mongo的聚合操作

对图7-1所示的数据集exampledata1,使用聚合操作实现以下功能:
(1)不返回_id字段,只返回age和sex字段。
(2)所有age大于28的记录,只返回age和sex。
(3)在$match返回的字段中,添加一个新的字段“hello”,值为“world”。
(4)在$match返回的字段中,添加一个新的字段“hello”,值复制age的值。
(5)在$match返回的字段中,把age的值修改为一个固定字符串。
(6)把user.name和user.user_id变成普通的字段并返回。
(7)在返回的数据中,添加一个字段“hello”,值为“$normalstring”,再添加一个字段“abcd”,值为1。
“$match”可以筛选出需要的记录,那么如果想只返回部分字段,又应该怎么做呢?这时就需要使用关键字“$project”。
返回部分字段
首先用“$project”来实现一个已经有的功能——只返回部分字段。格式如下:
collection.aggregate([{'$project': {字段过滤语句}}])
这里的字段过滤语句与“find()”第2个参数完全相同,也是一个字典。字段名为Key,Value为1或者0(需要的字段Value为1,不需要的字段Value为0)。
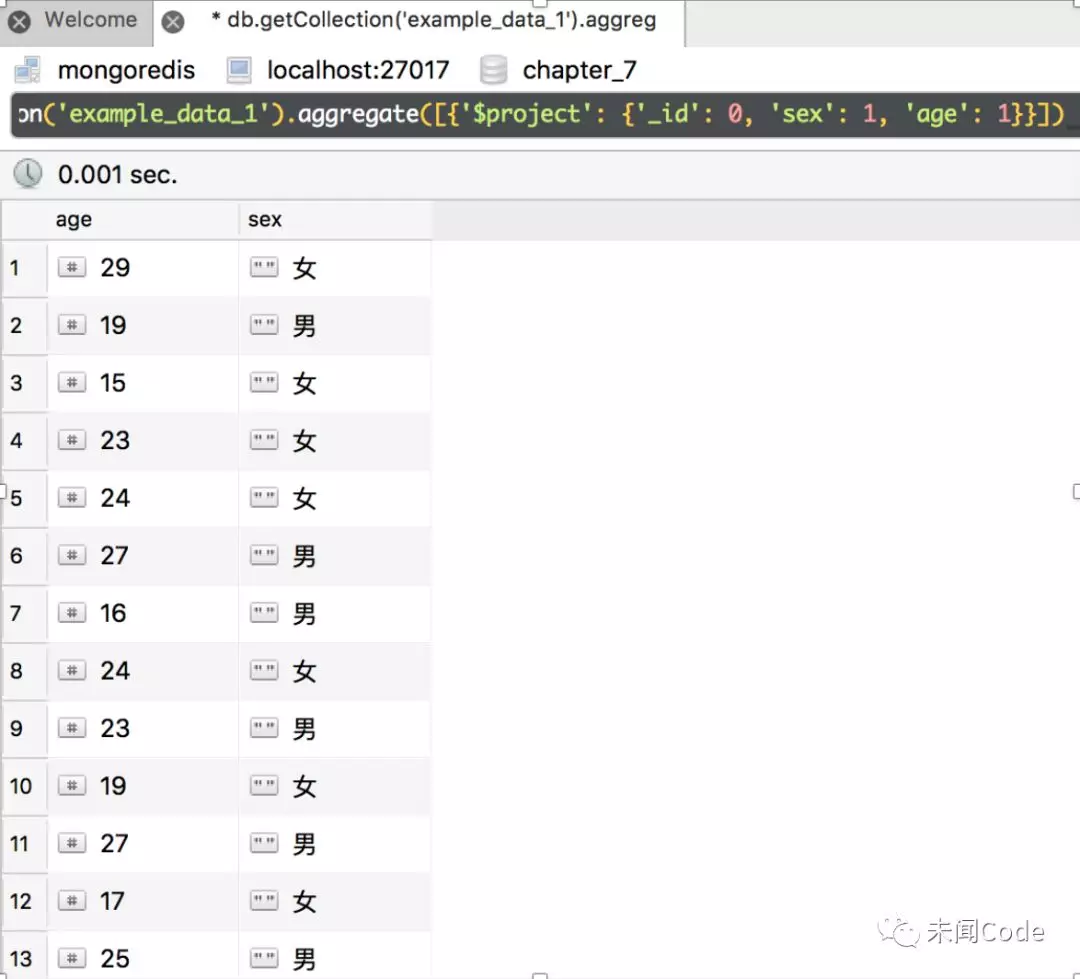
例如,对于图7-1所示的数据集,不返回“_id”字段,只返回age和sex字段,则聚合语句如下:
db.getCollection('example_data_1').aggregate([ {'$project': {'_id': 0, 'sex': 1, 'age': 1}} ])
查询结果如图7-22所示。
结合“$match”实现“先筛选记录,再过滤字段”。例如,选择所有age大于28的记录,只返回age和sex,则聚合语句写为:
db.getCollection('example_data_1').aggregate([ {'$match': {'age': {'$gt': 28}}}, {'$project': {'_id': 0, 'sex': 1, 'age': 1}} ])
查询结果如图7-23所示。

到目前为止,使用“$match”加上“$project”,多敲了几十次键盘,终于实现了“find()”的功能。使用聚合操作复杂又繁琐,好处究竟是什么?
