

二分图最大匹配
模板题(公牛母牛配)
题目描述
\(n\)只公牛和\(m\)只母牛,
某些公牛和某些母牛互相喜欢。
但最后一只公牛只能和一只母牛建立一对一匹配。
要使得最后牛群匹配对数最大。
输入格式
第一行三个整数\(n,m,k(1\leq n,m\leq10^{4},0<k\leq10^{5})\)。
接下来\(k\)行,每行两个整数\(x,y,\)表示一条边,连接\(X\)集合中\(x\)点和\(Y\)集合的\(y\)点。
输出格式
只有一行。输出一个整数,表示牛群匹配对数最大值。
样例
输入
5 5 9
1 2
2 2
2 3
2 5
3 1
3 3
4 1
5 3
5 4
输出
5
算法讲解(重点)
此处引用老师的总结
二分图匹配问题是各类比赛的热门内容。涉及到的算法有:二分图最大匹配,二分图最佳匹配,\(König\)定理(最小覆盖问题)的证明与应用等等,但这些算法的根源在于匈牙利算法深透理解。
本文试图用通俗的讲解引导初学者了解匈牙利算法的操作细节。介于许多学生用交错轨解释匈牙利算法感到难以理解,本人写了这篇文章,算是一个尝试,希望给读者带来轻松的阅读。如果初学者看懂了这篇文章,还是要在百度查查关于匈牙利算法的专业描述,这样有助于后续内容的学习。
二分图:
顶点可以分类两个集合X和Y,所有的边关联的两个顶点,恰好一个属于集合X,另一个属于集合Y。图一般整理好之后如下:
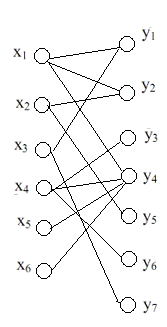
最大二分匹配:
假设\(X\)集合是公牛集合,\(Y\)集合是母牛集合,一条连接点\(x_{i}\)到点\(y_{i}\)的边,表示公牛\(x_{i}\)可以和母牛\(y_{i}\)可以配对。在一夫一妻制的前提下,求最大的配对数。这个问题可以用匈牙利算法解决。
【问题背景】
n只公牛和m只母牛,
某些公牛和某些母牛互相喜欢。
但最后一只公牛只能和一只母牛建立一对一匹配。
要使得最后牛群匹配对数最大。
【输入】
第一行三个整数\(n,m,k(1\leq n,m\leq10^{4},0<k\leq10^{5})\)。
下来\(k\)行,每行两个整数\(x,y,\)表示一条边,连接\(X\)集合中\(x\)点和\(Y\)集合的\(y\)点。
【输出】
只有一行。输出一个整数,表示牛群匹配对数最大值.
input:
5 5 9
1 2
2 2
2 3
2 5
3 1
3 3
4 1
5 3
5 4
output
5
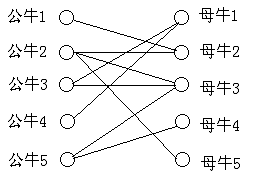
匈牙利算法:公牛逐个找母牛匹配。公牛\(x_1\)与母牛\(y_1\)有匹配关系\((map[x_1,y_1]==true),\)如果母牛\(y1\)尚未匹配\((match[y_1]==0),\)则匹配成功\((match[y_1]:=x_1),\)否则已匹配母牛\(y_1\)的公牛\(x_2(x_2:=match[y_1])\)尝试去匹配其他母牛,如果成功则\(A\)与\(B\)匹配成功,否则匹配失败。至于细节参考以下程序(按理解顺序给出):
数据结构:
int match[501]; //标记母牛的数组,match[i]为第i只母牛的匹配对象是第几只公牛
int n,m,ans,i; //n公牛数目,m母牛数目,ans为匹配对数
bool map[401][501] ; //map[i][j]==true表示第i只公牛和第j只母牛有匹配关系
bool chw[501]; // 也是标记母牛可否被“询问”的数组(“询问”后面有解释)。
//如果第i只母牛chw[i]==false,表示母牛i不可被询问,否则表示母牛i可被“询问”。
//匈牙利算法的关键点:chw数组
过程\(getmatch:\)从第1只到第n只公牛,逐个逐个寻找母牛匹配。
pvoid getmatch()
{
ans=0;//匹配对数初始化为0
memset(match,0,sizeof(match));//每只母牛初始化为未匹配(match[i]=0)
for(int i=1;i<=n;i++) //公牛逐个逐个找母牛
{
memset(chw,true,sizeof(chw)); //所有母牛初始化为可“询问”
if(find_muniu(i)==true)ans++;//如果找到了,总体增加一对 find_muniu(i)表示公牛i去找母牛
//思考:匹配成功的公牛会不会被后来的公牛抢了母牛?
}
}
\(Find()\)函数不能用,是系统内带的函数,会冲突的,比如\(x1,y1\)也一样,要避开这些命名
函数\(find\_muniu(k):\)判断第k只公牛能否匹配成功。
bool find_muniu(int k)
{
for(int i=1;i<=m;i++) //逐只母牛问
if (map[k][i]==true) //第k只公牛和第i只母牛有匹配关系
if (chw[i]==true)//问母牛i能否被“询问”
{
chw[i]=false; //标记母牛i已被询问,不管匹配成功与否,以后其他公牛都没必要再询问母牛i
if ( match[i]==0 || find_muniu(match[i])==true )
// match[i]=0 该母牛单身 或者 find(match[i])如果该母牛已匹配公牛x(x==match[i]),尝试让公牛x去找其他母牛匹配
{
match[i]=k;
return true; //这两句表示第i只母年匹配了第k只公牛}
}
}
return false;//执行到这一步表示匹配不成功。
}
“询问”:\(chw\)数组的意义。
意义一:如果第\(i\)只母牛 \(chw[i]==true\),表示第\(i\)只母牛有匹配成功的可能性。母牛i有未匹配和已匹配两种情况:
情况一:母牛\(i\)未匹配\((match[i]==0),\)那么简单直接\(match[i]==k,\)匹配成功;
情况二:母牛\(i\)已匹配\((X_1==match[i]),\)那么让公牛\(X_1\)尝试去寻找其他母牛匹配。公牛\(X_1\)不能再找母牛\(i\),否则成死循环。
意义二:如果第\(i\)只母牛\(chw[i]==false,\)公牛\(X_1\)也不能找已经被“询问”过的母牛\(j\),为什么?母牛\(j\)被标记为“询问”过,分两种情况:
情况一:之前被询问的时候匹配成功了,或 \(match[j]==0\)或\(find\_muniu(match[j])==true\)。但情况一是不可能的。因为如果匹配成功,那么就不会有后来的公牛\(X_1\)去找母牛j的需要。
情况二:之前被询问的时候匹配不成功。这种情况只能是母牛j已匹配,且匹配对象公牛\(X_2(X_2==match[j])\)找不到其他母牛匹配能成功\((\)也就是\(find\_muniu(X_2)==false)\)。如果之前有其他公牛询问母牛\(j\)都不能成功,那么现在的公牛\(X_1\)也一定不会成功,所以没有必要询问。\(chw\)数组的第二个意义剪支省时的作用。
