为什么你用Scrapy 无法使用 Cookies登录
我们知道,网站使用 Cookies 来记录用户的登录状态。如果我们从浏览器中把 Cookies 复制下来,放到爬虫中,在某些情况下,就可以让爬虫直接访问到登录后的页面。
以练习页面http://exercise.kingname.info/exercise_login_success为例。在没有登录的情况下,访问这个地址,会自动跳转到登录页面,如下图所示:
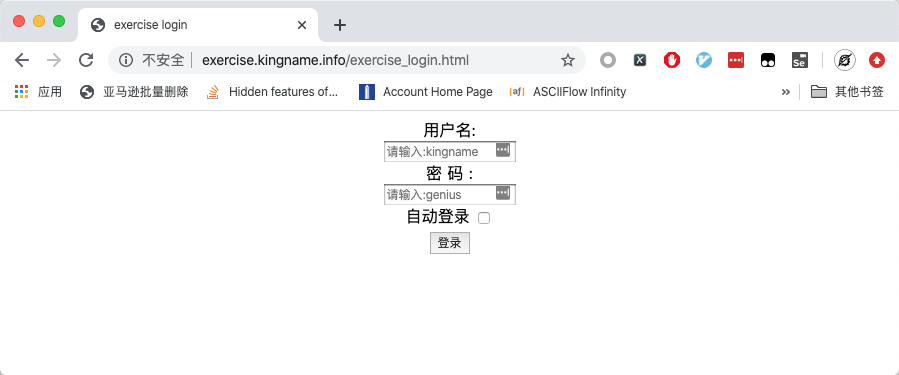
输入用户名kingname,密码genius,点选自动登录,并点击登录按钮,跳转到登录成功的页面,如下图所示:
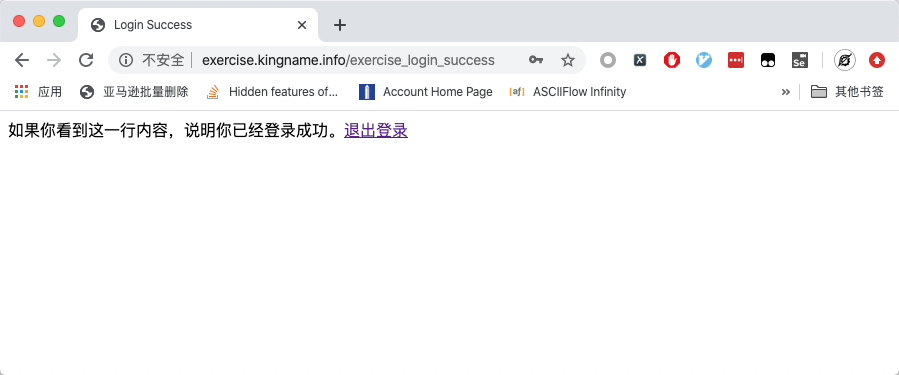
一旦登录成功,即使关闭浏览器再重新打开该网址,依然会直接进入登录后的页面。
