实现函数调用结果的 LRU 缓存
在工程项目中,可能有一些函数调用耗时很长,但是又需要反复多次调用,并且每次调用时,相同的参数得到的结果都是相同的。在这种情况下,我们可能会使用变量或者列表来存放,例如:
resp_1 = get_resp(param=1) resp_2 = get_resp(param=2) resp_3 = get_resp(param=3)
但是,如果返回的结果占用内存比较大,我们每次调用都把结果存在内存里面,就会消耗大量内存。
于是,我们可以使用 LRU 算法:最近最常使用的参数生成的结果,我们存下来,下次遇到相同的参数时直接返回结果。而不常出现的参数,等到需要的时候再计算。计算完成后,也先存下来。但是如果缓存空间不够了,不常使用的会先删除。
LRU 的算法自己手动实现起来比较麻烦,但好在 Python 的 functions模块已经提供了现成的 lru_cache装饰器供我们使用。
首先我们写一个不带 lru 算法的程序:
import time import datetime def say(name): print(f'你好:{name}') now = datetime.datetime.now() return now now = say('kingname') print(f'现在时间为:{now}') time.sleep(10) now = say('产品经理') print(f'现在时间为:{now}') time.sleep(10) now = say('kingname') print(f'现在时间为:{now}')
运行效果如下图所示:
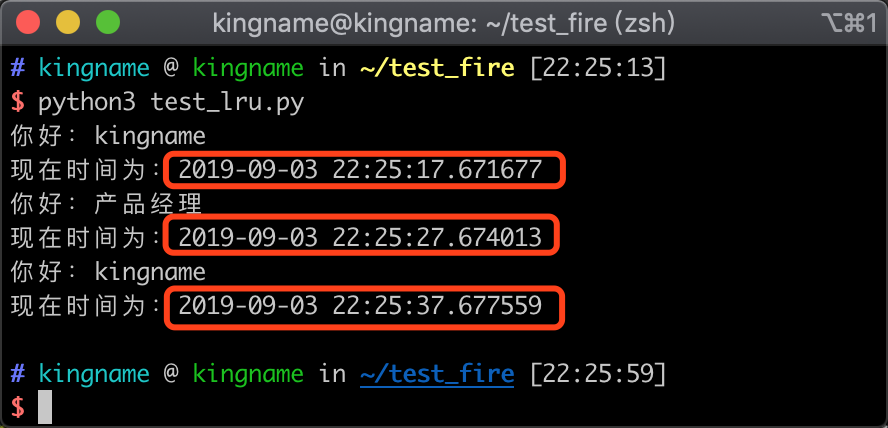
从运行结果可以看到,调用函数三次,第一次和第三次传入的参数都是 kingname,第二次传入的参数为 产品经理, 你好:kingname打印了两次, 你会:产品经理打印了一次。第二次打印的时间比第一次多了10秒,第三次打印的时间比第二次多了10秒。
现在我们把 LRU 缓存加上。
import time import datetime from functools import lru_cache @lru_cache(maxsize=32) def say(name): print(f'你好:{name}') now = datetime.datetime.now() return now now = say('kingname') print(f'现在时间为:{now}') time.sleep(10) now = say('产品经理') print(f'现在时间为:{now}') time.sleep(10) now = say('kingname') print(f'现在时间为:{now}')
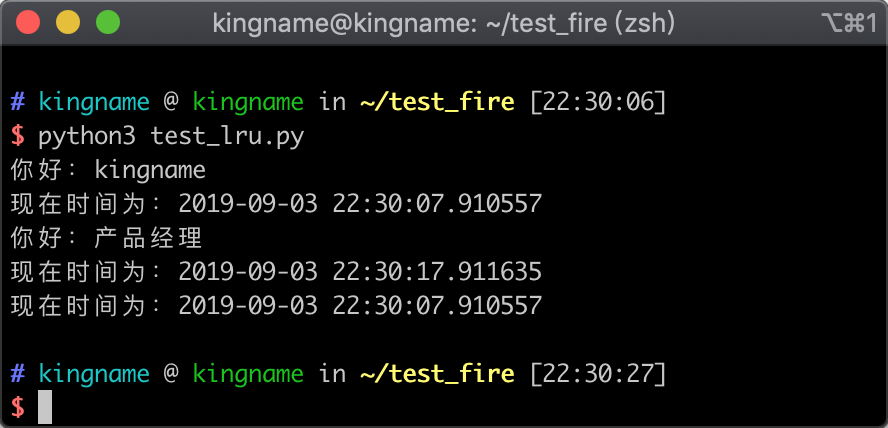
从打印出来的结果可以看出,第三次调用 say函数的时候,传入的也是 kingname,但是函数根本没有运行,所以没有打印第二个 你好:kingname。并且第三个时间与第一个时间完全相同。说明第三次调用函数的时候,直接读取的缓存。
lru_cache(maxsize=128,typed=False)接收两个参数,第一个参数 maxsize表示最多缓存多少个结果,这个数字建议设置为2的幂。超出这个结果就会启用 LRU 算法删除不常用的数据。第二个参数 typed表示是否检查参数类型,默认为 False,如果设置为 True,那么参数 3和 3.0会被当做不同的数据处理。
由于 lru_cache底层是基于字典来实现的缓存,所以参数都必须是 hashable 的,否则会导致报错。
分享自:公众号:未闻code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号