
Hive的数据类型
Hive的基本数据类型
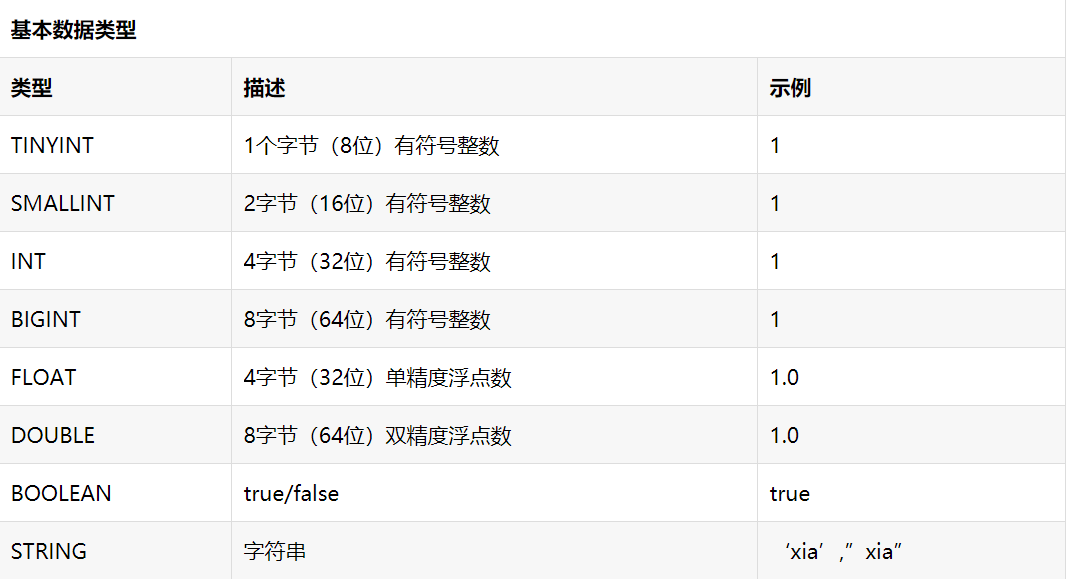
Hive的复杂数据类型
复杂数据类型包括数组(ARRAY)、映射(MAP)和结构体(STRUCT),具体如下表所示:

Hive的表库操作
Hive的数据库操作
Hive中数据库的概念本质上仅仅是表的一个目录或者命名空间。然而,对于具有 很多组和用户的大集群来说,这是非常有用的,因为这样可以避免表命名冲突。
如果用户没有使用use关键字显示指定数据库,那么将会使用默认的数据库default。
查看数据库
show databases;
使用like关键字实现模糊匹配
show databases like 'hive_*'; 检索以hive开头的数据库
使用数据库
use 数据库名称;
创建数据库
create database 数据库名;
删除数据库
drop database 数据库名;(这种删除,需要将对应数据库中的表全部删除后才能删除数据库)
drop database 数据库名 cascade;(强制删除,自行删除所有表)
查看数据库的描述
desc database 数据库名;
Hive的数据表操作
显示数据库中的表
show tables;
使用like关键字实现模糊匹配
show tables like 'hive_*';
显示表的详细信息
desc [formatted] hive_01;(加上formatted显示的更详细)
创建数据表(与MySQL类似)
create [external] table [if not exists] table_name
[(col_name data_type [comment col_comment], ...)]
[comment table_comment]
[partitioned by (col_name data_type [comment col_comment], ...)]
[clustered by (col_name, col_name, ...)
[sorted by (col_name [asc|desc], ...)] into num_buckets buckets]
[row format row_format]
[stored AS file_format]
[location hdfs_path]
上述字段解释说明:
1: create table 创建一个指定名字的表,如果相同名字的表已经存在,则抛出异常;用户可以使用 IF NOT EXISTS来规避这个异常。
2: external关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(location)。
3: comment为表和列添加注释
4: partitioned by创建分区表
5: clustered by创建分桶表
6: sorted by 排序
7: row format
delimited [fields terminated by char]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char] | SERDE serde_name [WITHSERDEPROPERTIES(property_name=property_value,
property_name=property_value, ...)]
