python-爬虫scrapy框架安装及基本使用
今日内容#
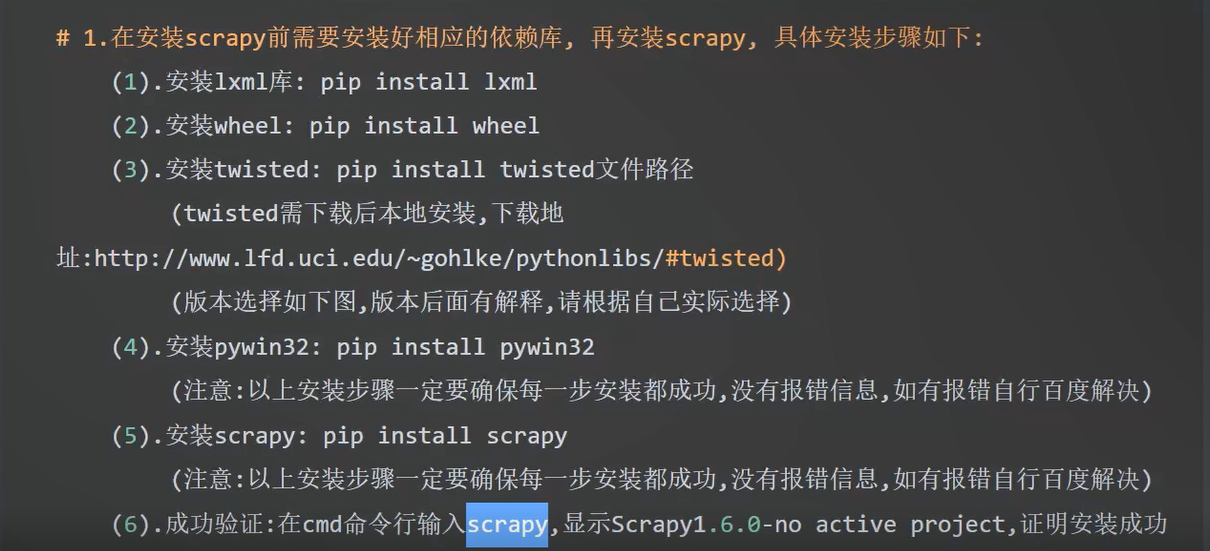
1.安装与配置#
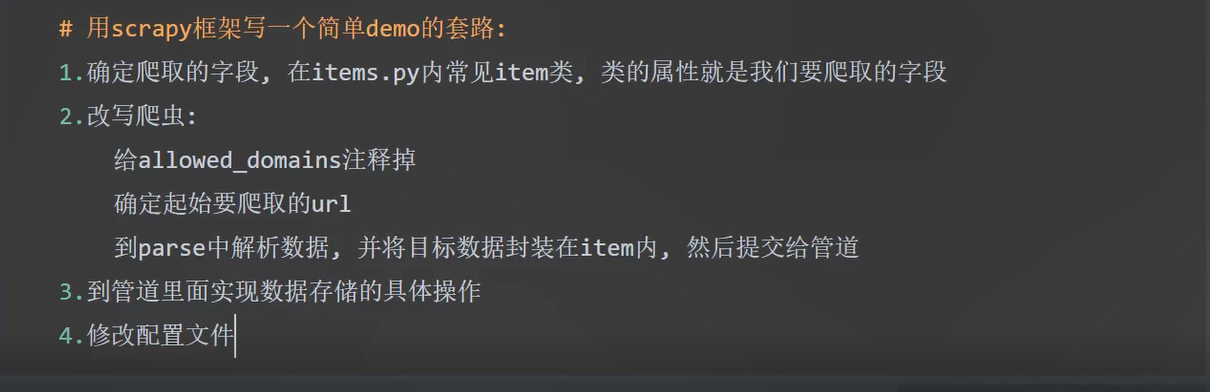
2.创建项目#
# scrapy
scrapy startproject 项目名 #创建项目
scrapy genspider 文件名 baidu.com #创建爬虫
#运行
scrapy crawl 文件名
scrapy crawl 文件名 --nolog #运行命令 ---nolog就是不在控制台打印日志
#注意事项:
--nolog:不打印日志,同样如果抛出异常,也不会打印异常
3.工程目录的介绍#

