Python 爬虫时,如何替换 URL 中的 query 字段?
在我们写爬虫的时候,可能会需要在爬虫里面基于当前url生成一个新的url。例如下面这段伪代码:
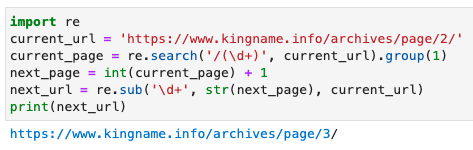
import re current_url = 'https://www.kingname.info/archives/page/2/' current_page = re.search('/(\d+)', current_url).group(1) next_page = int(current_page) + 1 next_url = re.sub('\d+', str(next_page), current_url) make_request(next_url)
运行效果如下图所示:
但有时候,翻页参数不一定是数字。例如有些网站,访问一个URL:
https://xxx.com/articlelist?category=technology&after=asdrtJKSAZFD
当你访问这个url的时候,它返回的是一个JSON字符串,并且这个JSON里面,有如下字段:

... "paging": { "cursors": { "before": "MTA3NDU0NDExNDEzNTgz", "after": "MTE4OTc5MjU0NDQ4NTkwMgZDZD" }, } ...
这种情况多见于信息流网站。它只能无限下滑看下一页,不能直接通过页数跳页。每次请求的时候返回下一页的参数after。当要访问下一页的时候,用这个参数替换当前url中的after=后面的参数。
这样一来,替换url中的参数就并不是一件简单的事情了。因为网址可能有4种情况:
- 第一页,没有after参数:
https://xxx.com/articlelist?category=technology - 第一页,有after参数名但没有值:
https://xxx.com/articlelist?category=technology&after= - 后续页面,after参数值后面没有内容:
https://xxx.com/articlelist?category=technology&after=asdrtJKSAZFD - 后续页面,aster参数值后面有内容:
https://xxx.com/articlelist?category=technology&after=asdrtJKSAZFD&other=abc
大家可以试一试,如果用正则表达式,怎么覆盖这4种情况,生成下一页的网址。
实际上,我们不需要使用正则表达式。Python自带的urllib模块已经提供了解决这个问题的方案了。我们先来看一段代码:
from urllib.parse import urlparse, urlunparse, parse_qs, urlencode def replace_field(url, name, value): parse = urlparse(url) query = parse.query query_pair = parse_qs(query) query_pair[name] = value new_query = urlencode(query_pair, doseq=True) new_parse = parse._replace(query=new_query) next_page = urlunparse(new_parse) return next_page url_list = [ 'https://xxx.com/articlelist?category=technology', 'https://xxx.com/articlelist?category=technology&after=', 'https://xxx.com/articlelist?category=technology&after=asdrtJKSAZFD', 'https://xxx.com/articlelist?category=technology&after=asdrtJKSAZFD&other=abc' ] for url in url_list: next_page = replace_field(url, 'after', '0000000') print(next_page)
运行效果如下图所示:

从图中可以看到,这4种情况,都可以被我们成功添加下一页的参数after= 0000000。不用再去考虑正则表达式怎么适配所有情况。
其中urlparse 和urlunparse 是一对相反函数,前者把网址转成 ParseResult 对象,后者把ParseResult对象转回网址字符串。
ParseResult 对象的.query 属性,是一个字符串,也就是网址中,问号后面的内容,格式如下:

parse_qs与urlencode也是一对相反函数。其中前者把 .query输出的字符串转成字典,而后者把字段转成.query形式的字符串:
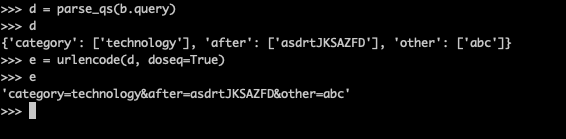
当使用parse_qs把 query转成字典以后,就可以修改参数的值,然后再重新转回去。
由于ParseResult对象的.query属性是只读属性,不能覆盖,因此我们需要调用一个内部方法._replace把新的.query字段替换上去,生成新的 ParseResult对象。最后再把它转回网址。
以上,就是今天我们介绍的,如何使用urllib自带的函数替换网址中的字段。
转自:微信公众号:未闻code


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
2019-03-09 vue指令与事件修饰符