添加新字段
添加固定文本
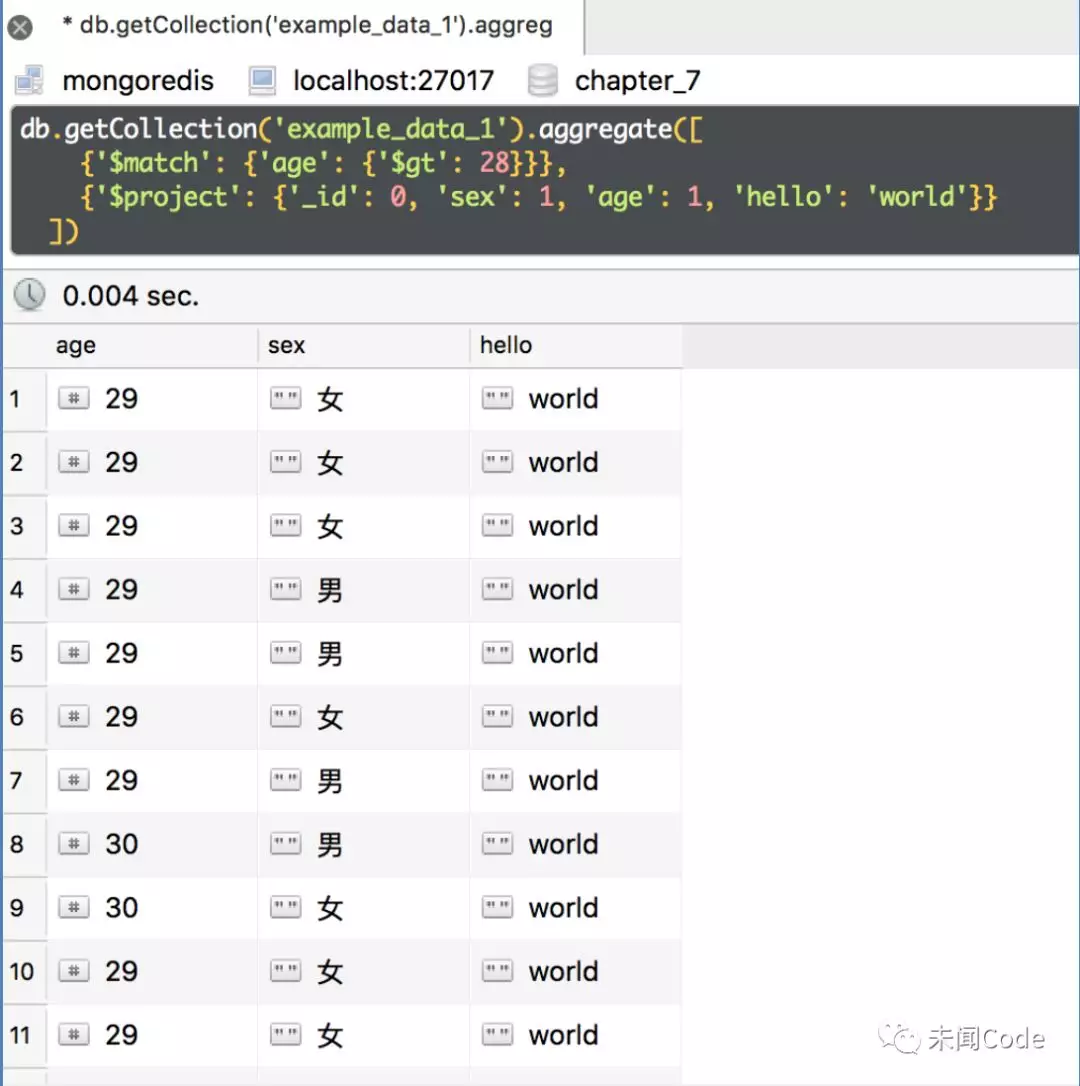
在“$project”的Value字典中添加一个不存在的字段,看看效果会怎么样。例如:
db.getCollection('example_data_1').aggregate([ {'$match': {'age': {'$gt': 28}}}, {'$project': {'_id': 0, 'sex': 1, 'age': 1, 'hello': 'world'}} ])
注意这里的字段名“hello”,exampledata1数据集是没有这个字段的,而且它的值也不是“0”或者“1”,而是一个字符串。
