操作系统:锁
参考:
https://blog.csdn.net/qq_34376868/article/details/110286760
1.1 竞态条件
我们知道,在操作系统中,互相协作的进程之间可能共享一些彼此都能读写的公共存储区,假设两个进程都需要改写这个公共的存储区那么就会产生竞争关系了。
由于两个或者多个进程读写某些共享数据,最后结果取决于进程运行的精确时序,称为竞态条件。
为了避免这种竞态条件的出现,就需要找出存在这种竞态条件的程序片段,通过互斥的手段来阻止多个进程同时读写共享的数据。
1.2 临界区
对共享内存进行访问的程序片段称为临界区。
为了避免竞态条件的产生,我们需要把获取空槽位和往槽位写内容的程序片段作为一个临界区,任何不同的进程,不可以在同一个时刻进入这个临界区:
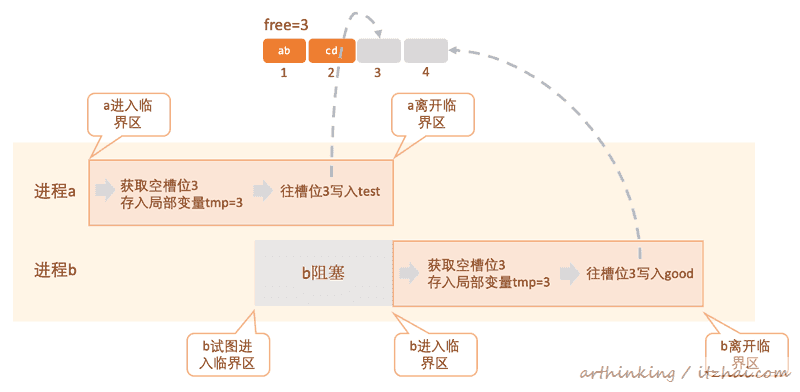
如上图,进程b试图在a离开临界区之前进入临界区,会进入不了,导致阻塞,通常表现的行为为: 进程挂起或者自旋等待。
为了实现这种临界区的互斥,需要进程之间能够像对话一样,确认是否可以进入临界区执行代码,这种对话即进程通信。
2.1 自旋等待:忙等待的互斥
所谓忙等待,指的是进程自己一直在循环判断是否可以获取到锁了,这种循环也称为自旋。 通过屏蔽中断和锁变量的介绍,依次引出忙等待的相关互斥手段方法。
2.1.1 屏蔽中断
在进程进入临界区之前,调用local_irq_disable宏来屏蔽中断,在进程离开临界区之后,调用local_irq_disable宏来使能中断。
CPU只有发生时钟中断或其他中断才会进行进程切换,也就是说,屏蔽中断后,CPU不会切换到其他进程。但是,这仅仅对执行disable的那个CPU有效,其他CPU仍将继续运行,也就是说多核处理器这种手段无效。
另外,这个屏蔽中断是用户进程触发的,如果用户进程长时间没有离开临界区,那就意味着中断一直启用不了,最终导致整个系统的终止。
由此可见,在这个多核CPU普及的时代,屏蔽中断并不是实现互斥的良好手段。

2.1.2锁变量
上面一种是硬件的解决方案,既然硬件解决不了,那么我们尝试通过软件层面的解决方案去实现。 我们添加一个共享锁变量,变量为0,则表示可进入临界区,进入之后,设置为1,离开临界区重置为0,如下图所示:
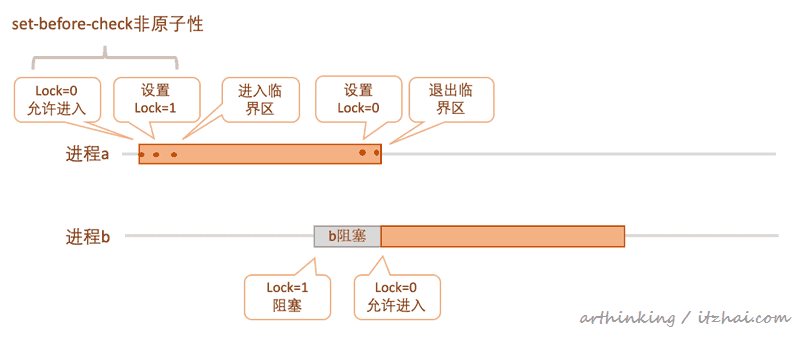
但是由于对Lock的check和set是分为两步,并非原子性的,那么可能会出现如下情况:
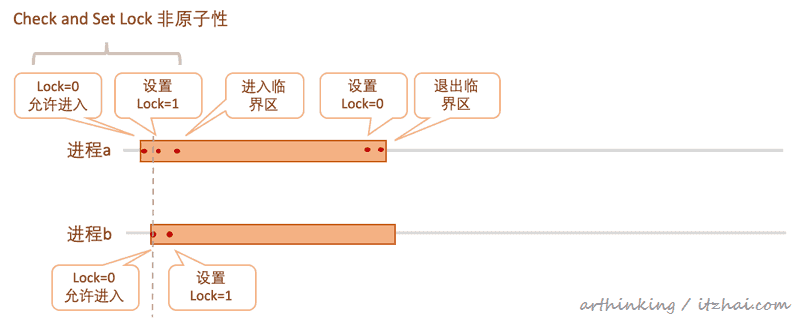
也就是说在进程a把Lock设置为1之前,b就进行check和set操作了,也获取到了Lock=0,导致两个进程同时进入了临界区。
这种非原子性的检查并设置锁操作还是会存在竞态条件,并不能作为互斥的解决方案。
如果cpu指令支持check和set操作为一个原子操作,则可以实现。
2.1.3 严格轮换法
所谓严格轮换法,就是指定一个标识位turn,当turn=0的时候让进程a进入临界区,当turn=1的时候,让进程b进入临界区。实现代码:
// 进程a while(TRUE){ while(turn != 0); /* 循环测试turn,看其值何时变为0 */ critical_region(); /* 进入临界区 */ turn = 1; /* 让给下一个进程处理 */ noncritical_region(); /* 离开临界区 */ } // 进程b while(TRUE){ while(turn != 1); /* 循环测试turn,看其值何时变为1 */ critical_region(); /* 进入临界区 */ turn = 0; /* 让给下一个进程处理 */ noncritical_region(); /* 离开临界区 */ }
也就是说,我唱完一首歌,把麦给了你,轮到你唱,这个时候你拿着麦去上厕所了。 那么我想唱歌,也只能等到你上完厕所,唱完歌,把麦的使用权交接给我,我才可以继续唱。
你上厕所竟然影响到了我唱歌,就是所谓的临界区外运行的进程阻塞了其他想进入临界区的进程。
