mongo聚合查询
一.聚合查询就是流式的对数据处理,分成各个阶段
1.当聚合查询只有一个阶段就和find没有差别,如:
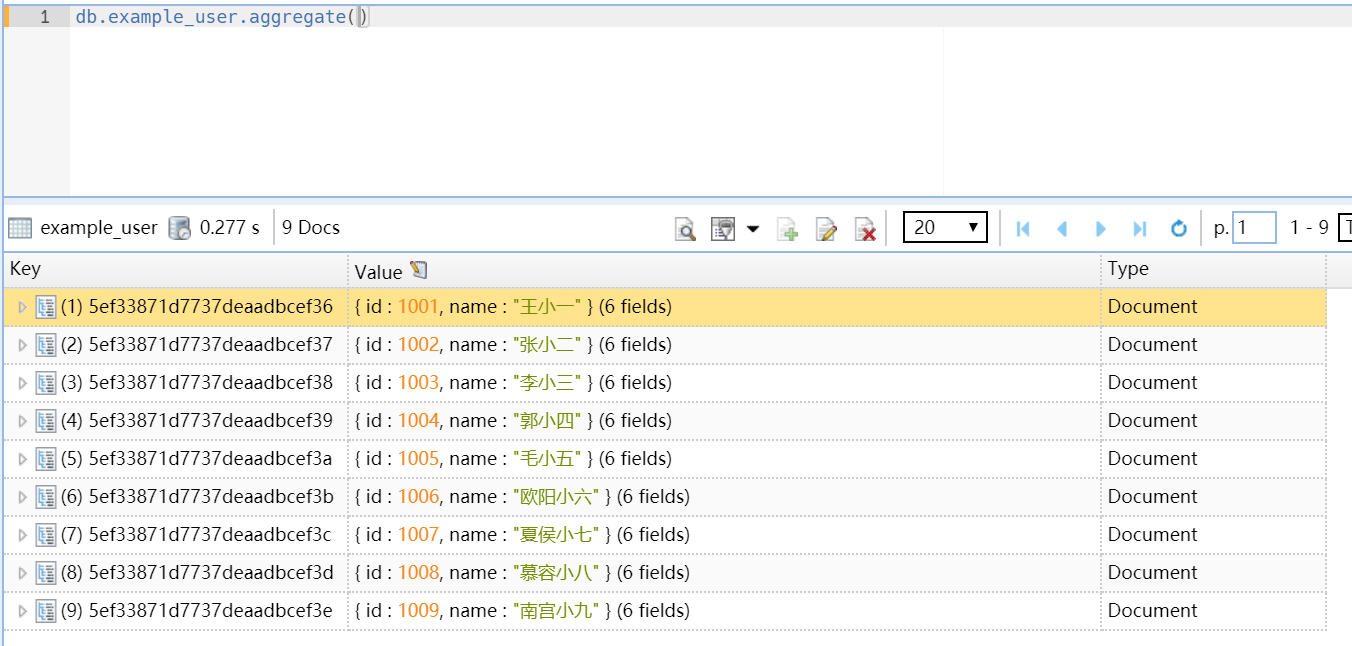
如果聚合有至少一个阶段, 那么每一个阶段都是一个字典。 不同的阶段负责不同的事情, 每一个阶段有一个关键字。
有专门负责筛选数据的阶段“$match”, 有专门负责字段相关的阶段“$project”, 有专门负责数据分组的阶段“$group”等。
二.筛选数据阶段 关键字 $match
1.示例
db.getCollection("2020062401").aggregate([{$match:{和find完全一样的表达式}}])
如:
db.example_user.aggregate([{$match: {"age":{$lt:18}}}])
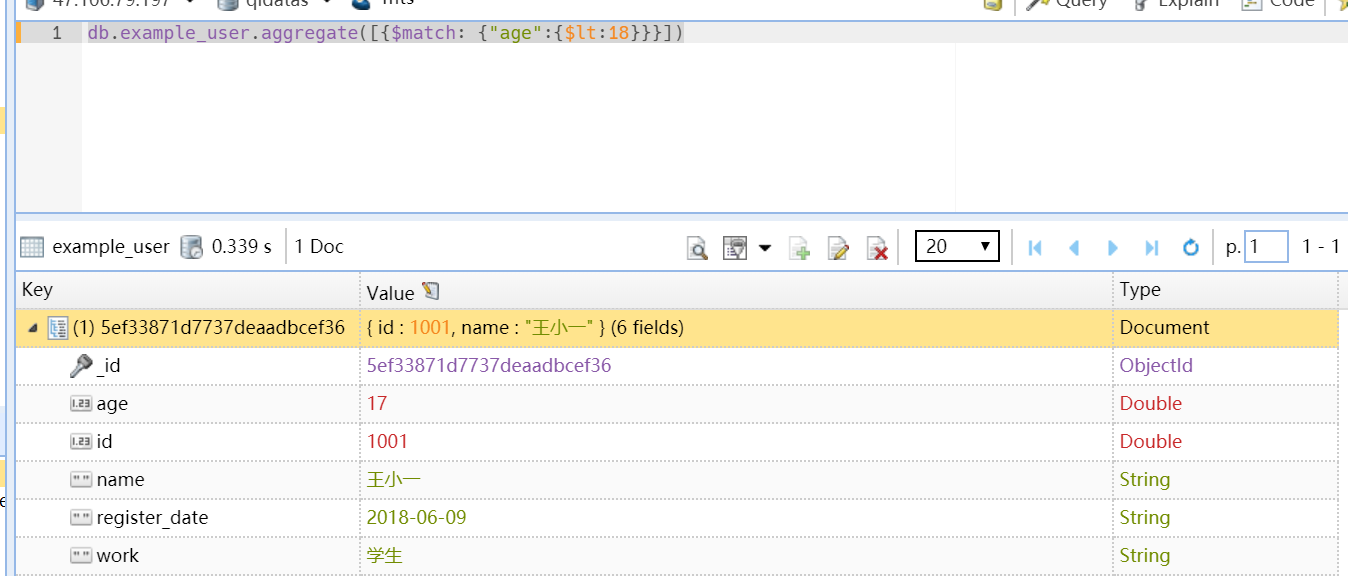
看上面的语句是不是和find一样?
db.example_user.find({"age":{$lt:18}})
聚合查询操作中的, “{'$match': {和find完全一样的查询表达式}}”,“$match”作为一个字典的Key, 字典的Value和“find()”第1个参数完全相同。 “find()”第1个参数能怎么写, 这里就能怎么写。
三.筛选和修改字段 关键字 $project
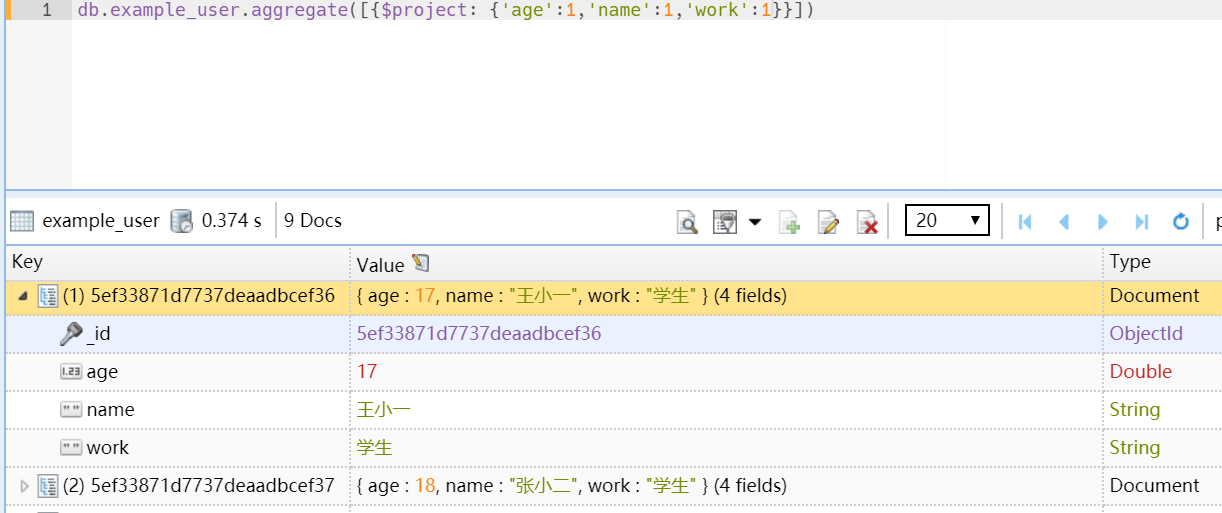
