使用lxml解析xml文件
一.简介
XML是由万维网联盟(W3C)创建的标记语言,被设计用来传输和存储数据,XML可以自行定义标签,具有自我描述性,其设计宗旨是传输数据,而非显示数据。Python自带XML模块,方便开发者解析XML数据。XML模块中包含了广泛使用的API接口--------SAX和DOM等。另外,lxml解析库同样支持HTML和XML的解析,而且支持XPath解析方式。总的来说,Python解析XML的常用方法有以下几种:
1、DOM解析,xml.dom.*模块。
2、SAX解析,xml.sax.*模块。
3、ET解析,xml.etree.ElementTree模块。
4、lxml解析并结合XPath提取元素。
XML天生有很好的扩展性;XML有丰富的编码工具,Python解析xml常见的三种方法:DOM、sax及ElementTree。DOM将整个xml读入内存并解析为树,缺点占用内存大且解析慢,优点可以任意遍历树的节点。SAX是流模式,边读边解析,占用内存小,解析快,缺点需要自己处理事件
由于第四种方法是我们在网络爬虫时解析html经常用到的,也是我们较为熟悉的,所以首先尝试用它来解析xml,另外三种方法也将陆续介绍。
二. 使用lxml解析xml文件
1、导入相关标准库
from lxml import etree
2、定义解析器
parser = etree.XMLParser(encoding = "utf-8")
3、使用解析器parser解析XML文件
#传入两个参数,第一个参数是文件名,第二个参数是解析器。 tree = etree.parse(r"douban.xml",parser = parser) #查看解析出的tree的内容 print(etree.tostring(tree,encoding = 'utf-8').decode('utf-8'))
4、结合xpath提取XML文件中的信息
from lxml import etree # 使用lxml解析xml文件 parser = etree.HTMLParser(encoding="utf-8") tree = etree.parse("douban.xml", parser=parser) a = tree.xpath('//loc/text()') print(a)
方法二:直接使用html解析器就能解析xml文件
from lxml import etree with open('douban.xml', 'r',encoding='utf-8') as reader: xmlstr = reader.read() tree = etree.HTML(xmlstr) print(tree.xpath('//loc/text()'))
这种方法容易遇到这样的错误:
ValueError: Unicode strings with encoding declaration are not supported. Please use bytes input or XML fragments without declaration.
原因是lxml 不支持解析带有encoding 声明的字符串,例如 xml中以encoding="UTF-8"开头,需要转换成bytes类型。
我们看看douban.xml文件,真的带有编码声明的:
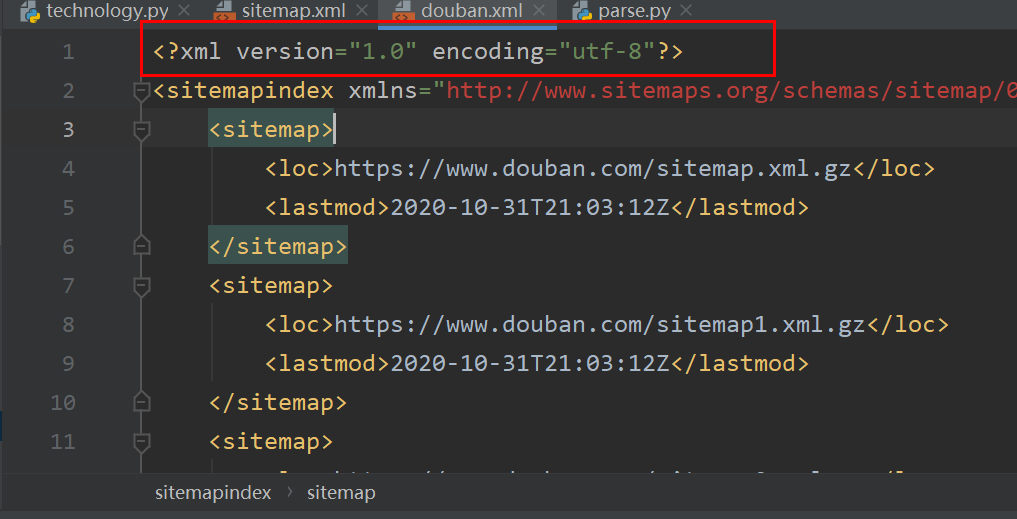
解决方法:
1.把xml文件的首行编码声明去掉就可以了
2.传入构造含数据的不要用字符串,而是二进制内容:
如:
from lxml import etree #以二进制打开文件,传进去bytes类型的数据 with open('douban.xml', 'rb') as reader: xmlstr = reader.read() tree = etree.HTML(xmlstr) print(tree.xpath('//loc/text()'))
三.使用xml.dom.minidom解析xml
import xml.dom.minidom def readXML(path): urls = [] domTree = xml.dom.minidom.parse(path) # 文档根元素 rootNode = domTree.documentElement print(rootNode.nodeName) # 所有loc节点 locs = rootNode.getElementsByTagName("loc") print(locs) for loc in locs: url = loc.childNodes[0].data urls.append(url) return urls path = "./sitemap.xml" readXML(path)
四.使用xml包解析xml文件的几个扩展
测试xml数据包
