python-爬虫概念
爬虫#
1、爬虫的概念#
-
什么是爬虫#
爬虫:网络爬虫机器人,从互联网自动抓取数据的程序
-
爬虫分类#
-
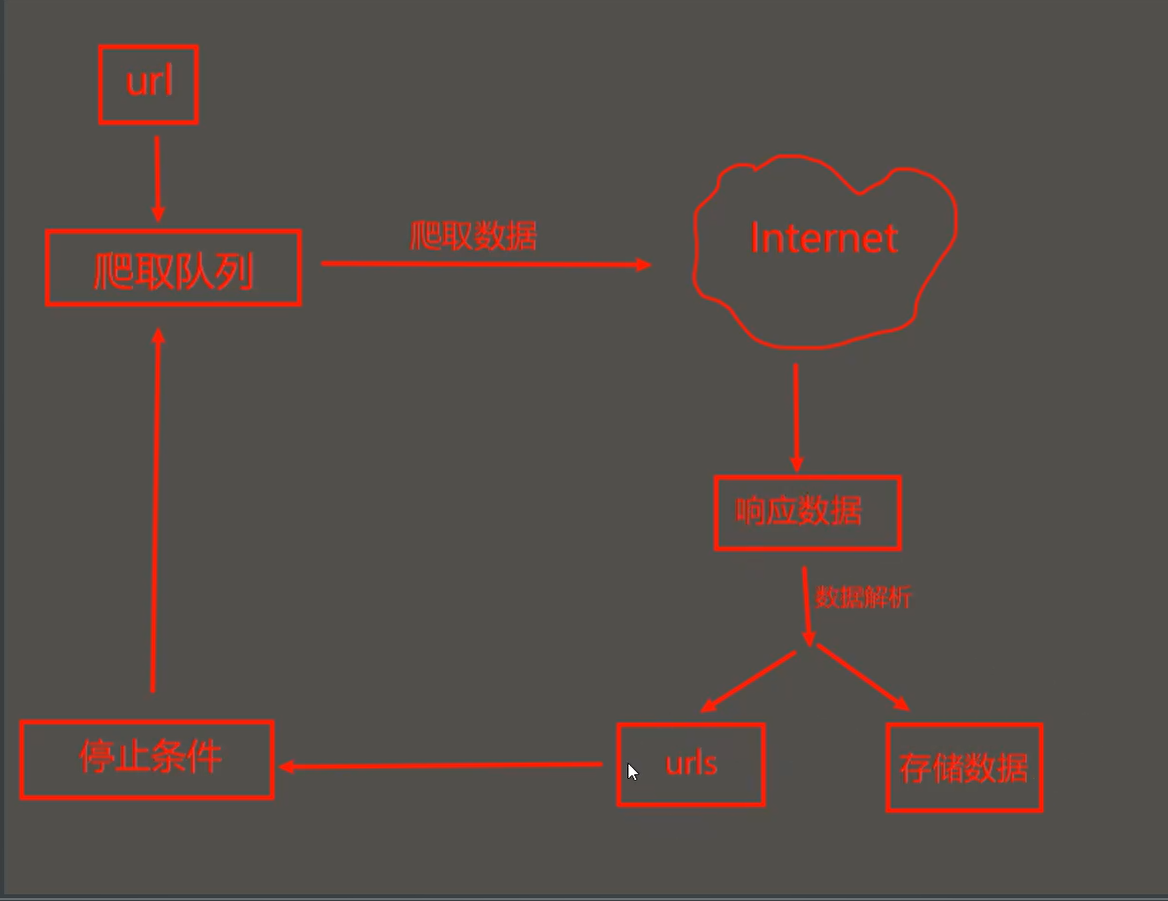
通用爬虫
通用网络爬虫:是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
工作原理:
-
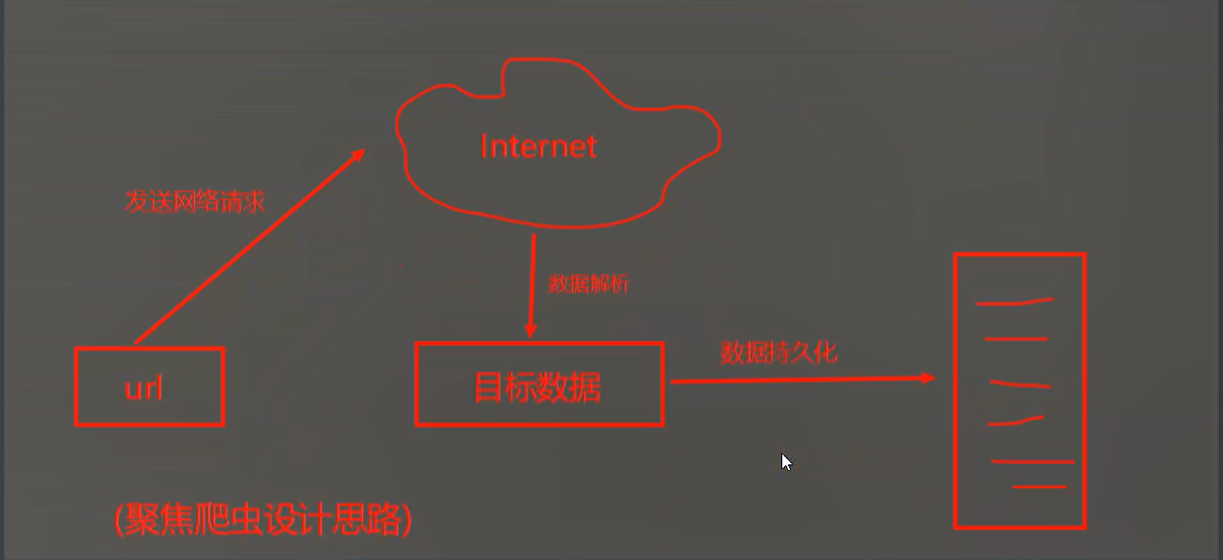
聚焦爬虫
聚焦爬虫:聚焦爬虫是面向主题的爬虫,再爬取数据的过程中会对数据进行筛选往往只会爬虫与需求相关的数据
聚焦爬虫的设计思路:
1.确定爬取的url,模拟浏览器向服务器发送请求
2.获取响应数据并进行数据分析
3.将目标数据持久化到本地工作原理:
4、Robot.txt 是什么,里面的参数是什么意思#
Robots协议:(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取
User-agent:(识别是哪家的爬虫
-
Allow: 允许爬取的目录
Disallow: 不允许爬取的目录
5、OSI七层协议(无论是面试的时候还是笔试,都必须按照顺序说)#
应用层,表示层,会话层,传输层,网络层,数据链路层,物理层
6.TCP/IP五层协议(无论是面试的时候还是笔试,都必须按照顺序说)#
应用层、传输层、网络层、数据链路层、物理层
7、总结HTTPS和HTTP的区别#
-
HTTPS是HTTP协议的安全版本,HTTP协议的数据传输是明文的,是不安全的,HTTPS使用了SSL/TLS协议进行了加密处理。
- http和https使用连接方式不同,默认端口也不一样,http是80,https是443。
8、TCP和UDP的区别#

作者:就学45分钟
出处:https://www.cnblogs.com/tjw-bk/p/13751817.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了