主函数:
int main()
{
scanf("%d%d",&n,&m);//n只公牛,m只母年
memset(map,false,sizeof(map));//初始化匹配关系
for(int i=1;i<=n;i++)//读入边,构建图
{
int kk,y;scanf("%d",&kk); //混蛋,第i只公牛竟然能和kk只母牛匹配,她们是谁?
for(int j=1;j<=kk;j++)
{
scanf("%d",&y);
map[i][y]=true;
}
}
getmatch();
printf("%d\n",ans);//输出最大匹配对数
for(int i=1;i<=m;i++)//询问每只母牛有没有匹配到公牛
if(match[i]>0) //如果母牛i已经匹配,输出匹配了哪只公牛
printf("%d %d\n",match[i],i);
return 0;
}
\(find\)函数贪心思想正确性说明(分算法一和算法二说明):
算法一:
bool find_muniu(int k)
{
for(int i=1;i<=m;i++)
if (map[k][i]==true)
if (chw[i]==true)
{
chw[i]=false;
if ( match[i]==0 ) // 这里少了“|| find_muniu(match[i])==true”
{
match[i]=k;
return true;
}
}
return false;
}
那么匹配的结果为:\(4\)
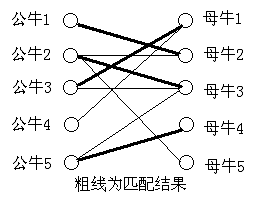
算法二:
bool find_muniu(int k)
{
for(int i=1;i<=m;i++)
if(map[k][i]==true)
if(chw[i]==true)
{
chw[i]=false;
if( match[i]==0 || find_muniu(match[i])==true )
{
match[i]=k;
return true;
}
}
return false;
}
那么匹配的结果为:\(5\)
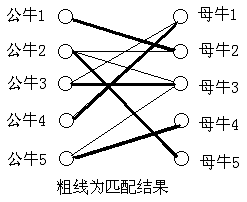
在公牛\(4\)之前结果为:
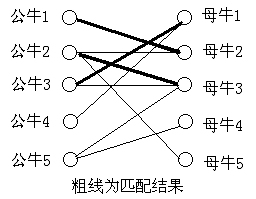
当\(getmatch\)过程中的\(i=4\)的时候,调用\(find\_muniu(4)\),公牛\(4\)唯有母牛\(1\)这个匹配对象,如果按算法一,则公牛\(4\)不能和母牛\(1\)匹配,然而算法二中,母牛\(1\)会报出之前匹配对象公牛\(3(match[1]=3)\),然后公牛\(3\) 问到母牛\(3\),母牛\(3\)报出公牛\(2\),公牛\(2\)找到母牛\(5\),匹配成功。于是公牛\(2\)匹配母牛\(5\), 公牛\(3\) 匹配母牛\(3\),公牛\(4\)匹配母牛\(1\),皆大欢喜,在不损害已匹配公牛的利益的基础上,总匹配对数增加一对。
总结:
由此我们可以看出,假设公牛\(x\)想匹配母牛\(y\),如果母牛\(y\)未匹配\((match[y]=0)\),那么可以直接匹配成功;如果\(match[y]\neq0\)(即母牛\(y\)已匹配),那么找出公牛\(xx=match[y]\),在确保公牛\(xx\)可以找到其他母牛匹配,那么公牛\(x\)和母牛\(y\)才能匹配。这点保证了匈牙利算法贪心思想的正确性。
代码
#include<cstdio>
#include<cstring>
using namespace std;
struct node
{
int x,y,next;
}a[210000];int len,last[11000];//链表
void ins(int x,int y)
{
++len;
a[len].x=x;a[len].y=y;
a[len].next=last[x];last[x]=len;
}
int match[11000];bool chw[11000];
bool find(int x)
{
for(int k=last[x];k;k=a[k].next)//链表,不会的去查,开map数组1万乘1万会炸
{
int y=a[k].y;
if(chw[y])
{
chw[y]=false;
if(match[y]==0||find(match[y]))
{
match[y]=x;
return true;
}
}
}
return false;
}
int main()
{
// freopen("1122.in","r",stdin);
// freopen("1122.out","w",stdout);
len=0;memset(last,0,sizeof(last));
ri n,m,k;scanf("%d%d%d",&n,&m,&k);
for(int i=1;i<=k;++i)
{
int x,y;scanf("%d%d",&x,&y);
ins(x,y);
}
int ans=0;
memset(match,0,sizeof(match));
for(int i=1;i<=n;++i)
{
memset(chw,true,sizeof(chw));
if(find(i))ans++;
}
printf("%d\n",ans);
return 0;
}
二分图最小覆盖
模板题
题目描述
\(X\)集合有\(n\)个点\((\)编号\(1,2,3,……n),\)
\(Y\)集合有\(m\)个点\((\)编号\(1,2,3,……m),\)
有\(k\)条边\((\)任意一条边的两个端点,一个来自\(X\)集合,一个来自\(Y\)集合\()\)
如果选中一个点\((\)可以来自\(X\)集合或\(Y\)集合\()\)就是燃烧掉所有与该点相连的边。
问:至少选中多少个点,可以摧毁所有边\((\)也就是\(k\)条边\()\)
输入格式
第一行三个整数\(n,m,k(1\leq n,m\leq10^{4},0<k\leq10^{5})\)。
接下来\(k\)行,每行两个整数\(x,y,\)表示一条边,连接\(X\)集合中\(x\)点和\(Y\)集合的\(y\)点。
输出格式
一个整数,为最少选中的点数目。
样例
输入
4 5 8
1 3
2 1
2 2
2 4
3 3
4 3
4 4
4 5
输出
3
算法讲解(重点)
按题意构图后,用匈牙利算法求最大二分匹配数,就是答案!
なんですか(什么)?! 不急,等我慢慢解释:为什么最大二分匹配数等于最小点覆盖数。
首先建完边之后就是这样。

