
一.环境支持
- 操作系统: CentOS7 64
- JDK环境: JDK 8
- Hadoop环境: hadoop-2.8.0
- 虚拟机名称: master(主)+slave1(从1)+slave2(从2)
CentOS7 64位百度网盘下载地址:
链接:https://pan.baidu.com/s/1dcQ9_vu1nWZ_lcNqaWLtYQ
提取码:35cf
JDK 8百度网盘下载地址:
链接:https://pan.baidu.com/s/1nbDic_eD8Aio8NFk-k7R2g
提取码:kth1
hadoop-2.8.0百度网盘下载地址:
链接:https://pan.baidu.com/s/1AZDLEVrG53pqG84u-2Gysw
提取码:o90j
复制这段内容后打开百度网盘手机App,操作更方便哦
虚拟机不限版本
二.设置各个主机名称
1.#编辑hostname配置文件
vim /etc/hostname
2.将各个主机的名称填入到具体的hostname文件中

3.使用hostname命令查看主机名是否成功修改

三.配置JDK的环境变量
1.将jdk的安装包通过xftp上传到master下的/usr/local目录下(可以自己选择存放目录)
2.找到存放jdk的目录解压
tar -zxvf jdk-8u121-linux-x64.tar.gz
3.通过scp命令将解压好的jdk发送给其他对应的两台主机
scp -r /usr/local/jdk1.8.0_121/ root@您的IP:/usr/local/

4.接下来,分别卸载各自主机上默认安装的不完整的jdk
rpm -qa|grep jdk #查看默认安装的jdk

5.逐个卸载
|
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64 rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64 rpm -e --nodeps java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64 rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64 #我这个只是示例,实际看自己的jdk |
6.三台主机配置/etc/profile文件,加入JAVA_HOME变量
|
#编辑profile文件 vim /etc/profile #加入以下内容,请各位视自身的安装目录为准 export JAVA_HOME=/usr/local/jdk1.8.0_121 export CLASSPATH=.:%JAVA_HOME%/lib/dt.jar:%JAVA_HOME%/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin #刷新配置文件 source /etc/profile #查看配置是否成功 java -version |
4.hadoop配置
1.将hadoop-2.8.0.tar.gz文件通过xftp上传到master下的/usr/local下
2.解压压缩包
tar -zxvf hadoop-2.8.0.tar.gz
3.配置hadoop的环境变量
|
#编辑profile文件 vim /etc/profile #加入以下内容,请各位视自身的安装目录为准 export HADOOP_HOME=/usr/local/hadoop-2.8.0 export PATH=$PATH:$HADOOP_HOME/bin:$PATH:$HADOOP_HOME/sbin #刷新配置文件 source /etc/profile |
4.编辑hosts文件,将三台主机的主机名称对应的ip地址写入
|
#编辑hosts文件 vim /etc/hosts #写入如下内容,注意IP地址以自身为准 192.168.93.129 master 192.168.93.130 slave1 192.168.93.131 slave2 |
5. 完成hadoop内部的配置
#切换到指定目录下
cd /usr/local/hadoop-2.8.0/etc/hadoop/
#配置slaves文件
vim slaves
#增加slave主机名,删除掉原有的localhost(必须删除localhost否侧主节点也会被认为是从节点)
slave1
slave2
#配置core-site.xml文件
vim core-site.xml
#在configuration节点中加入如下节点
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!--视自身的安装位置决定-->
<value>/usr/local/hadoop-2.8.0/tmp</value>
</property>
#配置hdfs-site.xml文件
vim hdfs-site.xml
#在configuration节点中加入如下节点
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!--以自身安装目录为准-->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.8.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.8.0/hdfs/data</value>
</property>
#编辑hadoop-env.sh和yarn-env.sh两个文件
vim hadoop-env.sh
vim yarn-env.sh
#加入以下内容(目录视自身jdk安装位置)
export JAVA_HOME=/usr/local/jdk1.8.0_121/
#配置mapreduce
#由于mapred-site.xml文件不存在,需要将mapred-site.xml.template克隆出来一份
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml

#在configuration中加入如下内容
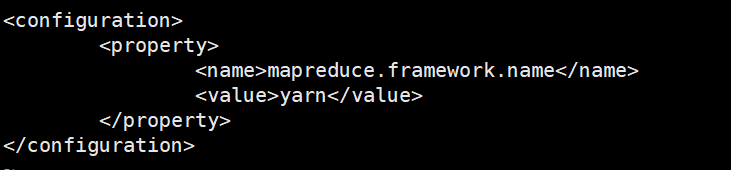
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
#配置yarn
vim yarn-site.xml
#在configuration节点中加入如下内容
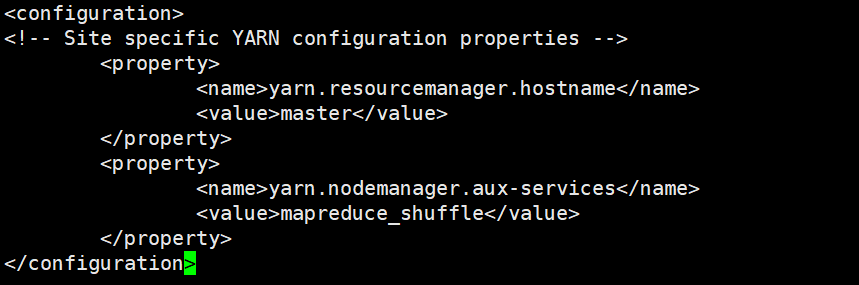
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
#将Hadoop拷贝到另外两台slave从节点
通过scp命令将已配置好的对应内容发送到slave主机上
|
#发送已配置好的hadoop-2.8.0目录 scp -r /usr/local/hadoop-2.8.0 root@slave1:/usr/local/ scp -r /usr/local/hadoop-2.8.0 root@slave2:/usr/local/ #发送已配置好的profile文件 scp /etc/profile root@slave1:/etc/ scp /etc/profile root@slave2:/etc/ |
之后在每个子机器中使用 source /etc/profile 使文件生效
5.启动Hadoop集群服务
1、在master主机上运行如下
hdfs namenode -format 注意:此命令只用执行一次,以后再开启集群时不用在执行此命令,谨记
2、启动服务命令
start-all.sh(如果没有配置免密会有很多次需要输入密码,建议配置免密)
3、停止集群的命令
stop-all.sh
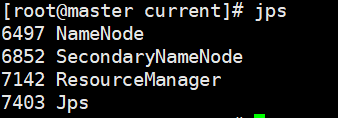
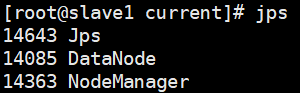
4、查看进程是否启动成功
Master:
Slave:
Hadoop集群到此搭建完毕!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号