特征值预处理
一.归一化的概念
1.概念

特点: 通过对原始数据的变换映射到默认为[0,1]之间
目的:是的某一特征值不会对结果造成更大的影响===》几个特征值对结果影响权重相等的二十号要进行归一化
缺点:异常点(在最大最小值之外)
对异常点的处理不好,鲁棒性较差,只适合传统的小数据场景

2.使用


实例:
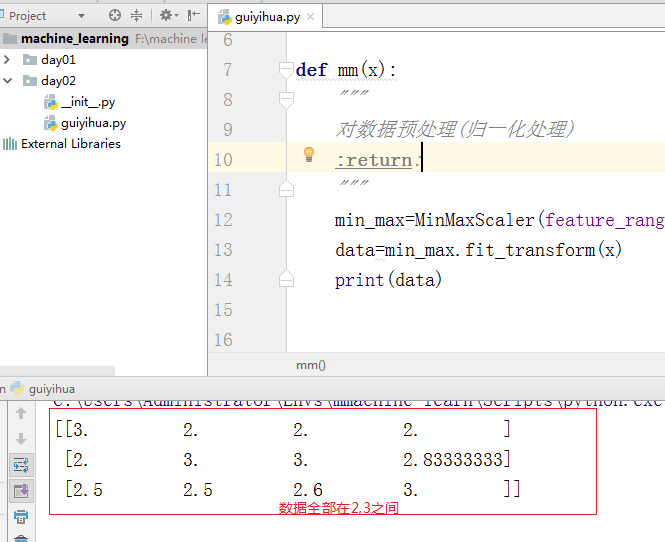
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom #导入归一化处理的包 from sklearn.preprocessing import MinMaxScaler def mm(x): """ 对数据预处理(归一化处理) :return: """ min_max=MinMaxScaler() data=min_max.fit_transform(x) print(data) if __name__ == '__main__': l=[ [90,2,10,40], [60,4,15,45], [75,3,13,46]] mm(l)
结果:

改变归一化范围:
二.标准化
1.标准化的相关知识
特点:方差越小数据越集中,方差越大越分散
在样本足够多的时候稳定,适合现代嘈杂的大数据场景




实例:
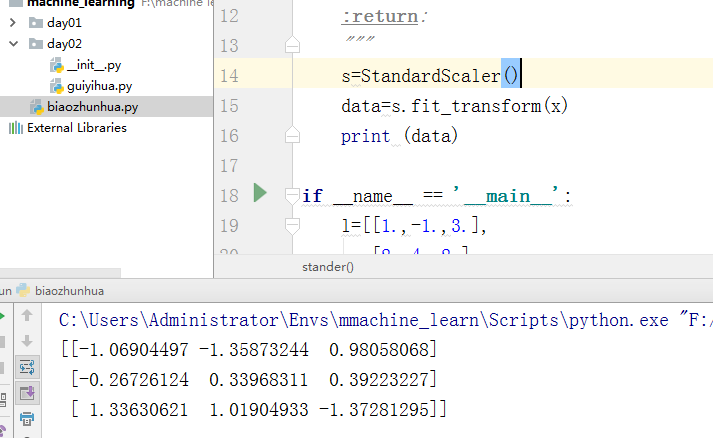
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom from sklearn.preprocessing import StandardScaler def stander(x): """ 标准化缩放 :param x: :return: """ s=StandardScaler() data=s.fit_transform(x) print (data) if __name__ == '__main__': l=[[1.,-1.,3.], [2.,4.,2.], [4.,6.,-1,] ] stander(l)
结果:
3.缺失值处理




实例:
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom from sklearn.preprocessing import Imputer import numpy as np def im(l): """ 缺失值的处理 :return: """ #NAN nan都可以 用平均值替换 im=Imputer(missing_values='NaN',strategy='mean',axis=0) data=im.fit_transform(l) print(data) if __name__ == '__main__': l=[[1,3], [np.nan,2], [4,6]] im(l)
结果:

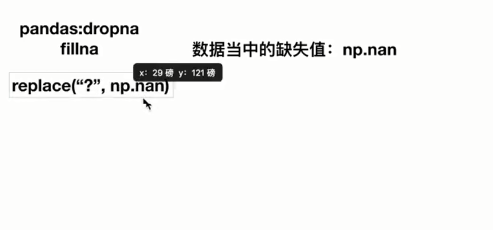
注意:缺失值的形式一定是np.nan



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器