合理的,因为R是观测的方差,σk-是预测的方差。当R远大于σk-的时候,就说明观测不可信(噪声太大),那么卡尔曼滤波就会偏向预测值。
- 同理,R《σk-时,我们更相信观测值。

矩阵形式的卡尔曼滤波:与一维卡尔曼滤波很像,其中期望与方差,及F,H都会变为矩阵形式,

其公式也很像,但涉及多元的正态分布概率密度的形式,以及多重的无穷积分,比较复杂。
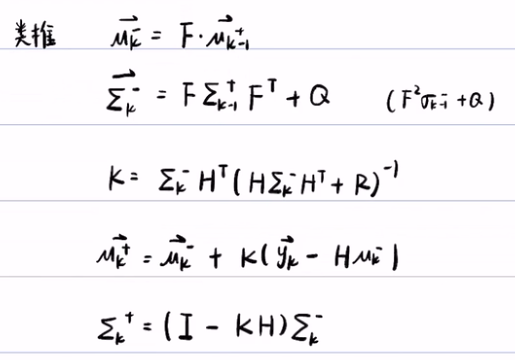
第八讲 从零开始码出卡尔曼滤波
应用:more is different
模型1:
# loding modules import numpy as np import pandas as pd from pandas import * import matplotlib.pyplot as plt #X(k) = F*X(K-1)+Q #Y(k) = H*X(K)+R #第一个问题,生成一段随机信号,并滤波 #生成一段时间t,每隔0.01秒进行采样一次。 t = np.arange(0.1,1,0.01) L = len(t) #有了时间,就可以生成真实信号x,以及观测y。 #首先初始化 x=pd.Series(np.zeros(L)) y=pd.Series(np.zeros(L)) #不能将x赋值给y(即y=x),这样只会将x与y用做同一内存空间。 #生成信号,设x=t^2 for i in range(L): x[i]=t[i]**2 y[i]=x[i]+np.random.normal(0,0.1) plt.plot(t,x) plt.plot(t,y) #滤波算法 #预测方程怎么写: #观测方程:Y(K)=X(K)+R R~N(0,1),贝叶斯滤波也卡尔曼滤波的难点就是Q和R的方差的取值,它的难点在于没有规律性,只能不停的去试。 #预测方程不好写,画图(plt.plot(t,y))后,可以看出曲线的一些规律性,可以猜一猜是线性增长,但是大多数问题,信号是杂乱无章的,怎么办。 #模型一,最粗糙的建模: #X(k)=X(k-1)+Q #Y(k)=X(k)+R #猜Q~N(0,1),弄成正态分布,相对好处理一些。 F1=1 H1=1 Q1=1 R1=1 #初始化X(k)+,要设置一个数组来装这个X(k)+,因为卡尔曼滤波是递推的,X(k)+需要X(k-1)+。 Xplus1=Series(np.zeros(L)) Pplus1=Series(np.zeros(L)) Xminus1=Series(np.zeros(L)) Pminus1=Series(np.zeros(L)) K1=Series(np.zeros(L)) #设置一个初值,假设Xplus1(1)~N(0.01,0.01^2) Xplus1[0]=0.01 Pplus1[0]= 0.01**2 #卡尔曼滤波算法:它是期望与方差之间的递推关系,用前一时刻plus的期望和方差,推出这一时刻minus的期望和方差。以及这一时刻minus的期望和方差,推出这一时刻plus的期望和方差。再加上一个卡尔曼增益。X(0)是没有minus,且带plus的先验概率的,除了X(0)外所有X(k)的minus为先验概率,而plus为后验概率。 #X(k)minus = F*X(k-1)plus #P(k)minus = F*P(k-1)plus*F+Q #K = P(k)minus*H*inv(H*P(k)minus*H'+R) #X(k)plus = X(k)minus+K*(y(k)-H*X(K)minus) #P(k)plus = (1-K*H)*P(k)minus for i in range(1,L): ##预测步: Xminus1[i]=F1*Xplus1[i-1] Pminus1[i]=F1*Pplus1[i-1]*F1'+Q1 #F1'是Matlab求转置。 ##更新步: K1[i] = (Pminus1[i]*H1')/(H1*Pminus1[i]*H1'+R1) Xplus1[i] = Xminus1[i]+K1[i]*(y[i]-Xminus1[i]*H1) Pplus1[i]=(1-K1[i]*H1)*Pminus1[i] plt.plot(figsize=(20,12)) plt.plot(t,x,'r') plt.plot(t,y,'g') plt.plot(t,Xplus1,'b') #Q1,R1=0.01,控制噪声的方差。 #Xplus1[0]控制初始值,初始值的大小对滤波影响不大,最后滤波会调整。
模型2:
###### 模型2 ########## #模型2相对于模型1相比,观测方程还是一样,但预测方程一项,把X(k)写成用X(k-1)展开的一些项(泰勒展开式)。 #X(K)=X(K-1)*dt+X'(K-1)*dt+X''(K-1)*dt^2*(1/2!) #Y(K)=X(K)+R R~N(0,1) #此时状态变量不再是标量了,而是向量:X=[X(k) X'(K) X''(K)]T 列向量 #Y(K)=H*X+R H=[1 0 0] 行向量 #预测方程 #X(K)=X(K-1)+X'(K-1)*dt+X''(K-1)*dt^2*(1/2!)+Q2 #X'(K)=0*X(K-1)+X'(K-1)+X''(K-1)*dt+Q3 #X''(K)=0*X(K-1)+0X'(K-1)+X''(K-1)*dt+Q3 多项式信号多求多阶导数,总会比较平缓,而 #X'''(K)=X''(k-1)+Q3正是描述平衡的随机过程,这种建模相对精细一些,适用范围也较广。它的原理就是无论是什么函数,多求几次导,总会求到0,0就比较平缓了。对导数建随机平稳得模型,要比直接对多项式函数建平稳得模型相对来说精细一点。但有可能信号是指数,那么怎么建都不平缓。一般来说,信号不会增长太快,一般物理规律,信号不会增长太快。 #F= 1 dt 0.5*dt^2 #F是一个矩阵,在计算中要注意行向量和列向量。 # 0 1 dt # 0 0 1 #H=[1 0 0] #Q = Q2 0 0 #Q是一个噪声的协方差矩阵,Q协方差是用来描述他们随机变量的噪声的相互关系。由于状态变量X是由3个元素组成,Xk,Xk',Xk'',他们是多维随机变量,有各自的方差。而他们之间的关系,若两个随机变量的相关性为0,那么他们是不相关,若Xk增大了,Xk’是否会有变化,这需要用协方差来表述。 # 0 Q3 0 # 0 0 Q4 dt = t[2]-t[1] F2 = np.mat([[1,dt,0.5*dt**2],[0,1,dt],[0,0,1]]) #此处要注意矩阵是否病态,若dt特别小,易导致矩阵病态或精度丢失 H2 = np.mat([[1,0,0]]) Q2 = np.mat([[1,0,0],[0,0.01,0],[0,0,0.001]]) R2 = 20 #只有一个观测,所以只有是标量,如果有多个观测,得写成矩阵形式。 #设置初始值 Xplus2 = np.matrix(np.zeros((3,L))) Xplus2[0,0]=0.1**2 Xplus2[1,0]=0 Xplus2[2,0]=0 Pplus2=np.mat([[0.01,0,0],[0,0.01,0],[0,0,0.0001]]) #一般来说,初始得协方差矩阵都写成是对角矩阵形式。 #K2 = np.mat(np.zeros((3,1))) for i in range(1,L): #预测步 Xminus2[:,i]=F2*Xplus2[:,i-1] Pminus2=F2*Pplus2*F2.T+Q2 #更新步 K2=(Pminus2*H2.T)*np.linalg.inv(H2*Pminus2*H2.T+R2) Xplus2[:,i]=Xminus2[:,i] +K2*(y[i]-H2*Xminus2[:,i]) Pplus2=(np.identity(3)-K2*H2)*Pminus2 Xplus2_0=np.zeros(L) for i in range(L): Xplus2_0[i]=Xplus2[0,i] plt.plot(figsize=(20,12)) plt.plot(t,x,'r') plt.plot(t,y,'g') plt.plot(t,Xplus1,'b') plt.plot(t,Xplus2_0,'m') # 可以进行在线滤波,实时滤波 ### 问题2,两个传感器,进行滤波 ### # Y1(K) = X(K)+R # Y2(K) = X(K)+R # H=[1 1]T (列向量) X=X(K) # H=[[1 0 0], [1 0 0]]
第九到第十二讲:粒子滤波
若f(Xk-1) h(Xk)都是非线性函数,要用粒子滤波,这是处理非线性最准的方法,但是粒子滤波的缺陷是对内存消耗太大。计算非常的慢,因为需要重采样,如果采的不是正态分布的样本,那么会非常慢。粒子滤波的精度是随着粒子增多而提高的。
第十三讲 扩展卡尔曼滤波 (EKF)
扩展的卡尔曼滤波处理非线性函数的速度比粒子滤波快,但是这个快是要牺牲精度的。特别是在强非线性的问题中,这种方法很有可能会发散。

