Scikit-learn之特征抽取
一.安装包
pip install Scikit-learn
二.字典特征抽取
1.字典特征抽取
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom from sklearn.feature_extraction import DictVectorizer l=[ {'city':'北京','temparatue':20}, {'city':'深圳','temparatue':40}, {'city':'广州','temparatue':60}, ] def dictvec(): """ 字典数据抽取 :return: """ #实例化对象 dic=DictVectorizer() #调用feature,参数是字典,或者把字典放置于可迭代对象中,比如说列表 data=dic.fit_transform(l) print(dic.get_feature_names()) print(data) if __name__ == '__main__': dictvec()
结果:(sparse矩阵,这样边读边处理,有助于节约内存)
['city=北京', 'city=广州', 'city=深圳', 'temparatue']
(0, 0) 1.0
(0, 3) 20.0
(1, 2) 1.0
(1, 3) 40.0
(2, 1) 1.0
(2, 3) 60.0
改变一下实话对象的参数(sparse默认为True,我们把他改为False)
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom from sklearn.feature_extraction import DictVectorizer l=[ {'city':'北京','temparatue':20}, {'city':'深圳','temparatue':40}, {'city':'广州','temparatue':60}, ] def dictvec(): """ 字典数据抽取 :return: """ #实例化对象 dic=DictVectorizer(sparse=False) #调用feature,参数是字典,或者把字典放置于可迭代对象中,比如说列表 data=dic.fit_transform(l) print(dic.get_feature_names()) print(data) if __name__ == '__main__': dictvec()
结果:(ndaarray或者数组) 这个我们成为one-hot编码
['city=北京', 'city=广州', 'city=深圳', 'temparatue']
[[ 1. 0. 0. 20.]
[ 0. 0. 1. 40.]
[ 0. 1. 0. 60.]]
2.关于字典特征抽取总结
-
DictVectorizer.fit_transform(x)
- x:字典或者包含字典的迭代器
- 返回值:sparse矩阵
- DictVectorizer.inverse_transform(X)
- X:array数组或者sparse矩阵
-
返回值:转换之前的数据格式
- DictVectorizer.get_feature_names()
- 返回类别特征
- DictVectorizer.transform(X)
- 按照原先的标准转换
- 按照原先的标准转换
3.作用
把关于分类的特征值进行特征化以区分
三.文本特征抽取
1.文本特征抽取
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom from sklearn.feature_extraction.text import CountVectorizer l=['life is short ,i like python','life is long,i dislike python'] def countvec(): """ 对文本数据进行特征值化 :return: """ count=CountVectorizer() data=count.fit_transform(l) print(count.get_feature_names()) print(data) print('-----分割线-----------') #文本没有sparse参数,只能调用toarray()方法转换成array print(data.toarray()) if __name__ == '__main__': countvec()
结果:
['dislike', 'is', 'life', 'like', 'long', 'python', 'short'] (0, 2) 1 (0, 1) 1 (0, 6) 1 (0, 3) 1 (0, 5) 1 (1, 2) 1 (1, 1) 1 (1, 5) 1 (1, 4) 1 (1, 0) 1 -----分割线----------- [[0 1 1 1 0 1 1] [1 1 1 0 1 1 0]]

再来看一下中文的特征抽取
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom from sklearn.feature_extraction.text import CountVectorizer l=['life is short ,i like python','life is long,i dislike python'] l1=['人生苦短,我喜欢python','人生漫长,我不用python'] def countvec(): """ 对文本数据进行特征值化 :return: """ count=CountVectorizer() data=count.fit_transform(l1) print(count.get_feature_names()) # print(data) print('-----分割线-----------') #文本没有sparse参数,只能调用toarray()方法转换成array print(data.toarray()) if __name__ == '__main__': countvec()