1.作用1:过滤字段,只返回部分字段
db.example_user.aggregate([{$project: {字段过滤语句}}])
如:
db.example_user.aggregate([{$project: {'age':1,'name':1,'work':1}}])
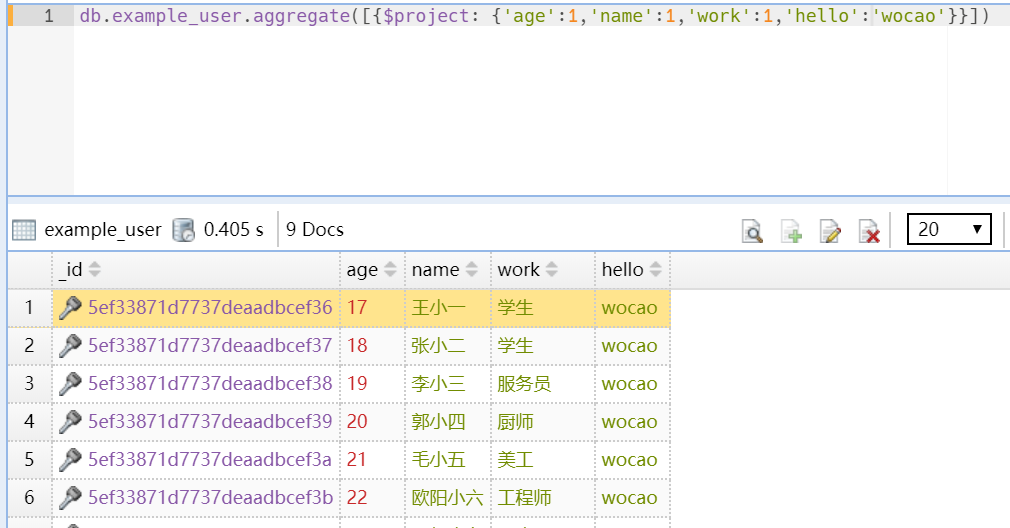
2.作用2:在返回结果添加新字段(字符串)
如:(注意,hello字段是原来不存在的)
db.example_user.aggregate([{$project: {'age':1,'name':1,'work':1,'hello':'wocao'}}])
3
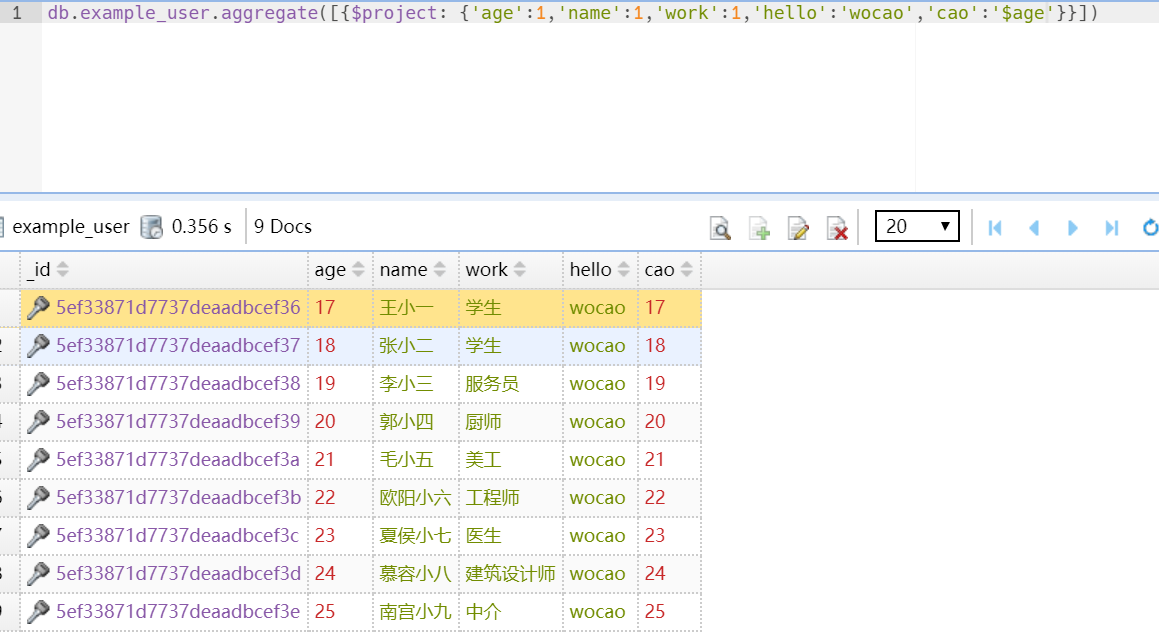