扩展卡尔曼滤波的思想是对f(Xk-1)和h(Xk)进行线性化。
扩展卡尔曼滤波的工作原理:
![]()
设Xk-1服从期望为XK-1+,方差为Pk-1的正态分布,其实Xk-1+和Pk-1+是一个数,而不是一个随机变量,这是扩展卡尔曼滤波的源头。 Xk-1是一个正态分布 ,通过递推,扩展卡尔曼滤波所算出来的XK+也得是正态分布,只有这样算法的递推才能进行下去。因为Xk-1是正态分布,推出Xk,又由Xk去推Xk+1,所以必须保证Xk也是正态分布才可以,否则就没有办法递推了。如果Xk不服从正态分布,就没有办法调用卡尔曼滤波来算了。这么一来,{Xk}序列都要服从正态分布。这样就会引起误差,因为F和H本质上是非线性函数。所以说真实的后验概率它一定不是正态分布,因为它是非线性函数,但滤波的结果是正态分布,误差就在这体现。所以扩展的卡尔曼滤波是一种近似,这种近似是有误差的。
那么扩展卡尔曼滤波是怎么处理的:
1) 预测步
- 首先对预测方程进行线性化,即用泰勒公式展开(只展开一阶),得f(Xk-1)~= f'(xk-1+)+f(xk-1+)-f(xk-1+)*xk-1+。其中f(xk-1),f'(xk-1+),xk-1+他们都是数,所以就线性化了。因为他们是数,所以可以将X前的系数改为A=f'(xk-1+),B=f(xk-1+)-f(xk-1)*xk-1+。这样就可以得到f(Xk-1) = AXk-1 + B,其中系数A和B都是数。这样就完成了预测方程的线性化。
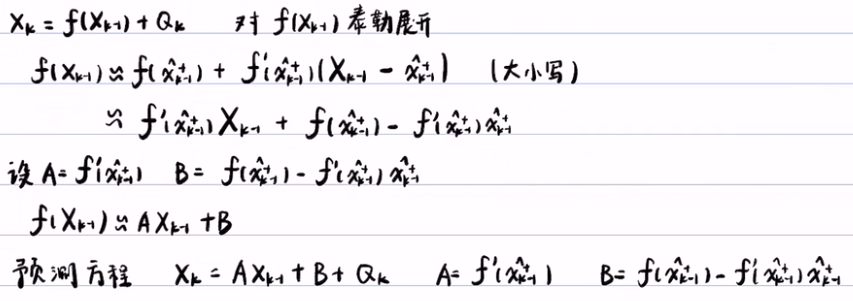
- 然后将预测方程带入到贝叶斯滤波里,贝叶斯滤波中的预测步为:
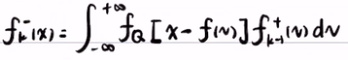 ,将上面得到的 f(v) = Av+B 带入到贝叶斯滤波的预测步中,得到
,将上面得到的 f(v) = Av+B 带入到贝叶斯滤波的预测步中,得到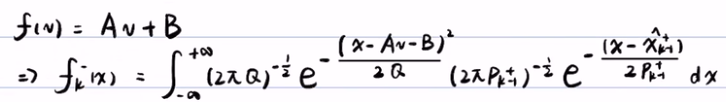 。积分后得到了(利用软件积分得到)期望为Axk-1++B,方差为A2Pk-1++Q的正态分布
。积分后得到了(利用软件积分得到)期望为Axk-1++B,方差为A2Pk-1++Q的正态分布 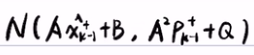 。严格来说fk-(x)是正态分布的概率密度,而不是正态分布。
。严格来说fk-(x)是正态分布的概率密度,而不是正态分布。 
-
将其进一步简化:
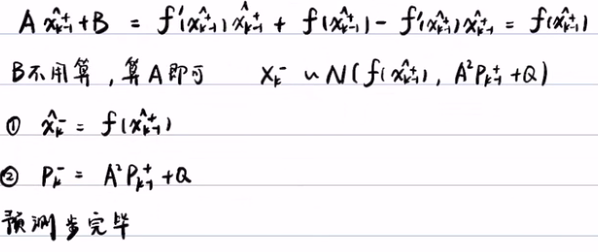
2)更新步:
- 首先,对更新步进行线性化,得到h(Xk) ~= h(xk-) + h(xk-)(Xk-xk-) = CXk+D.(注:预测步中,是在f(xk-1+)这个点进行泰勒展开,而在更新步中,是在h(xk-)这一点做泰勒展开)

