更友好的格式化数据提取方案
在工作中,我们开发的系统会涉及到大量的日志。同时,我们还有另一套系统会对日志的内容进行监控,从而判断系统是否正常运作。
以 Nginx 的日志为例,这是一条访问日志:
162.158.167.131 - - [11/Aug/2020:06:47:30 +0800] "GET /tags/Tenacity HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://aspiegel.com/petalbot)"
这条日志包含了很多信息,包括:访问者的 IP 地址:162.158.167.131,访问发起的时间:11/Aug/2020:06:47:30 +0800,具体访问的路径:/tags/Tenacity,访问者的 User-Agent 等等。
一般情况下,我们可能需要编写正则表达式来提取这些信息,大家可以现在试一试,针对上面的日志,如果让你来写正则表达式,你会怎么写。
现在,我们有更好的选择,那就是parse这个第三方库。用它能够更加友好又方便地通过简单正则来提取复杂的内容。
我们可以使用pip安装它:
python3 -m pip install parse
安装完成以后,我们用一段简单的代码来进行测试:
>>> import parse >>> log = '162.158.167.131 - - [11/Aug/2020:06:47:30 +0800] "GET /tags/Tenacity HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://aspiegel.com/petalbot)"' >>> pattern = '{ip} - - [{dt:th}] "{method} {path} HTTP/1.1" {code:d} {length:d} "-" "{ua}"' >>> result = parse.search(pattern, log) >>> result['ip'] '162.158.167.131' >>> result['ua'] 'Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://aspiegel.com/petalbot)' >>> print(result.named) {'ip': '162.158.167.131', 'dt': datetime.datetime(2020, 8, 11, 6, 47, 30, tzinfo=<FixedTzOffset +0800 8:00:00>), 'method': 'GET', 'path': '/tags/Tenacity', 'code': 301, 'length': 194, 'ua': 'Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://aspiegel.com/petalbot)'}
运行效果如下图所示: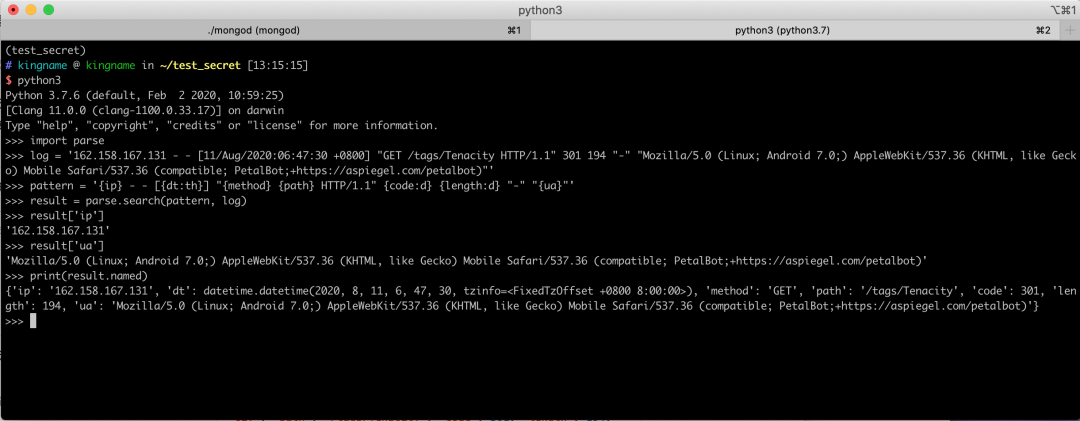
非常轻松地就把需要的字段全部以字典的形式提取了出来。并且日期、数字可以直接提取成对应的形式,免去了事后转换的麻烦。
只要我们自己系统的日志,按照统一的规范来写,那么也可以非常轻易地提取出来。例如我在爬虫多次爬取失败时,写出如下一条日志:
2020-08-11 13:21:41 [scrapy.extensions.logstats] INFO: [多次失败] https://xxx.com/aa/bb\n
那么我可以把提取的规则写为:
pattern = '[多次失败] {url}\n'
运行效果如下图所示:

关于 parse 的更多用法,请看它的 Readme[1]。
参考资料
[1]
Readme: https://github.com/r1chardj0n3s/parse


 浙公网安备 33010602011771号
浙公网安备 33010602011771号