- fields terminated by char 列分隔符
- COLLECTION ITEMS TERMINATED BY char 集合元素直接的分隔符
- MAP KEYS TERMINATED BY char map集合KV的分隔符
- 用户在建表的时候可以自定义SerDe或者使用自带的SerDe,如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe,在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
8:stored as指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本 不指定默认)、RCFILE(列式存储格式文件)、ORCFILE(行列压缩存储文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据是二进制文件,使用 STORED AS SEQUENCEFILE,如果数据需要压缩请使用 STORED AS RCFILE 或 STORED AS ORCFILE
textfile 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高。
sequencefile 存储空间消耗最大,压缩的文件可以分割和合并 需要通过text文件 转化来加载。
rcfile 存储空间小,查询的效率高 ,需要通过text文件转化来加载,加载的速度最低
orcfile 存储空间最小,查询的最高 ,需要通过text文件转化来加载,加载的速度最低。
9:location指定在HDFS上的存储位置
10:like允许用户复制表的结构,但不复制数据。
#使用数据库 use text; #创建表 create table [if not exists] test( id int, name string, hobby array<string> address map<string,string> )row format delimited fileds terminated by ' ' connection items terminated by ':' map keys terminated by '~'
#默认stored as储存文件类型是textfile
#load加载数据(只有textfile类型的表才可以使用load)
load data local inpath '/usr/test/movies.dat' overwrite into table movie
#创建不同的文件储存类型
create table [if not exists] test1(
id int,
name string,
hobby array<string>
address map<string,string>
)
stored as orcfile;
#除了textfile类型的储存方式都得用insert加载数据
insert overwrite table test1 select * from test;
序列化器SerDe
//创建新表 指定SerDe 为RegexpSerDe正则 use b01; create table reg_table( id int, name string ) row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe' with serdeproperties('input.regex'="id=(.*),name=(.*)"); //.代表单个字符 * 0~N次 //加载数据 load data local inpath '/usr/local/hive_data/regexp_test' overwrite into table reg_table; //创建user用户数据的指定JSON的序列化器 create table user_json_textfile( uid string, phone string, addr string ) row format serde 'org.apache.hive.hcatalog.data.JsonSerDe'; load data local inpath '/usr/local/xl_project/user/user_login_info.json' overwrite into table user_json_textfile;
Hive内部表&&外部表
未被external修饰的是内部表(managed table),被external修饰的为 外部表(external table)
内外部表的区别:
- 内部表数据由Hive管理,外部表数据由HDFS管理
- 内部表的数据的存储位置是hive.metastore.warehouse.dir ,默认为/user/hive/warehouse中,外部表的数据存储位置由自己指定。
- 删除内部表中的数据会直接删除元数据及存储数据;删除外部表仅仅会删除元数据,HDFS上的数据并不会被删除;
- 对内部表的修改会将修改直接同步给元数据;而对外部表的表结构和分区进行修改,则需要MSCK REPAIR TABLE table_name(将HDFS上的元数据信息写入到metastore);
//创建外部表 create external table outter_table( id int, name string, hobby array<string>, address map<string,string> )row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':' location '/outter/data' //向外部表中载入数据 load data local inpath '/usr/local/person' into table outter_table;
Hive表的修改操作
表重命名
Alter table 旧名称 RENAME to 新名称;
alter table person rename to person_info;
修改列信息
Alter table 表名 CHANGE [COLUMN] 列名 新列名 数据类型
[COMMENT 注释文本]
[AFTER 字段名称|FIRST];
//修改列名称 alter table test1 change name tename string; //修改列类型 alter table test1 change id id string;
//指定列位置
alter table test1 change id id string first;
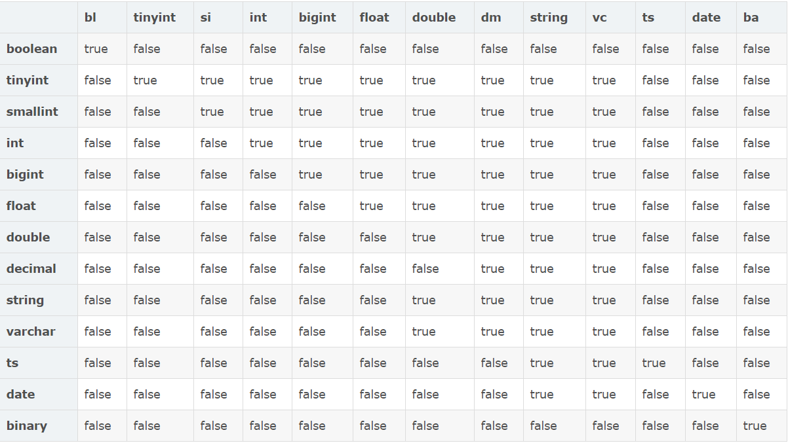
这里会遇到类型兼容的问题,看下表:
Hive数据类型之间的隐式转换
增加列
Hive能将新的字段添加到已有字段之后
Alter table 表名 ADD COLUMNS(
列名 字段类型 [COMMENT ‘注释’],
........