匹配完之后是这样

删点后是

我们惊奇地发现边都不见了
匈牙利算法是查找最大匹配,然鹅\((\)鹅\(:?)\)这些匹配点已经将所有边都给包含了,如果还有其他边的话,在匹配时就会匹配那两个点。也就没有那条边了。
例如再这样时\(:\)

删点后成这样
然而还能匹配

删掉后
才是答案
代码
#include<cstdio>
#include<cstring>
using namespace std;
struct node
{
int x,y,next;
}a[210000];int len,last[11000];
void ins(int x,int y)
{
++len;
a[len].x=x;a[len].y=y;
a[len].next=last[x];last[x]=len;
}
int match[11000];bool chw[11000];
bool find(int x)
{
for(int k=last[x];k;k=a[k].next)
{
int y=a[k].y;
if(chw[y])
{
chw[y]=false;
if(match[y]==0||find(match[y]))
{
match[y]=x;
return true;
}
}
}
return false;
}
int main()
{
// freopen("1125.in","r",stdin);
// freopen("1125.out","w",stdout);
len=0;memset(last,0,sizeof(last));
ri n,m,k;scanf("%d%d%d",&n,&m,&k);
for(int i=1;i<=k;++i)
{
int x,y;scanf("%d%d",&x,&y);
ins(x,y);
}
int ans=0;
memset(match,0,sizeof(match));
for(int i=1;i<=n;++i)
{
memset(chw,true,sizeof(chw));
if(find(i))ans++;
}
printf("%d\n",ans);
return 0;
}