查询结果如图7-24所示。在查询的结果中直接增加了一个新的字段。
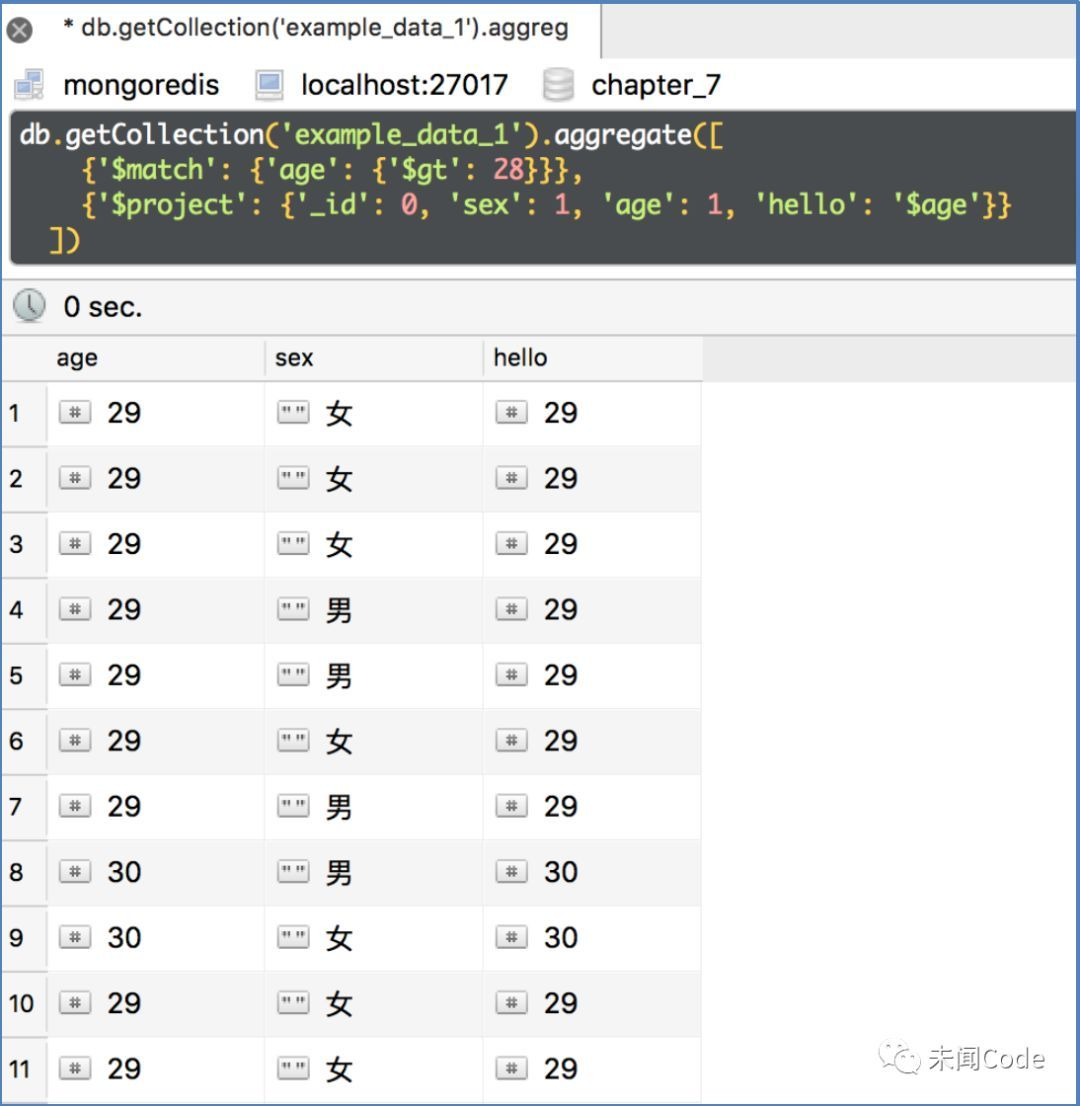
复制现有字段。
现在把上面代码中的“world”修改为“$age”,变为:
db.getCollection('example_data_1').aggregate([ {'$match': {'age': {'$gt': 28}}}, {'$project': {'_id': 0, 'sex': 1, 'age': 1, 'hello': '$age'}} ])
查询结果如图7-25所示。
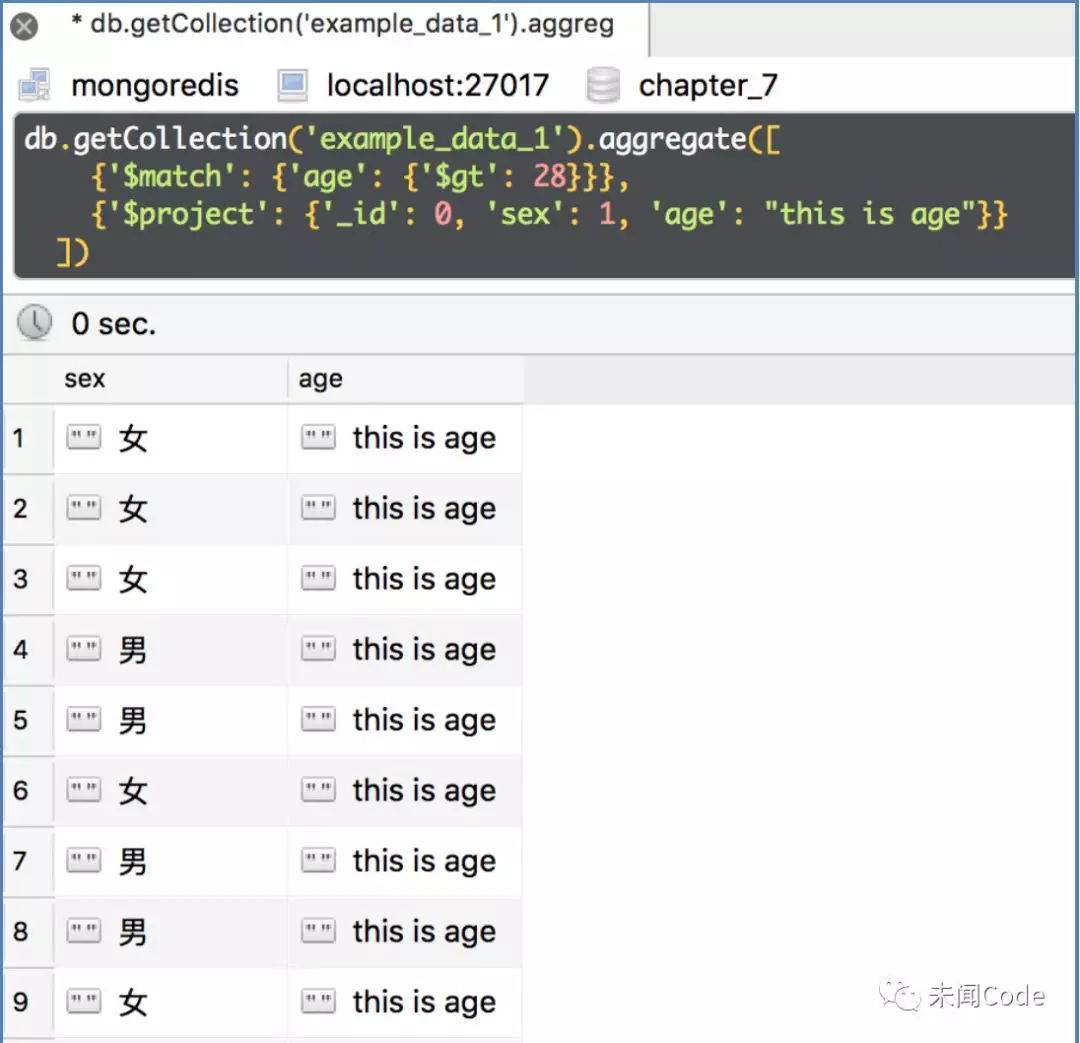
修改现有字段的数据
接下来,把原有的age的值“1”改为其他数据,代码变为:
