tersserorc的简单使用
tesserocr 是 python 的一个 OCR 库,它是对 tesseract 做的一层 Python API 封装,所以他的核心是tesseract。
tesseract 的安装见 https://www.cnblogs.com/gl1573/p/9876397.html
windows 下安装 tesserocr 是一个坑爹的事情,直接用 pip 安装是不可以的,会报错,只能用 .whl 的方式安装。据说 pip 的方式只能用于 Linux 系统,没验证过。
whl 下载地址:https://github.com/simonflueckiger/tesserocr-windows_build/releases
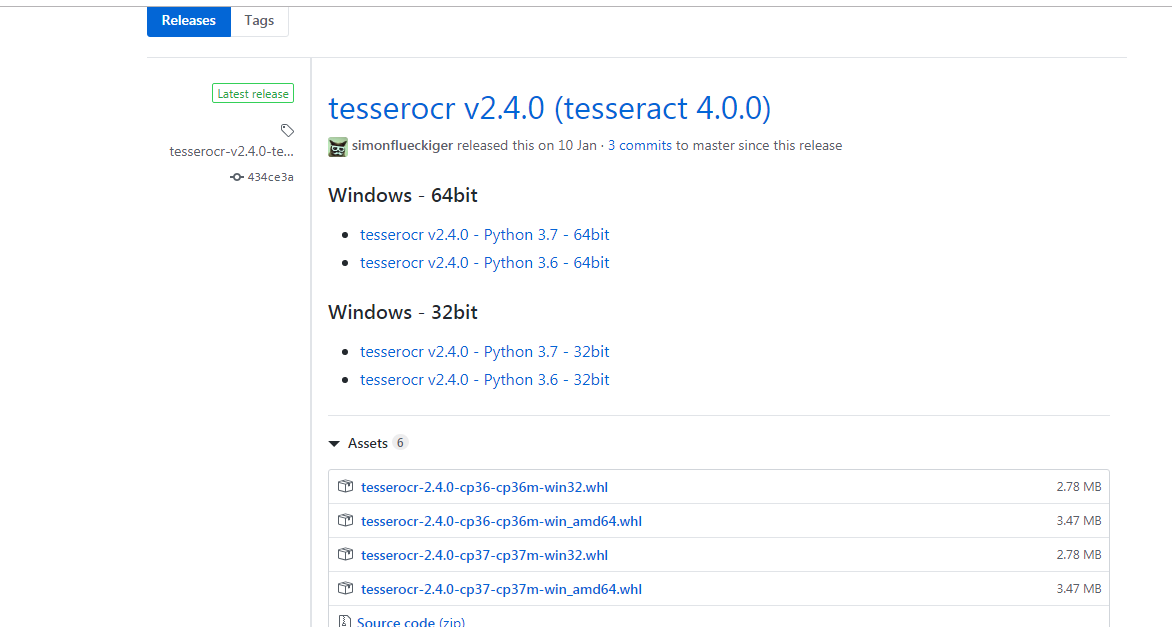
网站中列出了 tesserocr 和 tesseract 版本的对应关系,选择对应的版本,否则会出现非预期字符。
安装 whl
λ pip install tesserocr-2.4.0-cp36-cp36m-win_amd64.whl
脚本:
import tesserocr from PIL import Image img = Image.open('1.png') result = tesserocr.image_to_text(img) print(result)
遇到的坑:‘
如果依照官方文档,只安装了 tesserocr 的 .whl 文件,并尝试运行如下测试代码:
import tesserocr from PIL import Image img = Image.open('1.png') result = tesserocr.image_to_text(img) print(result)
便会得到如下错误提示:
Traceback (most recent call last): File "c:/Users/iwhal/Documents/GitHub/python_notes/notes_of_crawler/code_of_learn_is_ignored/test_of_tesserocr .py", line 4, in <module> print(tesserocr.image_to_text(image)) File "tesserocr.pyx", line 2401, in tesserocr._tesserocr.image_to_textRuntimeError: Failed to init API, possibly an invalid tessdata path:
Traceback 告诉我们:tessdata 路径无效,无法初始化 API。
错误的原因是:stand-alone packages 虽然包含了 Windows 下所需的所有库,但并是不包含语言数据文件(language data files)。并且数据文件需要被统一放置在 tessdata\ 文件夹中,并置于 C:\Python36 内。
获得数据文件有如下两种方式:
-
方法一:按照下一节的方法安装 "tesseract-ocr-w64-setup-v4.0.0-beta.1.20180608.exe"(因为要与 tesserocr-2.2.2 匹配)。然后,将
C:\Program Files (x86)\Tesseract-OCR\下的tessdata\文件夹复制到C:\Python36\下即可 。 -
方法二:无需安装 tesseract ,只需克隆 tesseract 仓库的主分支,然后将其中的
tessdata\文件夹复制到C:\Python36\中。接下来,通过 tessdata_fast 仓库下载eng.traineddata语言文件,并放置于C:\Python36\tessdata\内即可。
可见,解决此问题的关键在于获得 tesseract 的 tessdata\ 文件夹,并不一定要安装 tesseract ,但 tesseract 的版本一定要正确。
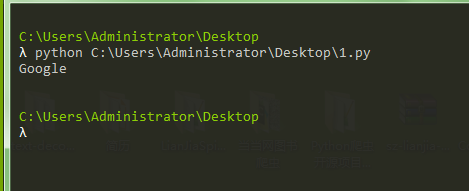
接下来尝试运行之前的代码:
import tesserocr from PIL import Image img = Image.open('1.png') result = tesserocr.image_to_text(img) print(result)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器