关于re.sub从匹配的文本中处理后之际替换匹配匹配到的数据
以往我们进行一个正则替换都是直接把和模板匹配到的文本直接替换成一个写死的文本,如:
import re a = 'asdad123456asdasd' b = re.sub("\d", "*", a) print(b)
但是呢,现在我们有个需求,从匹配的文本中进行一个提取和处理,在替换回来,这个怎么做呢?
看下re.sub的源码:
def sub(pattern, repl, string, count=0, flags=0): """Return the string obtained by replacing the leftmost non-overlapping occurrences of the pattern in string by the replacement repl. repl can be either a string or a callable; if a string, backslash escapes in it are processed. If it is a callable, it's passed the Match object and must return a replacement string to be used.""" return _compile(pattern, flags).sub(repl, string, count)
使用方式一:
如果第二个参数是函数,那么它需要接收一个参数,这个参数是一个match对象。如下图所示:
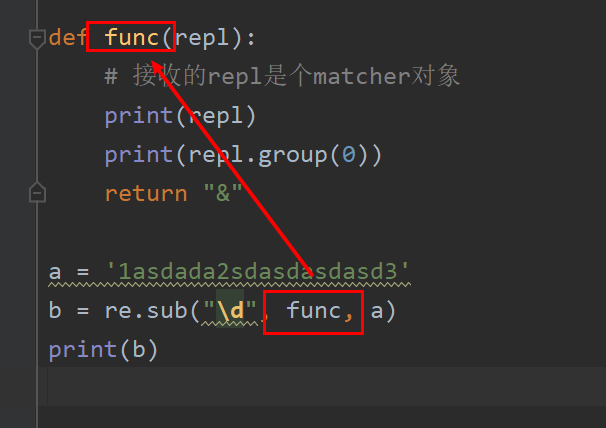
<re.Match object; span=(0, 1), match='1'> 1 <re.Match object; span=(7, 8), match='2'> 2 <re.Match object; span=(19, 20), match='3'> 3 &asdada&sdasdasdasd&
原字符串中有多少项被匹配到,这个函数就会被调用几次。
至于传进来的这个match对象,我们调用它的.group(0)方法,就能获取到被匹配到的内容,
使用方式二:
匿名函数:
import re a = '1asdada2sdasdasdasd3' js_pattern="<scrpit.*?src=(.*?).*?>" result=re.sub(js_pattern,lambda m:m.group(1).split("?")[0],a)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号