db.getCollection('example_data_1').aggregate([ {'$match': {'age': {'$gt': 28}}}, {'$project': {'_id': 0, 'sex': 1, 'age': "this is age"}} ])
查询结果如图7-26所示。
从图7-25和图7-26可以看出,在“$project”中,如果一个字段的值不是“0”或“1”,而是一个普通的字符串,那么最后的结果就是直接输出这个普通字符串,无论数据集中原本是否有这个字段。
从图7-26可以看出,如果一个字段后面的值是“$+一个已有字段的名字”(例如“$age”),那么这个字段就会把“$”标记的字段的内容逐行复制过来。这个复制功能初看起来似乎没有什么用,原样复制能干什么?那么现在来看看exampledata2的嵌套字段。
抽取嵌套字段
对于如下图所示的数据集 example_data_2:
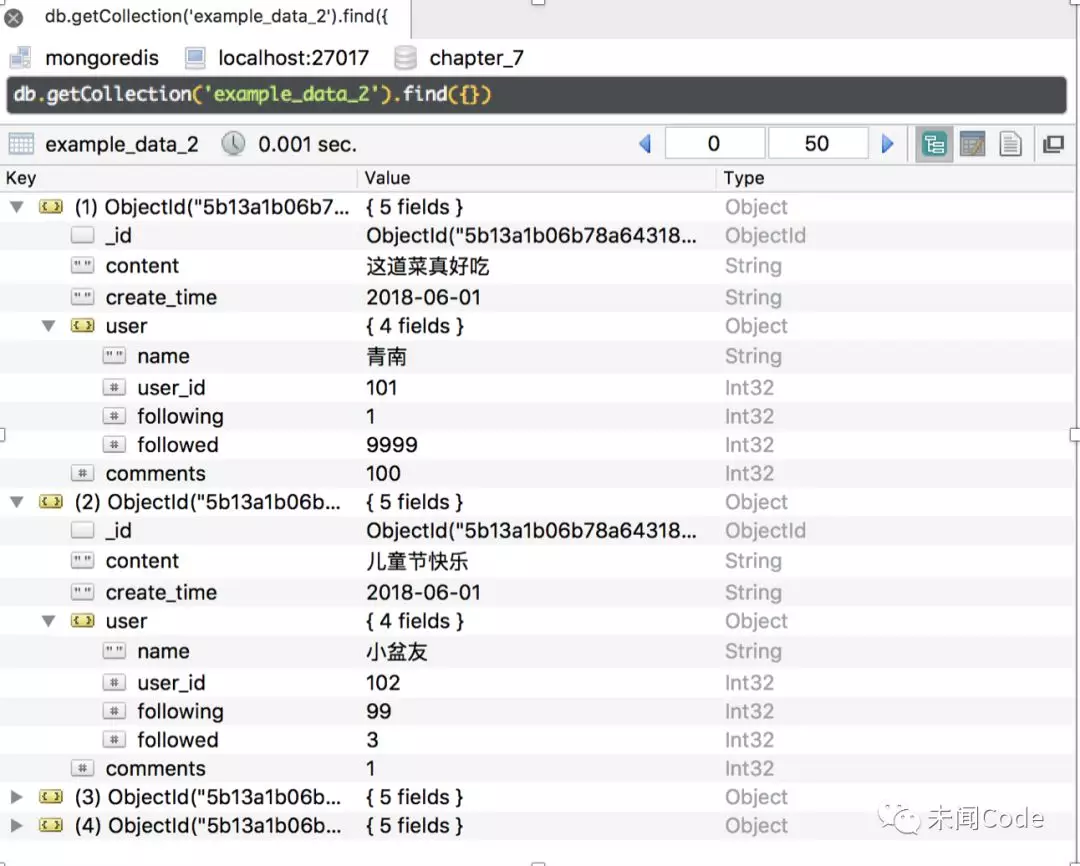
如果直接使用find(),想返回“user_id”和“name”,则查询语句为:
db.getCollection('example_data_2').find({}, {'user.name': 1, 'user.user_id': 1})
查询结果如图7-27所示。
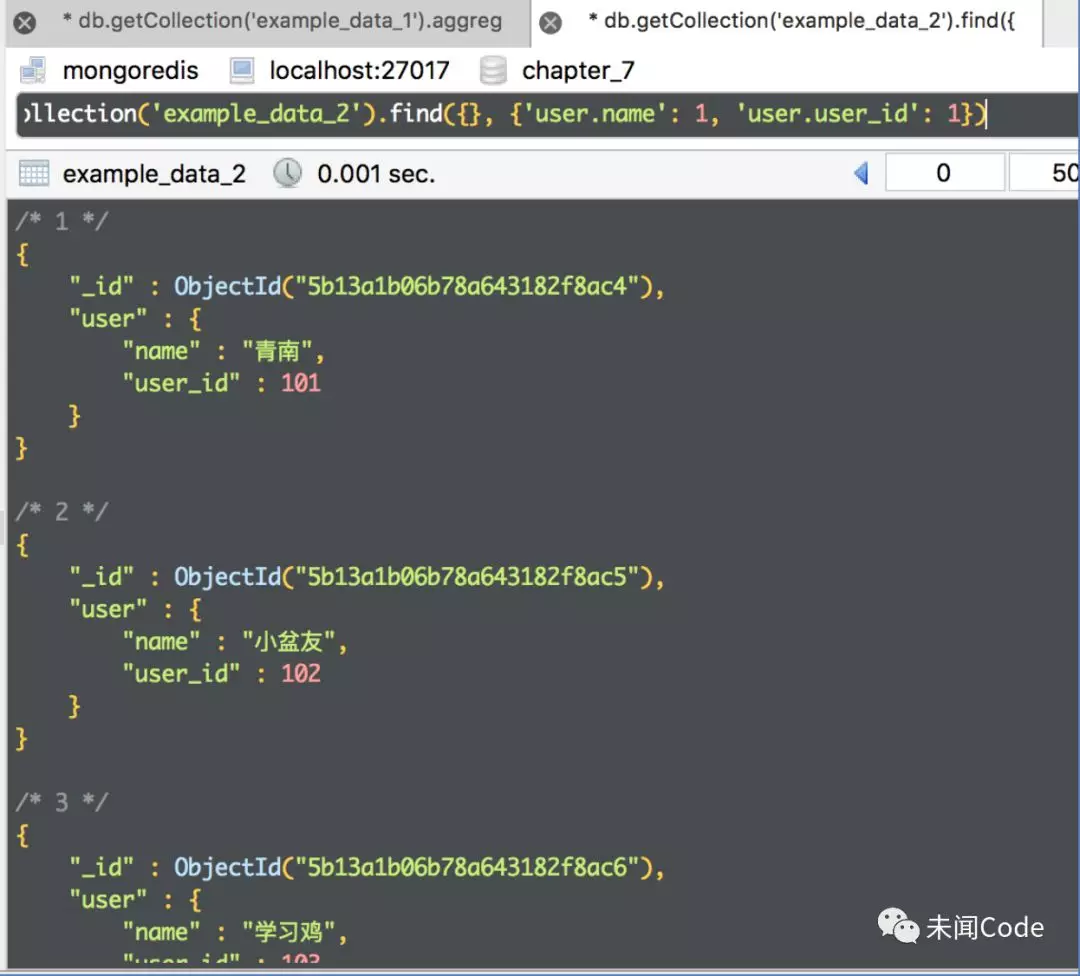
