day_08 文件操作
常用模式解释
open表示打开一个文件
f 变量, 操控XXX.txt文件的句柄
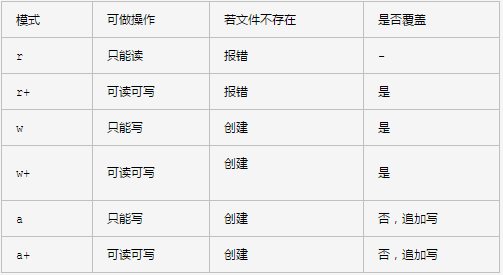
r:只读
w:只写
a:追加写入
b:byte,这种模式下,encoding不能用utf-8字符集
1. 文件的基本操作 1.读取 1. f=open("xxx",mode="r",encodin="utf-8") content=f.read() 一次性的全部读取出来 ,不推荐使用 print(content) f.close() 2. f=open("xxx",mode="r",encoding="utf-8") content=f.read(n) 读取n个字符,如果继续读取,将会从当前位置继续读取n个字符 print(content) f.close 3. f=open("xxx",mode="r",encoding="utf-8") content=readline() 一次读取一行,readline()结尾后面会带着一个/n所以用strip()去掉 print(content.strip()) f.close() 4. f=open("xxxx",mode="r",encoding="utf-8") content=f.readlines() 一次全部读取出来,返回的是列表,每行都是一个元素,不推荐使用 print(content) f.close 5.循环读取 f=open("xxx",mode="r",encoding="utf-8") for line in f: print(line.strip()) f.clsose 注意:读取完毕一定要关闭句柄.close()
2.写 1. f=open("xx",mode="w",encoding="utf-8") f.write("XXX\n") 如果文件不存在,则会常见文件,如果文件存在,则会把文件清空之后再写入 f.close() 在写的模式下,是不允许读取的 2. f=open("xxx",mode="a",encoding ="utf-8") f.write("xxx\n") 只要是在a,ab ,a+模式下都是在文件末尾追加的.不论光标在哪个位置 f.close() 3. 文本文档的复制 f1=open("xxx",mode="r",encoding="utf-8") 因为 f2=open("xxx",mode="w",encoding="utf-8") for line in f1: 从f1读取数据 f2.write(line) 在f2写入数据 f1.close() f2.close() 4. 文件复制的 使用于所有文件 f1=open("xxx",mode="rb") f2=open("xxx",mode="wb") for line in f1; f2.write(line)
5. 读写r+ f=open("xxx",mode="r+",encodin="utf-8") content=f.read() 坑: 不论你读取多少内容。再次写入的时候都是在末尾 f.write("xxx") r+正常的操作是先读取后写入 print(content) 如果是先写入后读取,会把开头部分覆盖掉 6. 写读w+ f=open("xx",mode="w+",encoding="utf-8") f.write("xx") 先清空后写入,所以先读也是读取不到内容的 content=f.read() 光标在最后,所以读取不到内容 print(content) 7.追加写入a+ f=open("xxx",mode="a+",encoding="utf-8") f.write("xx") 追加写入在末尾,因为光标在末尾,所以无论先读还是写完再读都没有内容 content=f1.read() print(content)
8. 其他相关操作 seek(n),光标移动的位置,这里的单位是byte,所以utf-8中文部分要移动3的倍数. seek(参数1,参数2) 参数1表示的是偏移量,移动了多长距离 0开头位置 1当前位置 2末尾 seek(0) 光标移动到开头 seek(0,2)光标移动到末尾 print(f.tell())获取光标当前位置 9. truncate() 截断文件. 慎用 尽量不要瞎测试, w, w+ f = open(r"xxxx", mode="r+", encoding="utf-8") f.seek(5) 光标移动到5 f.truncate() 默认从开头截取到光标位置 f.truncate(3) 从头截取到3 f.close()
10. 文件的修改以及另一种打开文件的方式 impor os with open("xx",mode="r",encoding="utf-8") as f1,\ open("xx_new",mode="w",encoding="utf-8") as f2: content=f1.read() new_content=content.replace("xx","xx") f2.write(new_content) os.remove(f1) 删除源文件 os.rename("xx_new","xx") 重命名新文件 一次性读取伤内存 import os with open("xx",mode="r",encoding="utf-8") as f1,/ open("xx_new",mode="w",encoding="utf-8") as f2: for line in f1: line_new=line.replace("xx","yy") f2.write(line_new) os.remove("xx") os.rename("xx","zz")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号