这个数据库用起来刚刚好
我的公众号是使用Bear这个Mac App来写的。它在官网上写到,所有笔记数据通过SQLite来储存,如下图所示。

SQLite是一个基于文件的关系型数据库,它只有一个文件,但是却最多能储存140TB的数据[1]。
SQLite官网给出了一个判断是否适合使用 SQLite 的标准:
- 如果程序和数据分离且它们通过互联网连接,那么不适合用 SQLite
- 高并发写入,那么不适合用 SQLite
- 如果数据量非常大,那么不适合 SQLite
- 除此之外,选择 SQLite
Linux/macOS 系统都自带 SQLite 数据库,并且使用 Python 自带的模块就能轻易读写 SQLite。本文演示一下 SQLite 的增删改查和联表查询。
创建数据表
SQLite 里面,一个文件就是一个库。所以我们只需要创建数据表就可以了。方法非常简单:

import sqlite3 conn = sqlite3.connect('kingname.db') with conn: conn.execute(''' CREATE TABLE user ( name TEXT, age INTEGER, address TEXT, id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT); ''')
运行如下图所示:


通过这种方式,我们在当前文件夹下面创建了一个叫做kingname.db的数据库文件,并创建了一个叫做user的表。sqlite3库的数据库链接对象支持上下文管理器,所以只需要with conn:就可以执行 SQL 语句,不需要创建游标。退出缩进时,SQL 语句会自动提交生效。
写入数据
现在我们来写入几条数据:
sql = 'insert into user (id, name, age, address) values(?, ?, ?, ?)' datas = [ (1, 'kingname', 20, '浙江省杭州市'), (2, '产品经理', 18, '上海市'), (3, '胖头猪', 8, '吃屁岛') ] with conn: conn.executemany(sql, datas)
运行效果如下图所示:
macOS 上有一个软件叫做 DB Browser for SQLite,可以用来查看我们刚才创建的数据表是否成功:
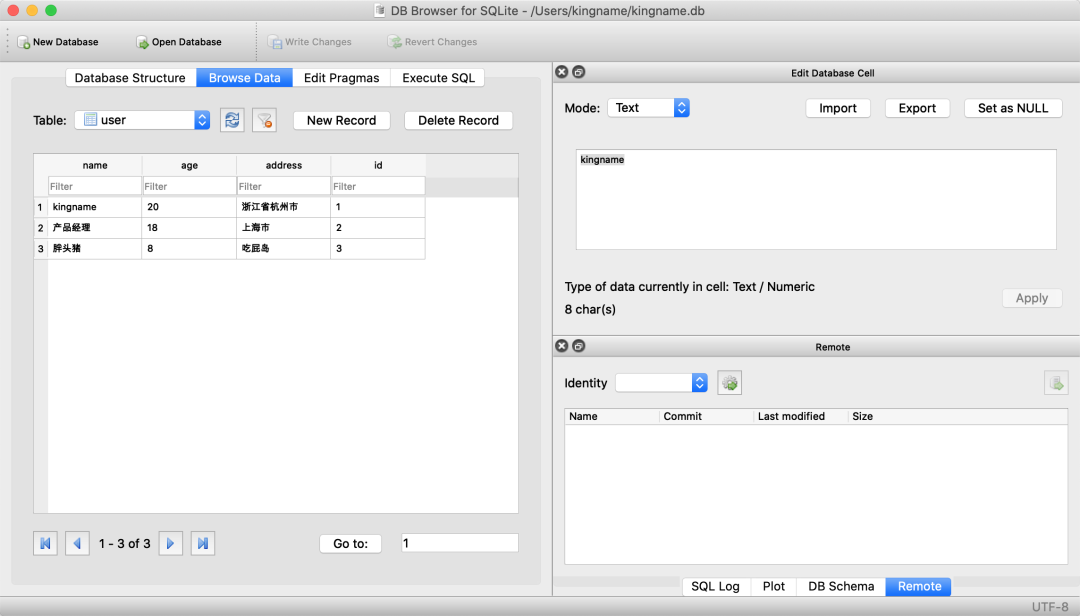
查询数据
使用 SQL 语句也可以查看数据:
with conn: datas = conn.execute("select * from user where name = 'kingname'") for data in datas: print(data)
运行效果如下图所示:
当然,通过修改row_factory也可以通过列名来读取 数据:
conn.row_factory = sqlite3.Row with conn: datas = conn.execute("select * from user where name = 'kingname'") for data in datas: print(data['address'])
运行效果如下图所示: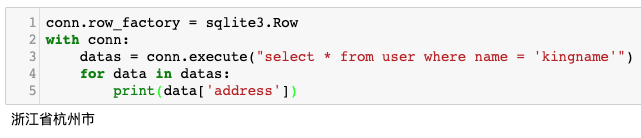
删除数据
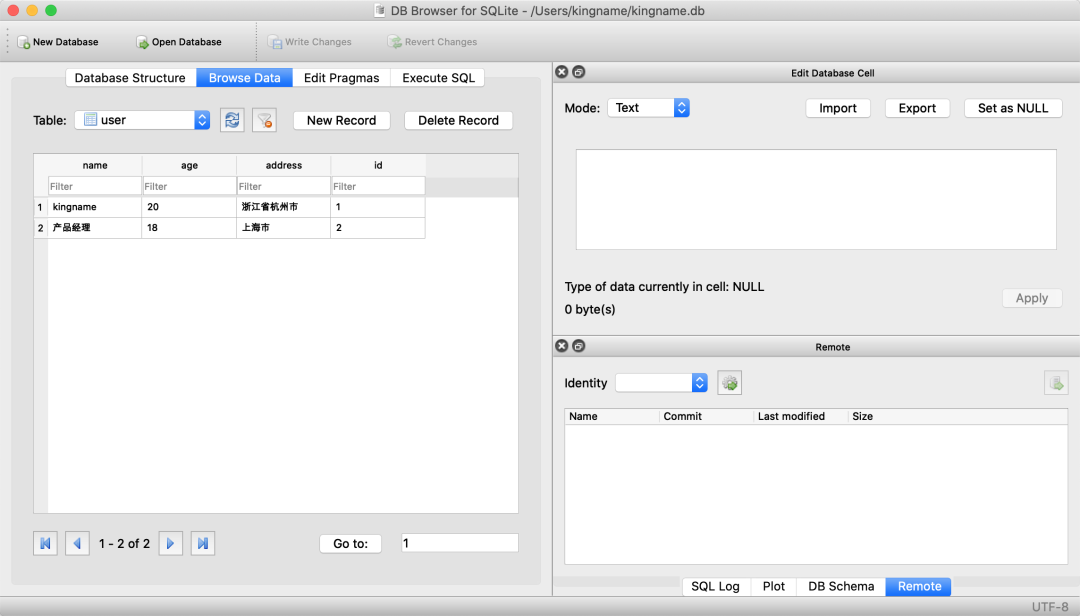
与其他操作一样,删除数据只需要写对应的 SQL 语句即可:
with conn: conn.execute('delete from user where id = 3')
运行效果如下图所示:
联表查询
本质上还是 SQL 语句的改变,我们先创建另外一个表:
with conn: conn.execute(''' CREATE TABLE info ( user_id INTEGER, salary integer, id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT); ''') sql = 'insert into info (user_id, salary) values(?, ?)' datas = [ (1, 99999999), (2, 0), ] conn.executemany(sql, datas)
接下来进行一个联表查询:
with conn: sql = 'select u.name as name, i.salary as salary from user u inner join info i on u.id=i.user_id' datas = conn.execute(sql) for data in datas: print(f'{data["name"]}的工资是:{data["salary"]}')
运行效果如下图所示:
总结
对于低并发量,程序与数据放在一起的情况,可以使用 SQLite 来存放,它比单独写一个文本文件来存放数据更加可控,更加友好。而且使用 Python 操作 SQLite 只需要使用自带的模块sqlite3即可。当你要把数据交给其他人时,你只需要把生成的这个.db文件交给别人就好了。他们使用任何支持 SQLite 的工具都能打开。
参考资料
[1]
最多能储存140TB的数据: https://www.sqlite.org/whentouse.html
转自:微信公众号:未闻code


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
2019-03-09 vue指令与事件修饰符