返回的结果仍然是嵌套字段,这样处理起来非常不方便。而如果使用“$project”,则可以把嵌套字段中的内容“抽取”出来,变成普通字段,具体代码如下:
db.getCollection('example_data_2').aggregate([ {'$project': {'name': '$user.name', 'user_id': '$user.user_id'}} ])
查询结果如图7-28所示。
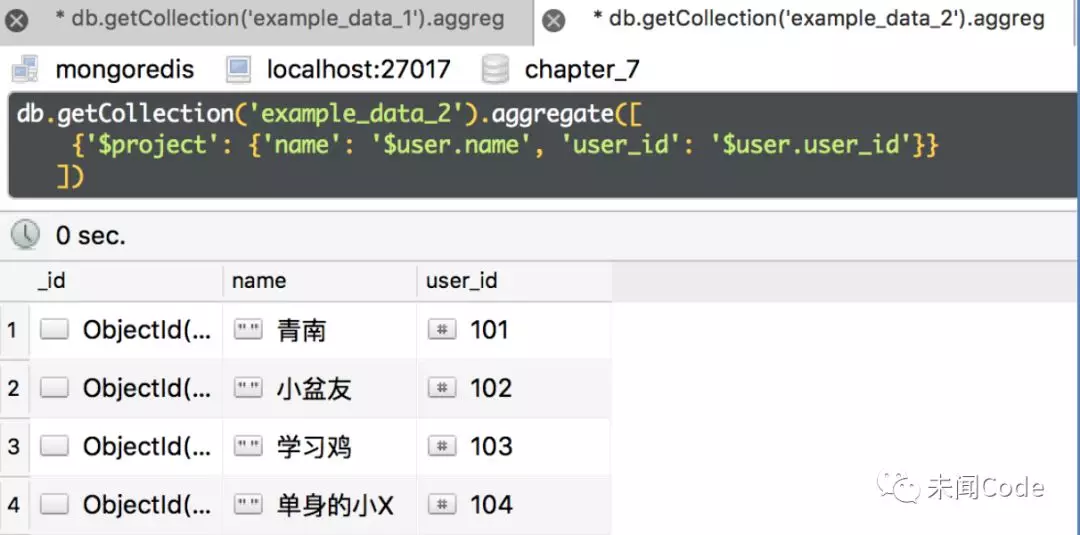
普通字段处理起来显然是要比嵌套字段方便不少,这就是“复制字段”的妙用。
处理字段特殊值
看到这里,可能有读者要问:
如果想添加一个字段,但是这个字段的值就是数字“1”会怎么样?