我们在 Chrome 的开发者工具中可以看到在登录后,当我们刷新页面时发送的请求:
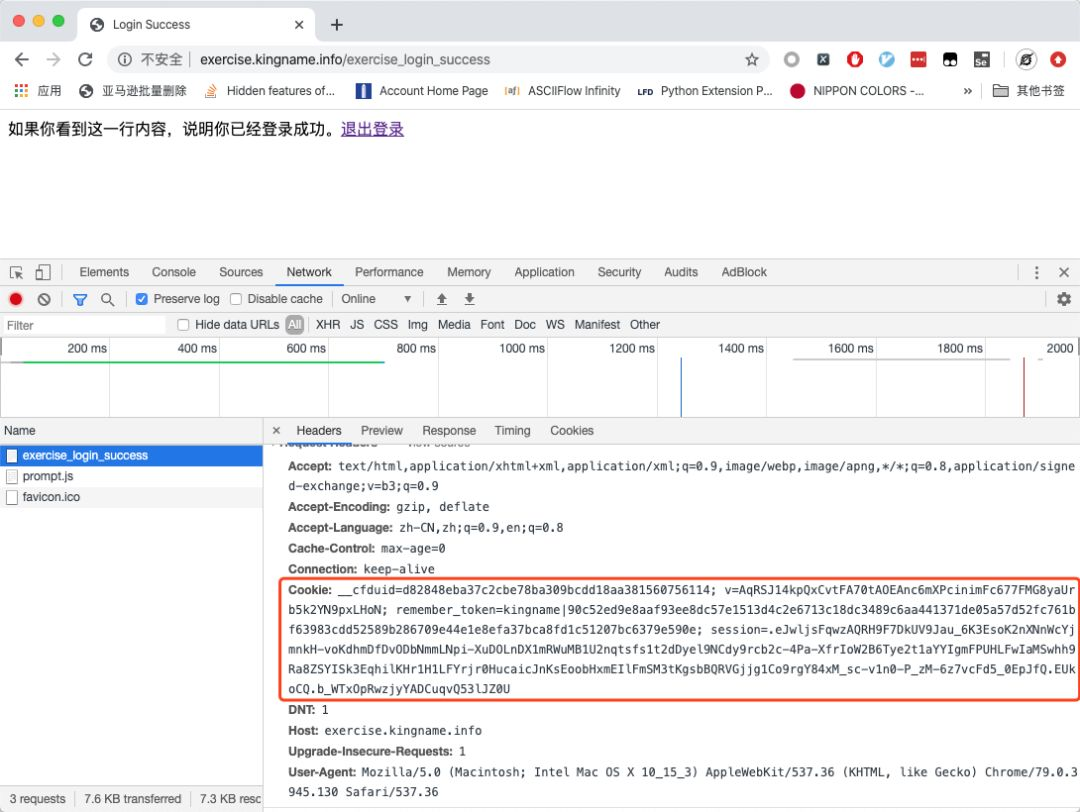
在 Request Headers里面可以看到请求头,在请求头中包含了 Cookie项。
当我们使用 Requests 访问这个网址时,只要请求头中含有这个 Cookie,我们就能直接访问到请求成功的页面,如下图所示:
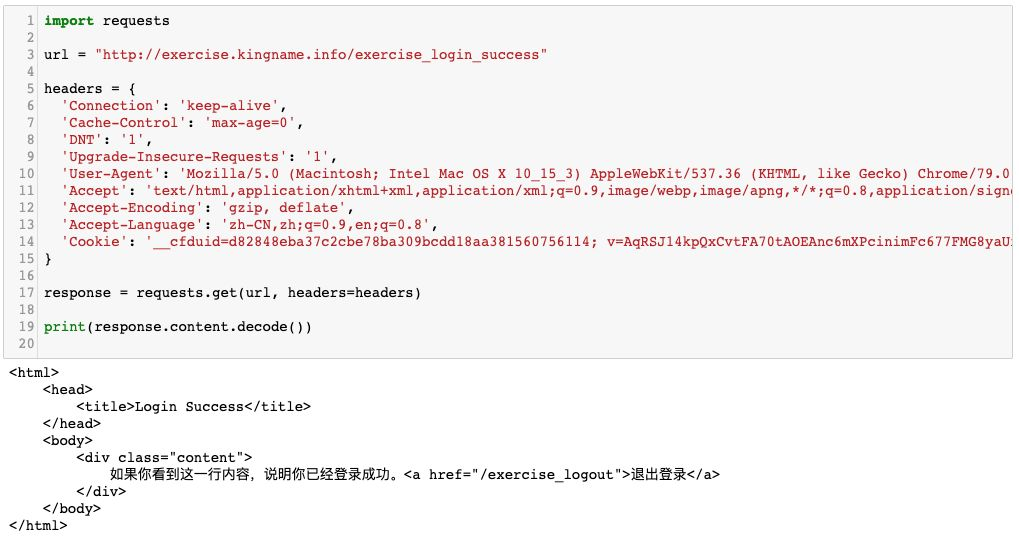
整个过程非常简单并直观。
但如果你想使用 Scrapy 做同样的事情,你会发现登录失败了。如下图所示:
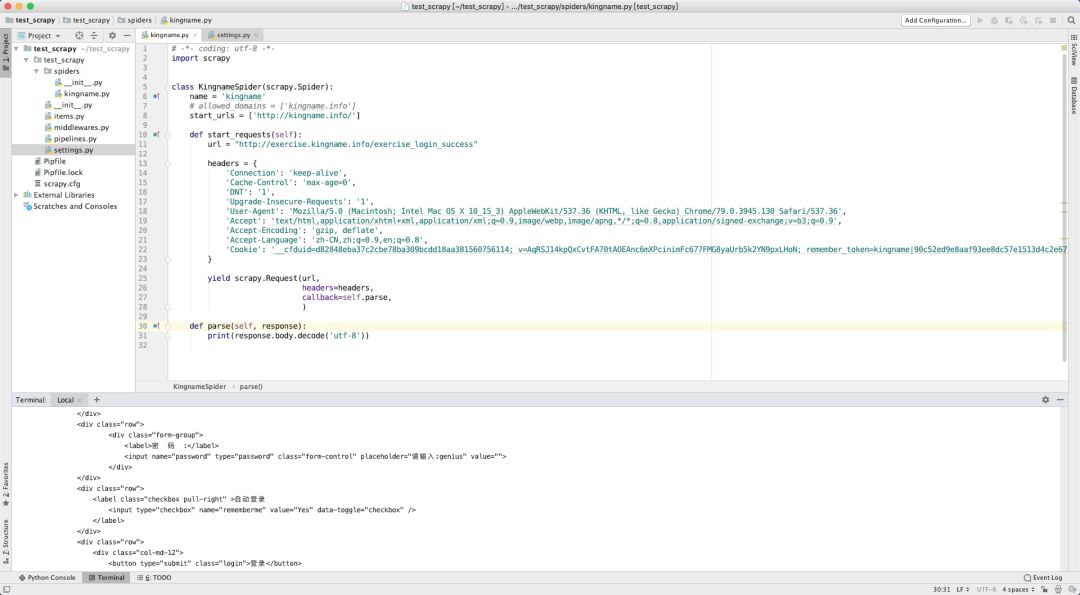