3.作用3.:在返回结果复制现有字段
如:
db.example_user.aggregate([{$project: {'age':1,'name':1,'work':1,'hello':'wocao','cao':'$age'}}])
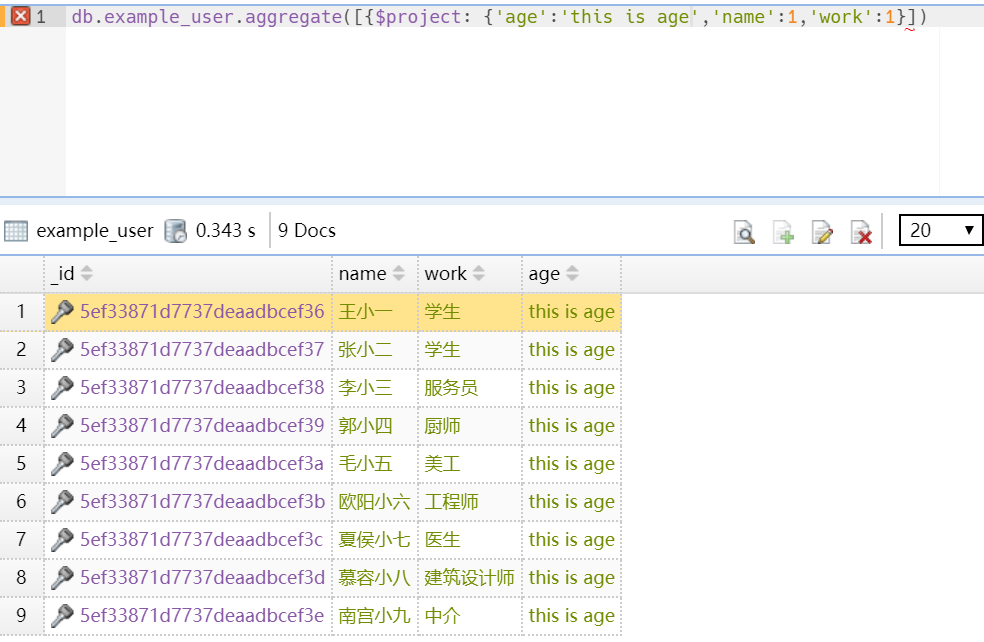
4..作用4:在返回结果修改现有字段
如:
db.example_user.aggregate([{$project: {'age':'this is age','name':1,'work':1}])
5..作用5:抽取嵌套字段
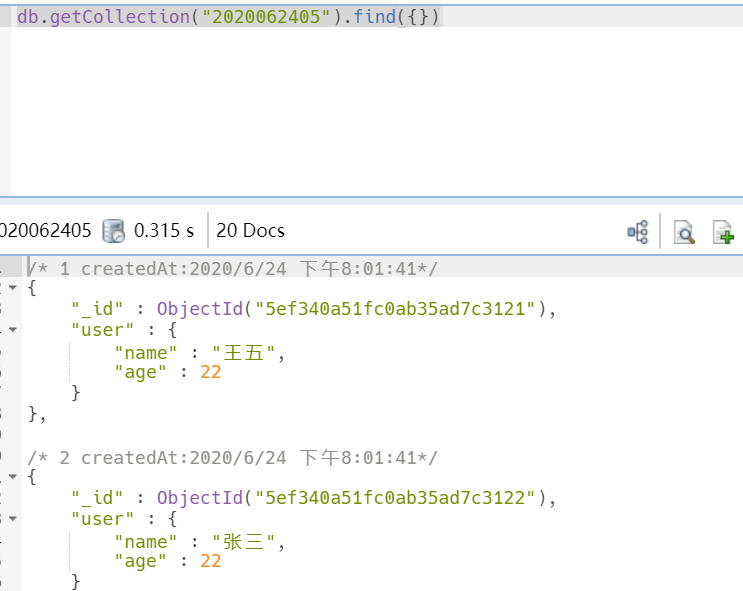