);
//增加列(可以一次添加多个) alter table test1 add columns( img string, addr string )
删除或替换列
Alter table 表名 REPLACE COLUMNS(
列名 字段类型 [COMMENT ‘注释’],
............
);
//删除替换列 alter table test1 replace columns( id string, name string, age string )
修改表的存储属性
Alter table表名 SET FILEFORMAT (TEXTFILE|SEQUENCEFILE|RCFILE|ORCFILE)
会出现严重问题:(TEXTFILE的数据无法直接向RCFILE和ORCFILE导入,由于RCFILE
与ORCFILE都是以块状存储数据,我们只能通过insert语句导入到一个ORCFILE或RCFILE的新表中)。快对快,行对行
//修改表的存储结构 alter table test1 set fileformat sequencefile
设置表的注释
alter table 表名 set tblproperties('属性名'='属性值');
//设置表的注释 alter table test1 set tblproperties('comment'='测试表')
修改表的分隔符
alter table 表名 set serdeproperties('属性名'='属性值');
//修改表的分隔符 alter table test1 set serdeproperties('field.delim'='~')
查看表的详细的建表语句
Show create table 表名;
//展示创建表的详细信息 show create table test1
修改表的serde_class
//修改表的序列化器 alter table test1 set serde 'org.apache.hadoop.hive.serde2.RegexSerDe' with serdeproperties ("input.regex" = "id=(.*),name=(.*),age=(.*)");
Hive添加jar包
add JAR '/usr/local/hive_data/hive-hcatalog-core-2.3.5.jar'(存放jar路径和jar名称)
Hive的分区操作
hive开发中,在存储数据时,为了更快地查询数据和更好地管理数据,都会对hive表中数据进行分区存储。所谓的分区,在hive表中体现的是多了一个字段。而在底 层文件存储系统中,比如HDFS上,分区则是一个文件夹,或者说是一个文件目录,不同的分区,就是数据存放在根目录下的不同子目录里,可以通过show partitions查看。
静态分区
//创建静态分区表 create table test_partition ( id string comment 'ID', name string comment '名字') comment '测试分区' partitioned by (year int comment '年') ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
insert语句:
//插入分区表数据(静态分区) insert into table test_partition partition(year=2000) values(1,'小明'); insert into table test_partition partition(year=1999) values(2,'小红'); insert into table test_partition partition(year=2000) values(3,'小兰'); insert into table test_partition partition(year=1998) values(4,'小紫');
load语句:
load data local inpath '/usr/local/part_test' into table test_partition partition (year =2018); load data local inpath '/usr/local/part_test' into table test_partition partition (year =2018); load data local inpath '/usr/local/part_test' into table test_partition partition (year =2017);
动态分区
动态分区默认不开启,需要使用下列语句开启:
set hive.exec.dynamic.partition.mode=nonstrict;#需退出hive,重新进入执行
//创建动态分区 create table test_partitions ( id string comment 'ID', name string comment '名字', year int comment '年' )comment '测试' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
insert语句:
insert into table test_partitions partition(year) values(5,'小白',2016);
insert into table test_partitions partition(year) values(6,'小黑',2016);
load语句:
load data local inpath '/usr/local/part_test' into table test_partitions partition (year);
修改分区
指定到新分区目录下 原始分区仍旧存在 但是后续插入的新记录会存储到新分区中
alter table test_partitions partition(year=2016) set location '/user/hive/warehouse/new_part/b01.db/test_partition/year=2016';
删除分区
alter table test_partitions drop partition(year=2016);
同步到关系型数据库中的元信息
MSCK REPAIR TABLE test_partitions;
分桶表
分桶表描述
分桶是相对分区进行更细粒度的划分。分桶将整个数据内容安装某列属性值得hash值进行区分,如要安装name属性分为3个桶,就是对name属性值的hash 值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。
//先设置一下分桶的权限
set hive.enforce.bucketing=true;
//创建分桶表 use test; create table student_bck (id int, name string) clustered by (id) sorted by (id desc) into 3 buckets row format delimited fields terminated by ",";
//插入数据 insert overwrite table student_bck select id,name from test_partition;
//查询分桶数据 select * from student_bck tablesample(bucket 3 out of 3 on id);
tablesample (bucket x out of y on id);
# x表示从哪个桶(x-1)开始,y代表分几个桶,也可以理解分x为分子,y为分母,及将表分为y份(桶),取第x份(桶)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号