<?xml version="1.0" encoding="UTF-8"?> <root> <common> <building_id>xxxxxx</building_id> <gateway_id>01</gateway_id> <type>report</type> </common> <data operation="report"> <sequence>25</sequence> <parser>yes</parser> <time>20210115180000</time> <meter id="1" name="000000000001" conn="conn"> <function id="1" name="000000000001-1090" coding="01A10" error="192" sample_time="20210115175909">数据1</function> <function id="2" name="000000000001-1200" coding="XXX" error="XXX" sample_time="YYYYMMDDHHMMSS">数据2</function> </meter> <meter id="2" name="000000000002" conn="conn"> <function id="1" name="000000000002-1090" coding="01A10" error="192" sample_time="20210115175900">数据1</function> <function id="2" name="000000000002-1200" coding="XXX" error="XXX" sample_time="YYYYMMDDHHMMSS">数据2</function> </meter> </data> </root>
扩展1:已有xml包+指定节点解析
#导入解析模块 import xml.etree.ElementTree as ET #加载xml文件 root=ET.parse("test.xml") # animal_node=root.getiterator("meter") #过时 #获取指定节点 meter_node=root.getroot().iter(tag="meter") def iter_records(meter_node): for node in meter_node: # 保存字典 temp_dict = {} # animal_node_child = node.getchildren()[0] #方法过时 for i in range(len(node)): #方法一: meter_node_child=[i for i in node][i] #方法二 # meter_node_child=list(node)[i] # print(meter_node_child) print(meter_node_child.tag+"\n"+"name:"+meter_node_child.attrib["name"]+":"+meter_node_child.text) temp_dict[meter_node_child.attrib['name']] = meter_node_child.text # 生成值 yield temp_dict print(list(iter_records(meter_node)))
扩展2:已有xml包+所有节点解析
import xml.etree.ElementTree as ET # # #加载xml文件 root=ET.parse("test.xml") # #获取指定节点 meter_node=root.findall("data") for meter in meter_node: # 保存字典 lst=[{i.tag: i.text} for i in meter[0:3]] for node in meter[3:]: meter_node_child = list(node) k=[{meter_node_child[i].attrib["name"]:meter_node_child[i].text} for i in range(len(node))][0] lst.append(k) print(lst)
扩展3:xml包创建+格式化输出
import xml.etree.ElementTree as ET #格式化数据包 def write_xml(): # 创建elementtree对象,写入文件 root=xml_encode() tree = ET.ElementTree(root) tree.write("new1.xml") with open(r'new1.xml', 'r', encoding="utf-8") as file: with open(r'new2.xml', 'w+', encoding="utf-8") as xml_file: # 用open()将XML文件中的内容读取为字符串再转成UTF-8 xmlstr = file.read().encode('utf-8') import xml.dom.minidom xml = xml.dom.minidom.parseString(xmlstr) xml_pretty_str = xml.toprettyxml() print(xml_pretty_str) xml_file.write(xml_pretty_str) return xml_pretty_str #创建xml def xml_encode(): # 创建根节点 root=ET.Element("root",encoding="utf-8") #创建子节点sub1,并为其添加属性 sub1=ET.SubElement(root,"data") sub1.attrib={"operation":"report"} #创建子节点sub2,并为其添加数据 sub2=ET.SubElement(sub1,"meter") sub2.attrib={"name":"000000000001"} #创建子节点sub3,并为其添加数据 sub3=ET.SubElement(sub2,"function") sub3.attrib={"name":"000000000001-1090"} sub3.text="数据1" return root write_xml()
扩展4:外部数据+xml创建
import pandas as pd def write_xml(data): # 以写入打开文件 with open("new2.xml", 'w') as xmlFile: # 写入头部 xmlFile.write('<?xml version="1.0" encoding="UTF-8"?>\n') xmlFile.write('<root>\n') body=xml_encode(data) # 写数据 xmlFile.write(body) # 写尾部 xmlFile.write('\n</root>') def xml_encode(data): # 标记data节点开始标签 xmlItem = ['<data operation="report">'] # 列表追加,回车成多行 for i in data.index: coding = data.iloc[i][0] value = data.iloc[i][1] #输入替换的模板:给行中每个字段加固定xml格式 str_xml = """<meter name="{0}"><function name="{0}-1090">{1}</function></meter>""".format(coding,value) xmlItem.append(str_xml) # 标记data节点结束标签 xmlItem.append('</data>') # 返回字符串 xml_str = '\n'.join(xmlItem) # list 更新成str print(xml_str) return xml_str if __name__ == '__main__': #测试数据 data=pd.DataFrame({"name":["00001","00002"],"value":[20,30]}) #生成数据包 write_xml(data)
扩展5:外部数据+xml入库
首先在数据库建立测试表xml_data,三个字段ID:记录id、xmlDatetime:插入时间、xmlData:xml数据包内容
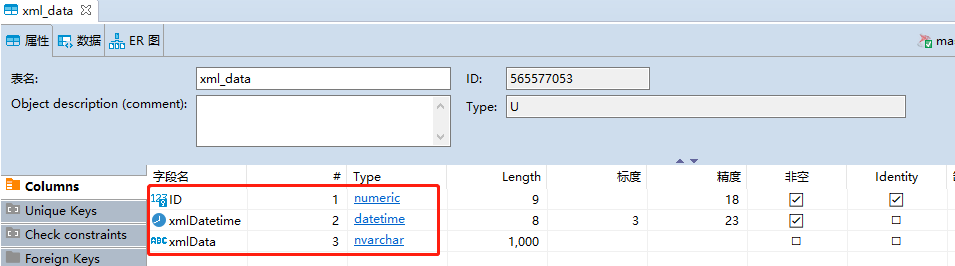
将xml插入数据库,其中数据库连接方法get_conn,见推文:
跨库数据备份还原、迁移工具
from datetime import datetime from tools import get_conn #数据导入 def xml_sync_to_sqlserver(): """ xml数据同步到sqlserver数据库里面 """ xmlDatetime = datetime.now() conn = None try: conn = get_conn('LOCAL') with conn: # 数据文件导入 with conn.cursor() as cur: with open(f'new2.xml', mode='r', encoding='utf-8') as file: xmlData = file.read().rstrip() sql = """insert into xml_data(xmlDatetime,xmlData) values (%s,%s)""" print("插入成功") cur.execute(sql,(xmlDatetime,xmlData)) conn.commit() finally: if conn: conn.close() end =datetime.now() s = (end - xmlDatetime).total_seconds() print('数据导入: %s, 耗时: %s 秒' % (xmlDatetime, s))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号