先看一下用find查询嵌套字典的前后对比
db.getCollection("2020062405").find({})
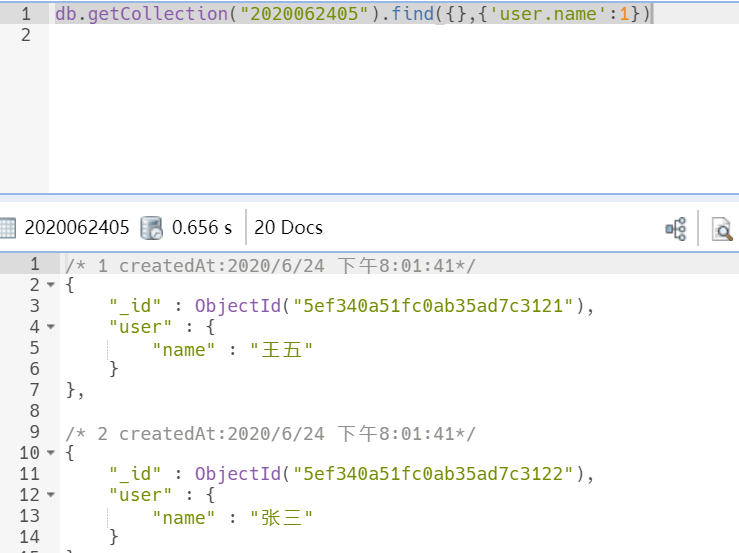
db.getCollection("2020062405").find({},{'user.name':1})
再看一下使用$project
db.getCollection("2020062405").aggregate([{$project: {'name':"$user.name",'age':'$user.age'}}])
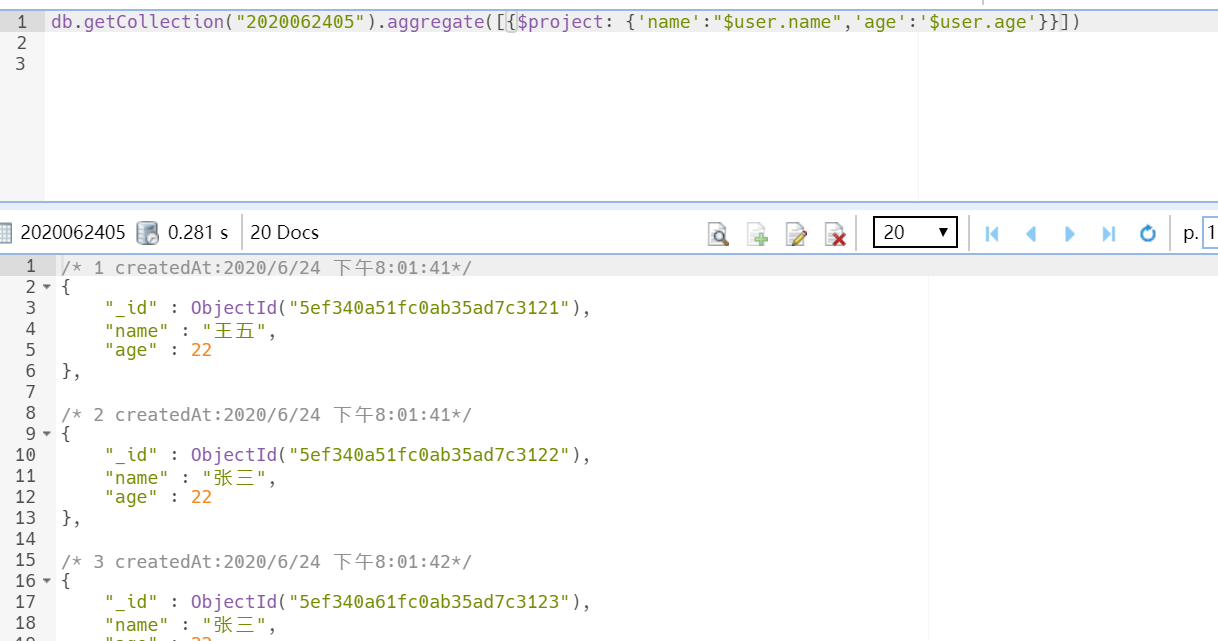
看到差别了把
6.特殊字段的处理