4.核心组件与数据流向#
#五大核心组件
1.引擎组件:整个框架的调度者,负责各个组件之间的通信与数据的传递
2.爬虫组件:定义爬取行为和解析规则
3.调度器组件:负责调度所有请求
4.下载器:负责爬取页面
5.管道:负责数据持久化

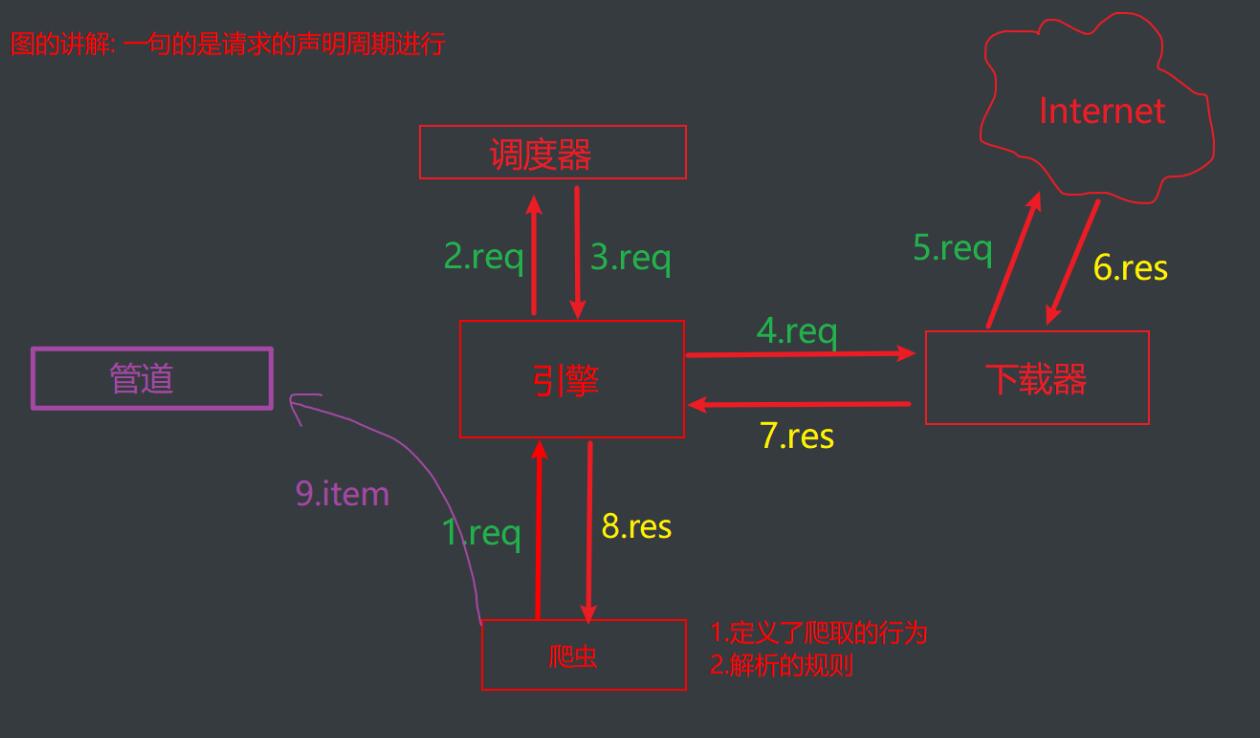
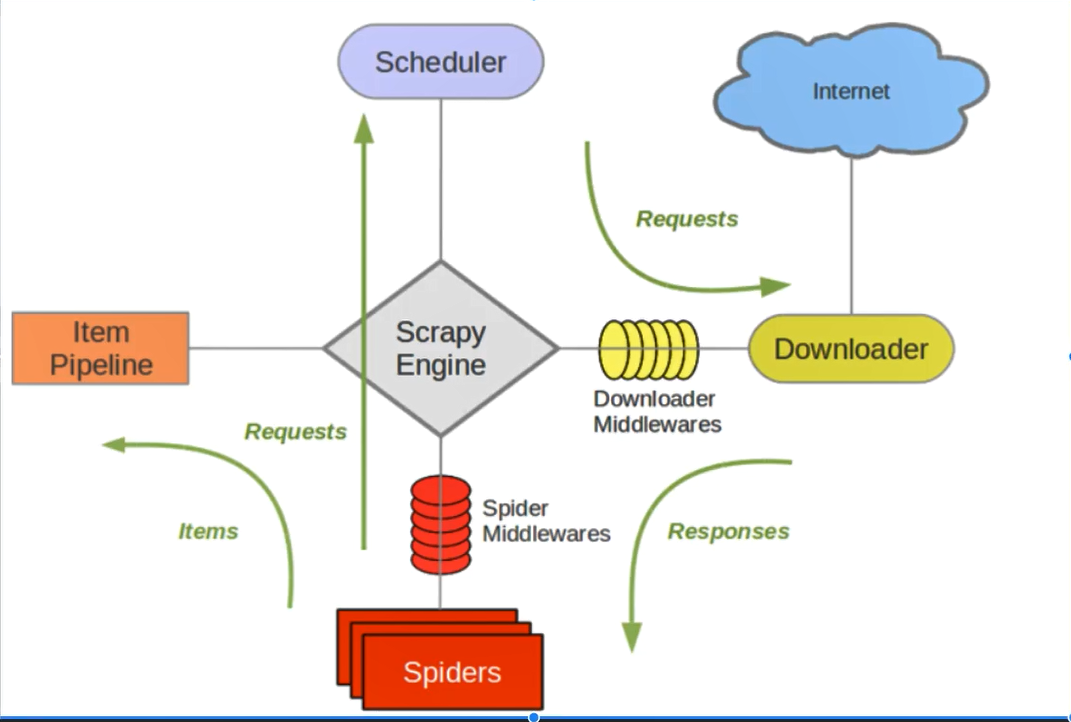
req是请求 res是获取到的数据#
这个图比较标准#
作者:就学45分钟
出处:https://www.cnblogs.com/tjw-bk/p/13752072.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了