如果添加一个字段,这个字段的值就是一个普通的字符串,但不巧正好以“$”开头,又会怎么样呢?
下面这段代码是图7-1所示的数据集的查询结果。
db.getCollection('example_data_1').aggregate([ {'$match': {'age': {'$gt': 28}}}, {'$project': {'_id': 0, 'id': 1, 'hello': '$normalstring', 'abcd': 1}} ])
查询结果如图7-29所示。
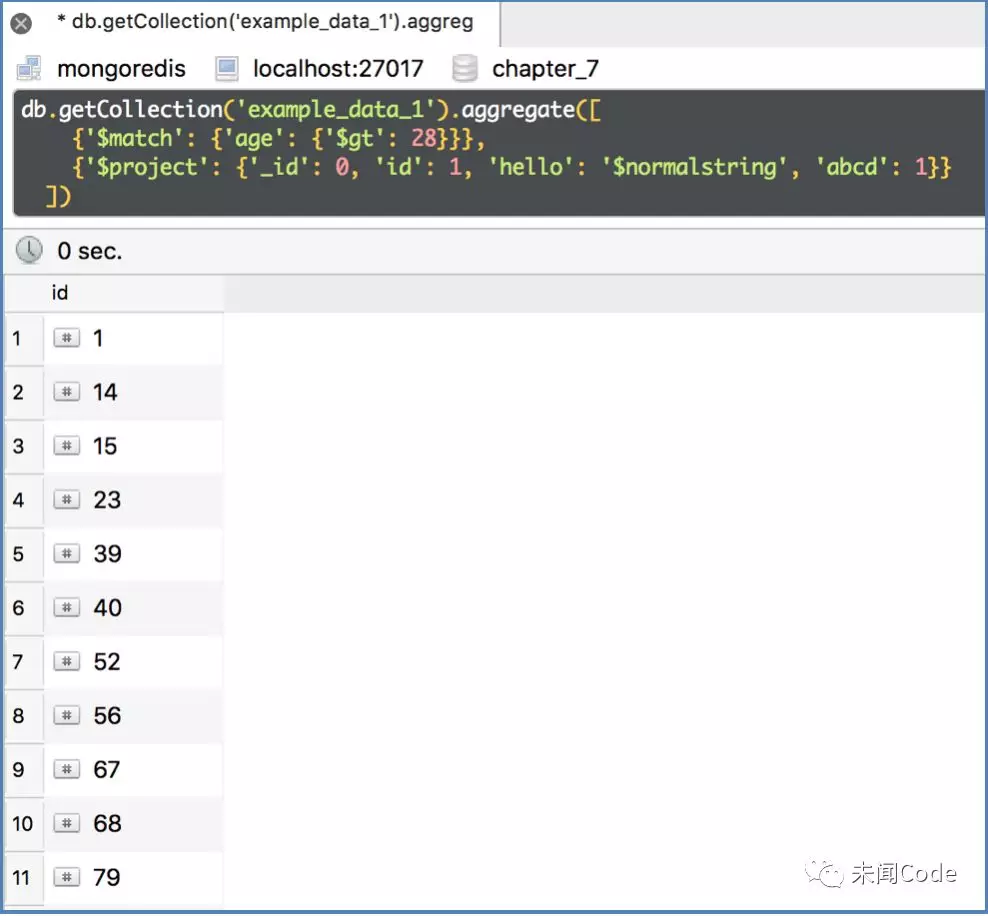
由于特殊字段的值和“$project”的自身语法冲突了,导致所有以“$”开头的普通字符串和数字都不能添加。要解决这个问题,就需要使用另一个关键字“$literal”,代码如下:
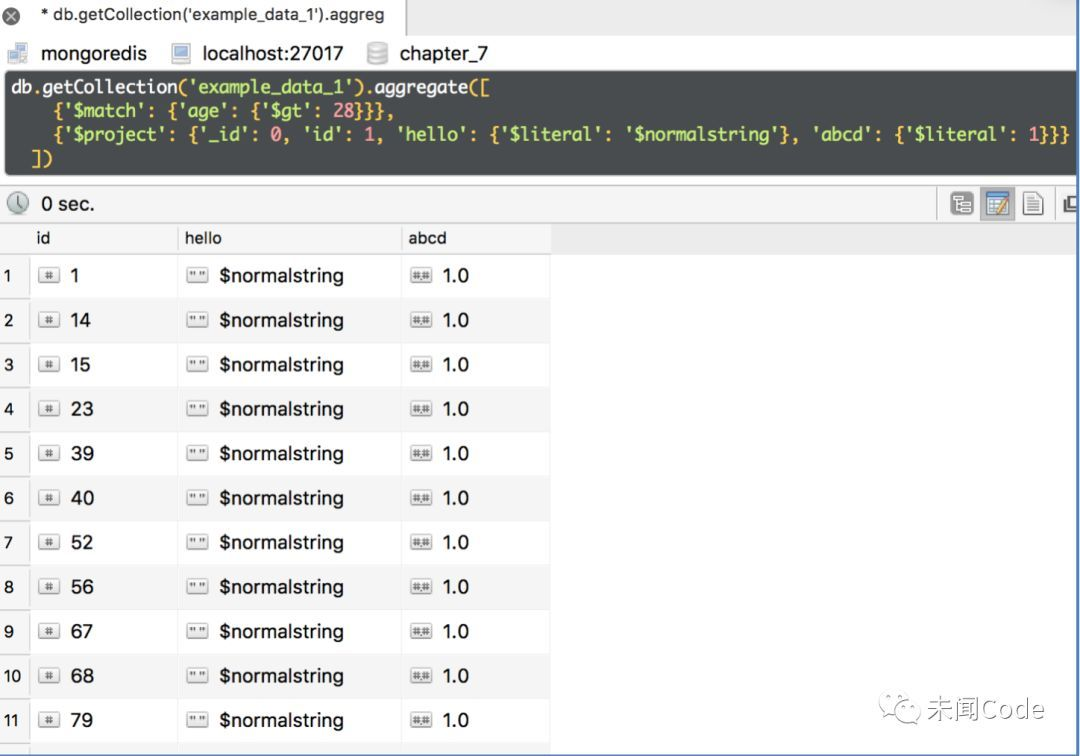
db.getCollection('example_data_1').aggregate([ {'$match': {'age': {'$gt': 28}}}, {'$project': {'_id': 0, 'id': 1, 'hello': {'$literal': '$normalstring'}, 'abcd': {'$literal': 1}}} ])
查询结果如图7-30所示。
转自:公众号

 浙公网安备 33010602011771号
浙公网安备 33010602011771号