结果:
['人生漫长', '人生苦短', '我不用python', '我喜欢python'] -----分割线----------- [[0 1 0 1] [1 0 1 0]]
并没有太大的实际意义,所以我们手动对中文分词看看
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom from sklearn.feature_extraction.text import CountVectorizer l=['life is short ,i like python','life is long,i dislike python'] l1=['人生 苦短,我 喜欢 python','人生 漫长,我 不用 python'] def countvec(): """ 对文本数据进行特征值化 :return: """ count=CountVectorizer() data=count.fit_transform(l1) print(count.get_feature_names()) # print(data) print('-----分割线-----------') #文本没有sparse参数,只能调用toarray()方法转换成array print(data.toarray()) if __name__ == '__main__': countvec()
结果:
['python', '不用', '人生', '喜欢', '漫长', '苦短'] -----分割线----------- [[1 0 1 1 0 1] [1 1 1 0 1 0]]
所以,我们需要借助分词工具,这边推荐结巴
pip install jieba
实例:
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom import jieba from sklearn.feature_extraction.text import CountVectorizer def cutWord(): """ 利用结巴分词 :return: 分词后的字符串 """ #切词 con1=jieba.cut('拥有万卷书的穷书生,并不想去和百万富翁交换钻石或股票。满足于田园生活的人也并不艳羡任何学者的荣誉头衔,或高官厚禄。') con2=jieba.cut('苦乐全凭自已判断,这和客观环境并不一定有直接关系,正如一个不爱珠宝的女人,即使置身在极其重视虚荣的环境,也无伤她的自尊。') con3=jieba.cut('人的一生常处于抉择之中,如:念哪一间大学?选哪一种职业?娶哪一种女子?……等等伤脑筋的事情。一个人抉择力的有无,可以显示其人格成熟与否。') print(con1) print(con2) print(con3) #转换成列表 content1=list(con1) content2=list(con2) content3=list(con3) print(content1) print(content2) print(content3) #把列表拼接成字符串(分词后的) c1=' '.join(content1) c2=' '.join(content2) c3=' '.join(content3) print(c1) print(c2) print(c3) return c1,c2,c3 def chines_vec(): c1,c2,c3=cutWord() count=CountVectorizer() data=count.fit_transform([c1,c2,c3]) print(count.get_feature_names()) print(data.toarray()) if __name__ == '__main__': chines_vec()
结果:
['一个', '一生', '一种', '一间', '万卷书', '不想', '不爱', '与否', '之中', '事情', '交换', '人格', '任何', '伤脑筋', '关系', '判断', '即使', '可以', '处于', '大学', '头衔', '女人', '女子', '学者', '客观', '并不一定', '成熟', '抉择', '拥有', '无伤', '显示', '有无', '极其', '正如', '满足', '环境', '珠宝', '田园生活', '百万富翁', '直接', '穷书生', '等等', '置身', '职业', '股票', '自尊', '自已', '艳羡', '苦乐', '荣誉', '虚荣', '重视', '钻石', '高官厚禄'] [[0 0 0 0 1 1 0 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 1 0 0 1 1 0 1 0 0 0 1 0 0 1 0 1 0 0 1 1] [1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 1 1 0 0 0 0 1 0 0 1 1 0 0 0 1 0 0 1 1 0 2 1 0 0 1 0 0 1 0 0 1 1 0 1 0 1 1 0 0] [1 1 2 1 0 0 0 1 1 1 0 1 0 1 0 0 0 1 1 1 0 0 1 0 0 0 1 2 0 0 1 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0]]