看来这种解决方案并不是一个很好的选择。
2.1.4 PERTERSON解法
talk is cheaper,show me the code:
#define FALSE 0 #define TRUE1 #define N 2 /* 进程数量 */ int turn; /* 现在轮到谁? */ int interested[N]; /* 所有值初始化为0 (FALSE) */ void enter_region(int process){ /* 进程是0或1 */ int other; /* 其他进程号 */ other = 1 - process; /* 另一方进程 */ interested[process] = TRUE; /* 表示所感兴趣 */ turn = process; while(turn == process && interested[other] == TRUE);/* 空循环 */ } void leave_region(int process){ interested[process] = FALSE; /* 表示离开临界区 */ }
可以看到,这个算法只适用于两个进程间的互斥处理,更多进程就没办法了。
接下来,我们通过一种硬件指令的方式,帮助我们更好的实现互斥。
2.1.5基于硬件指令
基于硬件指令一般是基于冲突检测的乐观并发策略: 先进行操作,如果没有其他进程争用共享数据,操作就成功了,如果产生了冲突,就进行补偿,不断重试。
乐观并发策略需要硬件指令集的发展才能进行,需要硬件指令实现: 操作+冲突检的原子性。
这类指令有:
测试并设置锁 Test and Set Lock (TSL) 获取并增加 Fetch-and-Increment 交换 Swap 比较并交换 Compare-and-Swap (CAS) 加载链接/条件存储 Load-linked / Store-Conditional LL/SC
TSL指令
lock=0时,任何进程都可以使用TSL指令将其设置为1,并读写共享内存,当操作结束时,进程使用move指令将lock的值重新设置为0。
为了使用TSL指令,需要使用一个共享变量lock来协调多内存的访问。
TSL RX, LOCK
执行原理: 执行TSL指令的CPU会锁住内存总线,禁止其他CPU在这个指令结束之前访问内存。
show me the code
enter_region: TSL REGISTER,LOCK | 复制锁到寄存器并将锁设为1 CMP REGISTER,#0 | 锁是0吗? JNE enter_region | 若不是0,说明锁已被设置,所以循环 RET | 返回调用者,进入临界区 eave_region: MOVE LOCK,#0 | 在锁中存入 0 RET | 返回调用者复制代码
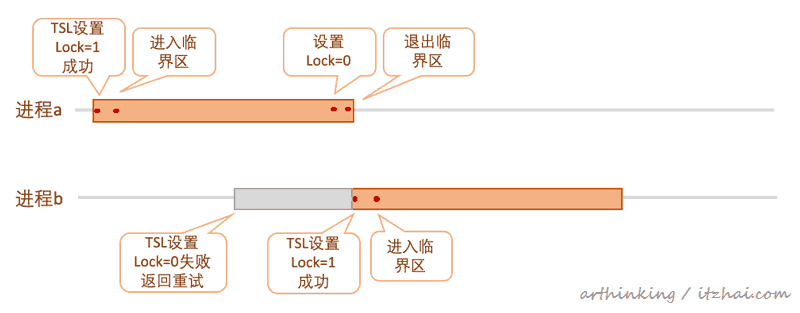
如果TSL原子操作没有成功,则重新跳转到enter_region方法循环执行。 这个跟Peterson算法有点类似,不过TSL可以支持任意多个进程的并发执行
CAS指令
指令格式:
cas 内存位置 旧预期值 新值
CAS存在ABA问题,可以使用版本号进行控制,保证其正确性。
2.2 进程挂起:睡眠与唤醒
以上的方法都是可以实现互斥的,但是存在忙等,导致浪费CPU时间的问题,如果同步资源锁定时间很短,那么这个等待还是值得的,但是如果锁占用时间过长,那么自旋就会浪费CPU资源了。
为了不浪费CPU资源,我们可以使用进程间通信的原语sleep和wakeup,sleep造成调用者阻塞,直到其他进程唤醒它。 根据经典的生产者消费者的问题,引出信号量以及阻塞的概念。
2.2.2、信号量
通过使用一个整型变量来累计唤醒次数,以供之后使用。 这个变量就是信号量。 可以通过以下方式操作这个变量:
down: 可以用sleep来表示,如果此刻信号量大于0,则将其值-1,如果=0,则进入进程进行睡眠;
up: 可以用wakeup来表示,up操作会使信号量+1,如果因为多个进程睡眠而无法完成先去的down操作,系统会选择一个进程唤醒并完成down操作,但信号量值仍是0,取而代之的是睡眠进程数量减1;