这其中的关键,就在于 Scrapy 发起请求的时候,并不会使用 Headers 中的 Cookie,而是单独有一个cookies参数。
当使用 Request 时,Cookie在 Headers 中是以字符串的形式存在,不同的项目之间使用分号连接,项目内的键值之间使用冒号连接。
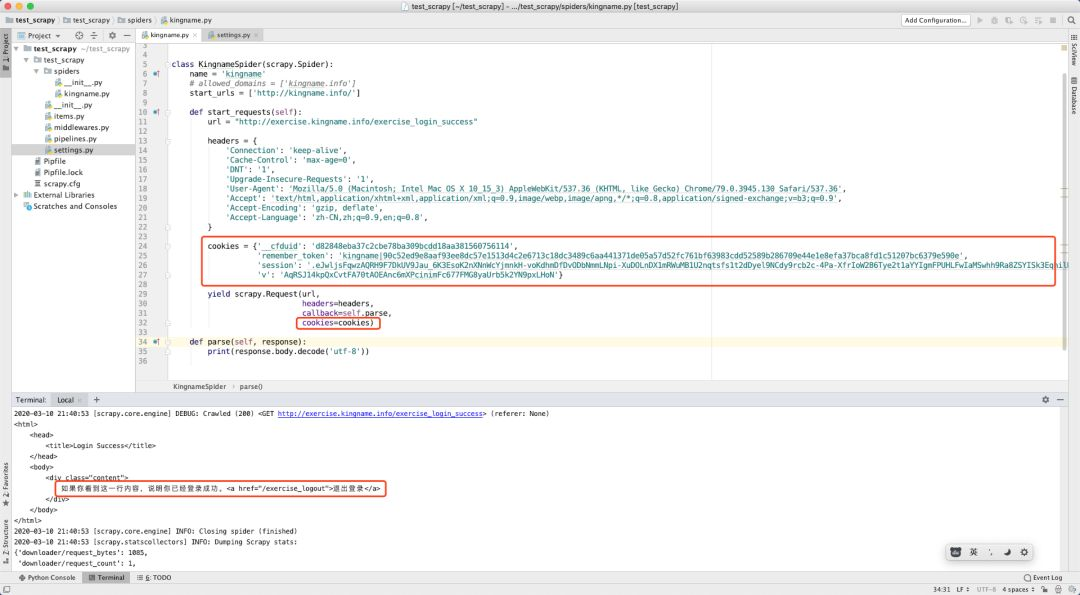
但是在 Scrapy 中,传给cookies参数的值是一个字典,字典的 key 就是各个项目的 key,值就是各个项目的值。
所以我们对 Scrapy 的代码稍作修改,从Headers 中移除 Cookie 项,并改成字典形式,传给 cookies参数,再次请求发现请求成功:
转租:微信公众号:未闻code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号