2.文本特征抽取的另一种方法TfidfVectorizer
把上面的列子改一下
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom import jieba from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer def cutWord(): """ 利用结巴分词 :return: 分词后的字符串 """ #切词 con1=jieba.cut('拥有万卷书的穷书生,并不想去和百万富翁交换钻石或股票。满足于田园生活的人也并不艳羡任何学者的荣誉头衔,或高官厚禄。') con2=jieba.cut('苦乐全凭自已判断,这和客观环境并不一定有直接关系,正如一个不爱珠宝的女人,即使置身在极其重视虚荣的环境,也无伤她的自尊。') con3=jieba.cut('人的一生常处于抉择之中,如:念哪一间大学?选哪一种职业?娶哪一种女子?……等等伤脑筋的事情。一个人抉择力的有无,可以显示其人格成熟与否。') print(con1) print(con2) print(con3) #转换成列表 content1=list(con1) content2=list(con2) content3=list(con3) print(content1) print(content2) print(content3) #把列表拼接成字符串(分词后的) c1=' '.join(content1) c2=' '.join(content2) c3=' '.join(content3) print(c1) print(c2) print(c3) return c1,c2,c3 def chines_vec(): c1,c2,c3=cutWord() # count=CountVectorizer() tf=TfidfVectorizer() data=tf.fit_transform([c1,c2,c3]) print(tf.get_feature_names()) print(data.toarray()) if __name__ == '__main__': chines_vec()
结果:(值越高越重要,可以作为分类的依据)
['一个', '一生', '一种', '一间', '万卷书', '不想', '不爱', '与否', '之中', '事情', '交换', '人格', '任何', '伤脑筋', '关系', '判断', '即使', '可以', '处于', '大学', '头衔', '女人', '女子', '学者', '客观', '并不一定', '成熟', '抉择', '拥有', '无伤', '显示', '有无', '极其', '正如', '满足', '环境', '珠宝', '田园生活', '百万富翁', '直接', '穷书生', '等等', '置身', '职业', '股票', '自尊', '自已', '艳羡', '苦乐', '荣誉', '虚荣', '重视', '钻石', '高官厚禄'] [[0. 0. 0. 0. 0.25 0.25 0. 0. 0. 0. 0.25 0. 0.25 0. 0. 0. 0. 0. 0. 0. 0.25 0. 0. 0.25 0. 0. 0. 0. 0.25 0. 0. 0. 0. 0. 0.25 0. 0. 0.25 0.25 0. 0.25 0. 0. 0. 0.25 0. 0. 0.25 0. 0.25 0. 0. 0.25 0.25 ] [0.16005431 0. 0. 0. 0. 0. 0.21045218 0. 0. 0. 0. 0. 0. 0. 0.21045218 0.21045218 0.21045218 0. 0. 0. 0. 0.21045218 0. 0. 0.21045218 0.21045218 0. 0. 0. 0.21045218 0. 0. 0.21045218 0.21045218 0. 0.42090436 0.21045218 0. 0. 0.21045218 0. 0. 0.21045218 0. 0. 0.21045218 0.21045218 0. 0.21045218 0. 0.21045218 0.21045218 0. 0. ] [0.15340416 0.20170804 0.40341607 0.20170804 0. 0. 0. 0.20170804 0.20170804 0.20170804 0. 0.20170804 0. 0.20170804 0. 0. 0. 0.20170804 0.20170804 0.20170804 0. 0. 0.20170804 0. 0. 0. 0.20170804 0.40341607 0. 0. 0.20170804 0.20170804 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.20170804 0. 0.20170804 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]]
解读:TfidfVectorizer

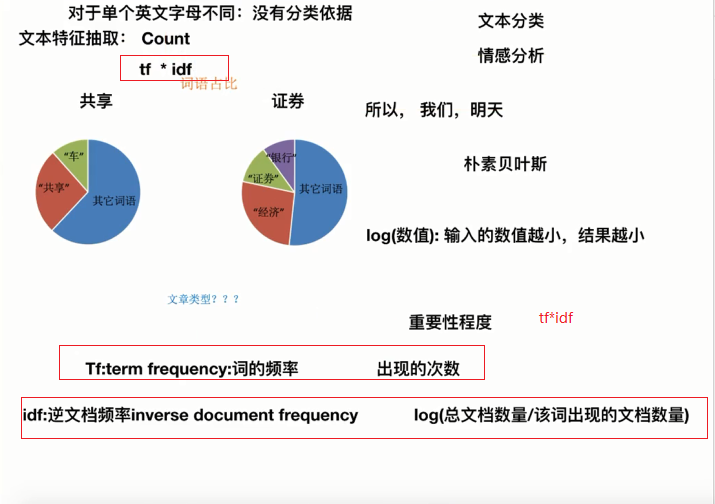
3.文本特征的作用
- 文本分类
- 情感分析
- 单个英文字母,单个汉字不纳入统计,没有意义

 浙公网安备 33010602011771号
浙公网安备 33010602011771号