- 然后将更新方程带入到贝叶斯滤波里:

- 用Mathematica软件去算上面的式子,得到扩展卡尔曼增益,后验概率的期望和方差。
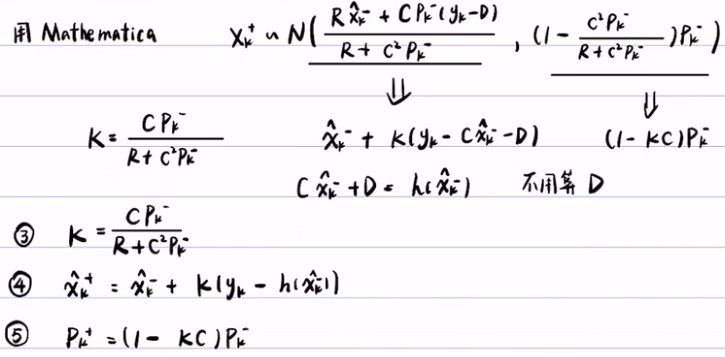
- 加入A和C的公式,

EKF算法的总结:
- 设Xk-1服从N(xk-1+, Pk-1+)的正态分布。
- 预测步:先算A,再通过上一步的期望和方差,推出这一步的期望和方差
- 更新步:先算C,再算EKF增益,然后再算后验的期望和方差。
矩阵形式的卡尔曼滤波:
- 设预测方程和观测方程,并设向量Xk-1服从多维的正态分布。

- 先算A,实际上就是f对向量的每一行的每个元素的偏导数,这样就把A变成了常数矩阵了。再算先验的期望和方差。

-
再算更新步,这里的C不一定是一个方阵。第五步再算卡尔曼增益,第六步观测到一个数据向量Y。第七步就是对期望进行更新,第八步是对方差进行更新。
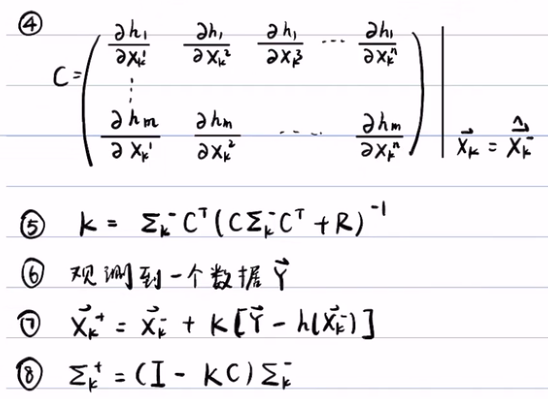
- 一个
https://blog.csdn.net/coming_is_winter/article/details/79048700
σk2

