python 序列化之JSON和pickle详解
JSON模块
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。 JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C、C++、Java、JavaScript、Perl、Python等)。这些特性使JSON成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成(一般用于提升网络传输速率)。
JSON在python中分别由list和dict组成。
一、python类型数据和JSON数据格式互相转换
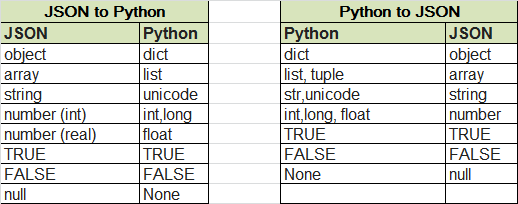
pthon 中str类型到JSON中转为unicode类型,None转为null,dict对应object
二、数据encoding和decoding
1、简单类型数据编解码
所谓简单类型就是指上表中出现的python类型。
dumps: 将对象序列化
#coding:utf-8 import json # 简单编码=========================================== print json.dumps(['foo', {'bar': ('baz', None, 1.0, 2)}]) # ["foo", {"bar": ["baz", null, 1.0, 2]}] #字典排序 print json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True) # {"a": 0, "b": 0, "c": 0} #自定义分隔符 print json.dumps([1,2,3,{'4': 5, '6': 7}], sort_keys=True, separators=(',',':')) # [1,2,3,{"4":5,"6":7}] print json.dumps([1,2,3,{'4': 5, '6': 7}], sort_keys=True, separators=('/','-')) # [1/2/3/{"4"-5/"6"-7}] #增加缩进,增强可读性,但缩进空格会使数据变大 print json.dumps({'4': 5, '6': 7}, sort_keys=True,indent=2, separators=(',', ': ')) # { # "4": 5, # "6": 7 # }
# 另一个比较有用的dumps参数是skipkeys,默认为False。
# dumps方法存储dict对象时,key必须是str类型,如果出现了其他类型的话,那么会产生TypeError异常,如果开启该参数,设为True的话,会忽略这个key。
data = {'a':1,(1,2):123}
print json.dumps(data,skipkeys=True)
#{"a": 1}
dump: 将对象序列化并保存到文件
#将对象序列化并保存到文件 obj = ['foo', {'bar': ('baz', None, 1.0, 2)}] with open(r"c:\json.txt","w+") as f: json.dump(obj,f)
loads: 将序列化字符串反序列化
import json obj = ['foo', {'bar': ('baz', None, 1.0, 2)}] a= json.dumps(obj) print json.loads(a) # [u'foo', {u'bar': [u'baz', None, 1.0, 2]}]
load: 将序列化字符串从文件读取并反序列化
with open(r"c:\json.txt","r") as f: print json.load(f)
三、自定义复杂数据类型编解码
例如我们碰到对象datetime,或者自定义的类对象等json默认不支持的数据类型时,我们就需要自定义编解码函数。有两种方法来实现自定义编解码。
1、方法一:自定义编解码函数
#! /usr/bin/env python # -*- coding:utf-8 -*- # __author__ = "TKQ" import datetime,json dt = datetime.datetime.now() def time2str(obj): #python to json if isinstance(obj, datetime.datetime): json_str = {"datetime":obj.strftime("%Y-%m-%d %X")} return json_str return obj def str2time(json_obj): #json to python if "datetime" in json_obj: date_str,time_str = json_obj["datetime"].split(' ') date = [int(x) for x in date_str.split('-')] time = [int(x) for x in time_str.split(':')] dt = datetime.datetime(date[0],date[1], date[2], time[0],time[1], time[2]) return dt return json_obj a = json.dumps(dt,default=time2str) print a # {"datetime": "2016-10-27 17:38:31"} print json.loads(a,object_hook=str2time) # 2016-10-27 17:38:31
2、方法二:继承JSONEncoder和JSONDecoder类,重写相关方法
#! /usr/bin/env python # -*- coding:utf-8 -*- # __author__ = "TKQ" import datetime,json dt = datetime.datetime.now() dd = [dt,[1,2,3]] class MyEncoder(json.JSONEncoder): def default(self,obj): #python to json if isinstance(obj, datetime.datetime): json_str = {"datetime":obj.strftime("%Y-%m-%d %X")} return json_str return obj class MyDecoder(json.JSONDecoder): def __init__(self): json.JSONDecoder.__init__(self, object_hook=self.str2time) def str2time(self,json_obj): #json to python if "datetime" in json_obj: date_str,time_str = json_obj["datetime"].split(' ') date = [int(x) for x in date_str.split('-')] time = [int(x) for x in time_str.split(':')] dt = datetime.datetime(date[0],date[1], date[2], time[0],time[1], time[2]) return dt return json_obj # a = json.dumps(dt,default=time2str) a =MyEncoder().encode(dd) print a # [{"datetime": "2016-10-27 18:14:54"}, [1, 2, 3]] print MyDecoder().decode(a) # [datetime.datetime(2016, 10, 27, 18, 14, 54), [1, 2, 3]]
===========================================================
pickle模块
python的pickle模块实现了python的所有数据序列和反序列化。基本上功能使用和JSON模块没有太大区别,方法也同样是dumps/dump和loads/load。cPickle是pickle模块的C语言编译版本相对速度更快。
与JSON不同的是pickle不是用于多种语言间的数据传输,它仅作为python对象的持久化或者python程序间进行互相传输对象的方法,因此它支持了python所有的数据类型。
pickle反序列化后的对象与原对象是等值的副本对象,类似与deepcopy。
dumps/dump序列化
from datetime import date try: import cPickle as pickle #python 2 except ImportError as e: import pickle #python 3 src_dic = {"date":date.today(),"oth":([1,"a"],None,True,False),} det_str = pickle.dumps(src_dic) print det_str # (dp1 # S'date' # p2 # cdatetime # date # p3 # (S'\x07\xe0\n\x1b' # tRp4 # sS'oth' # p5 # ((lp6 # I1 # aS'a' # aNI01 # I00 # tp7 # s. with open(r"c:\pickle.txt","w") as f: pickle.dump(src_dic,f)
loads/load反序列化
from datetime import date try: import cPickle as pickle #python 2 except ImportError as e: import pickle #python 3 src_dic = {"date":date.today(),"oth":([1,"a"],None,True,False),} det_str = pickle.dumps(src_dic) with open(r"c:\pickle.txt","r") as f: print pickle.load(f) # {'date': datetime.date(2016, 10, 27), 'oth': ([1, 'a'], None, True, False)}
JSON和pickle模块的区别
1、JSON只能处理基本数据类型。pickle能处理所有Python的数据类型。
2、JSON用于各种语言之间的字符转换。pickle用于Python程序对象的持久化或者Python程序间对象网络传输,但不同版本的Python序列化可能还有差异。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号