如果想添加一个字段,但是这个字段的值就是数字“1”会怎么样?
如果添加一个字段,这个字段的值就是一个普通的字符串,但不巧正好以“$”开头,又会怎么样呢?
db.getCollection('example_data_1').aggregate([ {'$match': {'age': {'$gt': 28}}}, {'$project': {'_id': 0, 'id': 1, 'hello': '$normalstring', 'abcd': 1}} ])
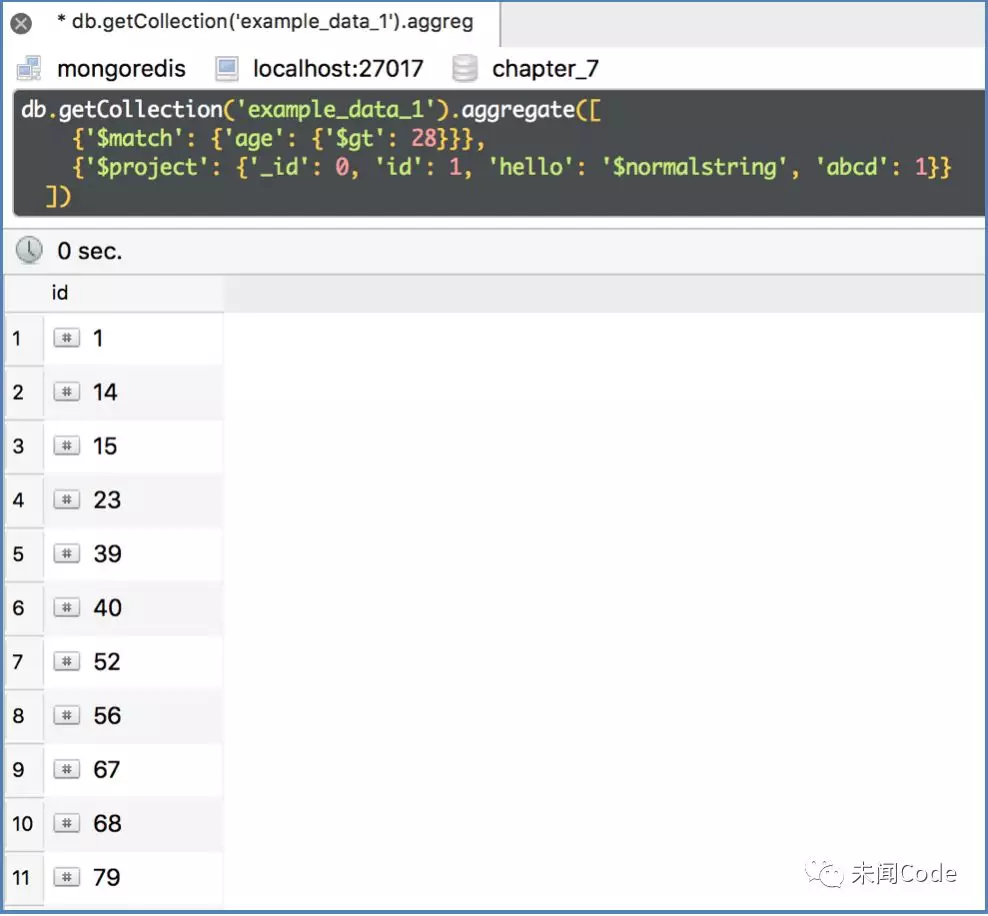
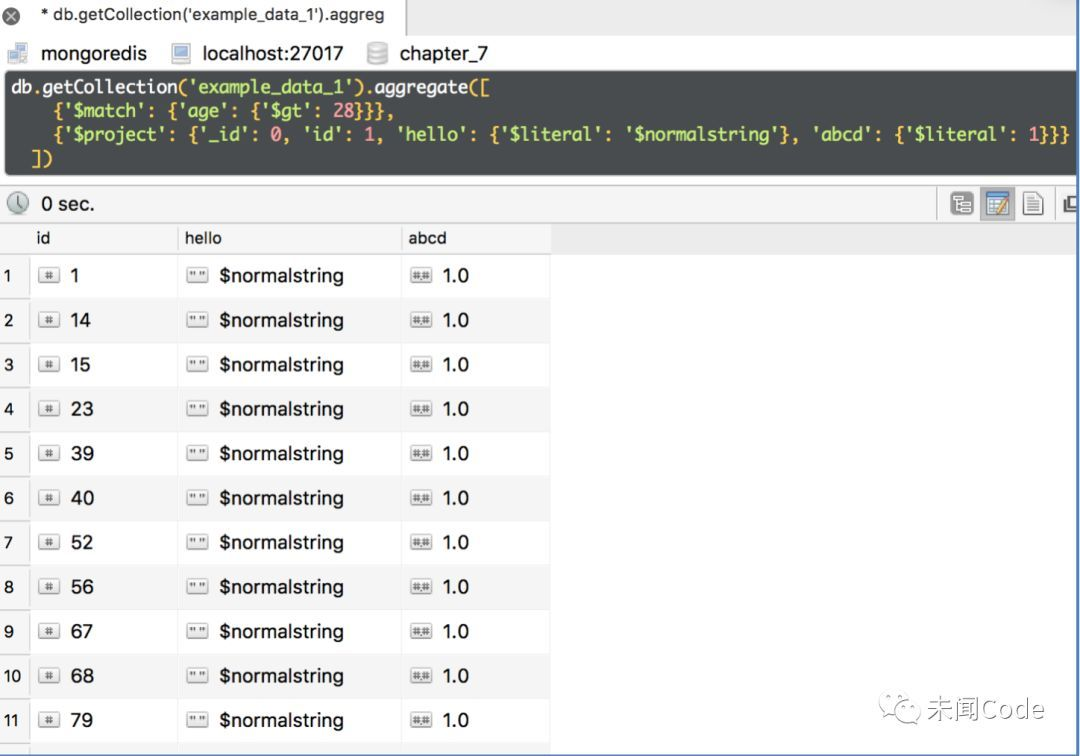
由于特殊字段的值和“$project”的自身语法冲突了,导致所有以“$”开头的普通字符串和数字都不能添加。要解决这个问题,就需要使用另一个关键字“$literal”,代码如下
db.getCollection('example_data_1').aggregate([ {'$match': {'age': {'$gt': 28}}}, {'$project': {'_id': 0, 'id': 1, 'hello': {'$literal': '$normalstring'}, 'abcd': {'$literal': 1}}} ])
摘自:《左手redis,右手mongodb》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号