检查数值、修改变量值以及可能发生的睡眠或者唤起操作是原子性的。
信号量原理:
检查数值、修改变量值以及可能发生的休眠或者唤起操作是原子性的,通常将up和down作为系统调用来实现;
当执行以下操作时,操作系统暂时屏蔽全部中断: 检查信号量、更新、可能发生的休眠或者唤醒,这些操作需要很少的指令,因此中断不会造成影响;
如果是多核CPU,信号量同时会被保护起来,通过使用TSL或者XCHG指令确保同一个时刻只有一个CPU对信号量进行操作。
show me the code
#define N 100 /* 缓冲区中的槽数目 */ typedef int semaphore; /* 信号量是一种特殊的整型数据 */
semaphore mutex = 1; /* 控制对临界区的访问 */
semaphore empty = N; /* 计数缓冲区的空槽数目 */
semaphore full = 0; /* 计数缓冲区的满槽数目 */
void producer(void){ int item; while(TRUE){ /* TRUE是常量1 */ item = producer_item(); /* 产生放在缓冲区中的一些数据 */ down(&empty); /* 将空槽数目-1 */ down(&mutex); /* 进入临界区 */ insert_item(item); /* 将新数据放入缓冲区中 */ up(&mutex); /* 离开临界区 */ up(&full); /* 将满槽数目+1 */ } } void consumer(void){ int item; while(TRUE){ /* 无限循环 */ down(&full); /* 将满槽数目-1 */ down(&mutex); /* 进入临界区 */ item = remove_item(); /* 从缓冲区取出数据项 */ up(&mutex); /* 离开临界区 */ up(&empty); /* 将空槽数目+1 */ consume_item(item); /* 处理数据项 */ } }
每个进程在进入关键区域之前执行down操作,在离开关键区域之后执行up操作,这样就可以确保互斥了。 上面的代码实际上是通过两种不同的方式来使用信号量:
mutex: 用于互斥,确保任意时刻只有一个进程能够对缓冲区相关变量进行读写,互斥是用于避免进程混乱锁必须的一种操作;
full和empty: 通过计数,确保事件的发生或者不发生,这两个信号量的用意与mutex不同。
2.2.3、互斥量
如果仅仅是需要互斥,而不是计数能力,可以使用信号量的简单版本: mutex 互斥量。 一般用整型表示,通过调用:
mutex_lock: 进行加锁,如果加锁时处于解锁状态(0表示解锁,其他值表示加锁,比1大的值表示加锁的次数),则调用成功;
mutex_unlock: 进行解锁。
互斥量可以通过TSL或者XCHG指令实现,下面是用户线程包的mutex_lock和mutex_unlock的代码:
mutex_lock: TSL REGISTER,MUTEX | 将互斥信号量复制到寄存器,并且将互斥信号量置为1 CMP REGISTER,#0 | 互斥信号量是0吗? JZE ok | 如果互斥信号量为0,它被解锁,所以返回 CALL thread_yield | 互斥信号量忙;调度其他线程 JMP mutex_lock | 稍后再试 ok: RET | 返回调用者,进入临界区 mutex_unlock: MOVE MUTEX,#0 | 将mutex置为 0 RET | 返回调用者复制代码
由于thread_yield仅仅是一个用户空间的进程调度,所以它运行非常快捷。 这样mutex_lock和mutex_unlock都不需要任何内核调用,从而实现了在用户空间中的同步,这个过程仅仅需要少量的同步。
有些线程包也会提供mutex_trylock,尝试获取锁或者失败,让调用方自己决定是等待下去还是使用个替代方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号