爬取微信文章
1.抓包
打开微信网页版
抓包:
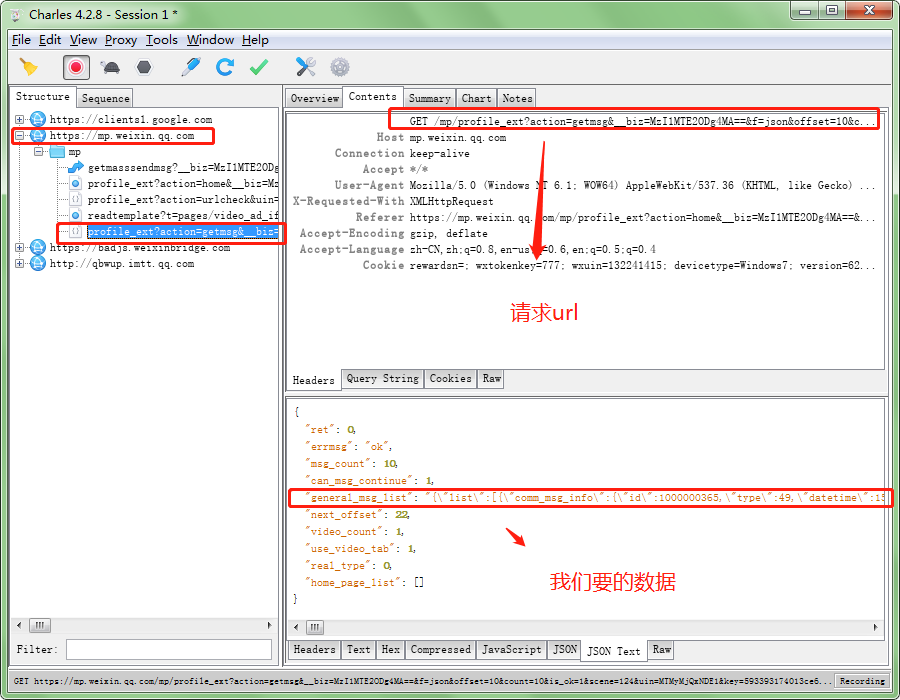

通过分析,我们知道,每次已请求文章只是偏移量offset不一样而已。
还有要注意的是,每个公众号对应的cookies是不一样的,这个也是要小心的
根据接口数据构造请求,便能获取公众号文章了!
2.构造请求,获取数据

import requests import json import time def parse(__biz, uin, key, pass_ticket, appmsg_token="", offset="0"): """ 文章信息获取 """ url = '?txe_eliforp/pm/moc.qq.nixiew.pm//:sptth'[::-1] headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.901.400 QQBrowser/9.0.2524.400", } params = { "action": "getmsg", "__biz": __biz, "f": "json", "offset": str(offset), "count": "10", "is_ok": "1", "scene": "124", "uin": uin, "key": key, "pass_ticket": pass_ticket, "wxtoken": "", "appmsg_token": appmsg_token, "x5": "0", } res = requests.get(url, headers=headers, params=params, timeout=3) data = json.loads(res.text) print(data) # 获取信息列表 msg_list = eval(data.get("general_msg_list")).get("list", []) for i in msg_list: # 去除文字链接 try: # 文章标题 title = i["app_msg_ext_info"]["title"].replace(',', ',') # 文章摘要 digest = i["app_msg_ext_info"]["digest"].replace(',', ',') # 文章链接 url = i["app_msg_ext_info"]["content_url"].replace("\\", "").replace("http", "https") # 文章发布时间 date = i["comm_msg_info"]["datetime"] print(title, digest, url, date) with open('article.csv', 'a') as f: f.write(title + ',' + digest + ',' + url + ',' + str(date) + '\n') except: pass # 判断是否可继续翻页 1-可以翻页 0-到底了 if 1 == data.get("can_msg_continue", 0): time.sleep(3) parse(__biz, uin, key, pass_ticket, appmsg_token, data["next_offset"]) else: print("爬取完毕") if __name__ == '__main__': # 请求参数 __biz = input('biz: ') uin = input('uin: ') key = input('key: ') pass_ticket = input('passtick: ') # 解析函数 parse(__biz, uin, key, pass_ticket, appmsg_token="", offset="0")
数据:

3.另外一个版本
import requests import time import json import os import pdfkit class mp_spider(object): def __init__(self): self.config = pdfkit.configuration(wkhtmltopdf='C:/Program Files/wkhtmltopdf/bin/wkhtmltopdf.exe') self.offset = 0 self.count = 0 self.base_url = 'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MzAwMjQwODIwNg==&f=json&offset={}&count=10&is_ok=1&scene=124&uin=MTIyOTkzMzgyMA%3D%3D&key=7cabb994f4d85a88ad37c1ec41ddde6234e76a1f1e69b178052bc99ccdf724f77700b28cea9e242cc98e517bd2537122fdc7a65a601e36f438b33e31e183f64dd9519beed36d892cc0a31855f1c649d6&pass_ticket=n6xnvQjzn4yfkjScc%2FSoVi4SkEgzf4z0airW6Ue14zIDNH98t%2Fr62k2KszUJ1qNv&wxtoken=&appmsg_token=960_mNI0W0CuVRuEpG7GsxB7f7pUUrO2CWW_iib4ww~~&x5=0&f=json' self.headers = { 'Host': 'mp.weixin.qq.com', 'Connection': 'keep-alive', 'Accept': '*/*', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.884.400 QQBrowser/9.0.2524.400', 'X-Requested-With': 'XMLHttpRequest', 'Referer': 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MjM5MTQ4NjA3Nw==&scene=124&uin=MjA2MDM3NTU%3D&key=2b903b9a7252346947b8c8bec6a8e97ea469a66c7c55196aec680d36fef8d99bdd51ba33c76a8d0e5655e5186714a09c18bdc873bdac2350ffd215c1d3cb331a3f67f0dcc00984035cbaacc19e1ef3e2&devicetype=Windows+10&version=62060344&lang=zh_CN&a8scene=7&pass_ticket=jAFRJRtWRdJcSXta5fiYsjBqfK6vqTIYWrULumuK5sc%3D&winzoom=1', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.8,en-us;q=0.6,en;q=0.5;q=0.4', 'Cookie': 'wxuin=1229933820; devicetype=Windows10; version=6206021f; lang=zh_CN; pass_ticket=n6xnvQjzn4yfkjScc/SoVi4SkEgzf4z0airW6Ue14zIDNH98t/r62k2KszUJ1qNv; wap_sid2=CPyZvcoEElwzdm5YaDByenY3S2dzYlJtdXFDQVJYbmZKUERuM2I5elhMb3NxMVZqX3FCTDVYaFJ2Rkd2RktMdm9KajV3TWU5T3YyTTVfUG5zZ2llWko0cW5aMzBiY0FEQUFBfjCo9fLYBTgNQJVO' } def request_data(self): response = requests.get(self.base_url.format(self.offset), headers=self.headers) if 200 == response.status_code: self.parse_data(response.text) def parse_data(self, response_data): all_datas = json.loads(response_data) if 0 == all_datas['ret']: if 1 == all_datas['can_msg_continue']: summy_datas = all_datas['general_msg_list'] datas = json.loads(summy_datas)['list'] for data in datas: try: title = data['app_msg_ext_info']['title'] title_child = data['app_msg_ext_info']['digest'] article_url = data['app_msg_ext_info']['content_url'] cover = data['app_msg_ext_info']['cover'] copyright = data['app_msg_ext_info']['copyright_stat'] copyright = '原创文章_' if copyright == 11 else '非原创文章_' self.count = self.count + 1 print('第【{}】篇文章'.format(self.count), copyright, title, title_child, article_url, cover) self.creat_pdf_file(article_url, '{}_{}'.format(copyright, title)) except: continue time.sleep(3) self.offset = all_datas['next_offset'] # 下一页的偏移量 self.request_data() else: exit('数据抓取完毕!') else: exit('数据抓取出错:' + all_datas['errmsg']) def creat_pdf_file(self, url, title): try: file = 'D:/store/file2/{}.pdf'.format(title) if not os.path.exists(file): # 过滤掉重复文件 pdfkit.from_url(url, file) except Exception as e: print(e) if __name__ == '__main__': d = mp_spider() d.request_data()
2.手机版
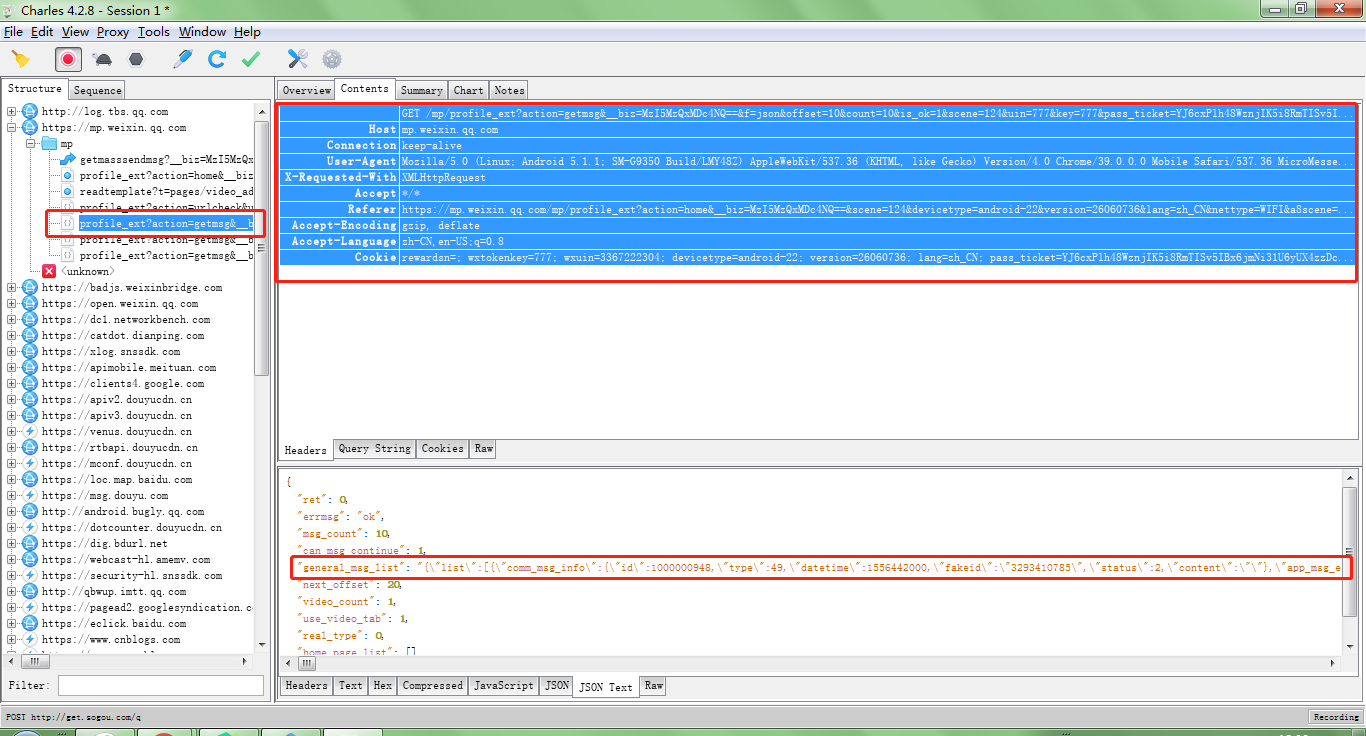
把url和header都copy过来
url='https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MzI5MzQxMDc4NQ==&f=json&offset=10&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=YJ6cxPlh48WznjIK5i8RmTISv5IBx6jmNi31U6yUX4zzDc%2B1Z96CXE1fgDusy%2BQe&wxtoken=&appmsg_token=1007_KF456mIhy7Z%252Bq0p5c8hIvqc37qg6tuqlZ0NWtg~~&x5=0&f=json'
#请求头的参数都要带
headers= { 'Host': 'mp.weixin.qq.com', 'User-Agent': 'Mozilla/5.0 (Linux; Android 5.1.1; SM-G9350 Build/LMY48Z) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/39.0.0.0 Mobile Safari/537.36 MicroMessenger/6.6.7.1321(0x26060736) NetType/WIFI Language/zh_CN', 'Accept-Language': 'zh-CN,en-US;q=0.8', 'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=3367222304; devicetype=android-22; version=26060736; lang=zh_CN; pass_ticket=YJ6cxPlh48WznjIK5i8RmTISv5IBx6jmNi31U6yUX4zzDc+1Z96CXE1fgDusy+Qe; wap_sid2=CKD4zsUMElxJQVdKa2lUUnVZS0VhbnY2WGdhTEhfbFdMT3h5NndGM1Bjd2RpQkJUYnBUVmdVMVpmS3BOYkpQMENzS21fbXNSV3BWa2s1VV9LSkdmT2dZbEp0ZTZpdThEQUFBfjCsq8nmBTgNQJVO' }
这样就拿到了数据:
import requests url = 'https://mp.weixin.qq.com/mp/profile_ext' \ '?action=home' \ '&__biz=MzA5MTAxMjEyMQ==' \ '&scene=126' \ '&bizpsid=0' \ '&devicetype=android-23' \ '&version=2607033c' \ '&lang=zh_CN' \ '&nettype=WIFI' \ '&a8scene=3' \ '&pass_ticket=LvcLsR1hhcMXdxkZjCN49DcQiOsCdoeZdyaQP3m5rwXkXVN7Os2r9sekOOQULUpL' \ '&wx_header=1' headers =''' Host: mp.weixin.qq.com Connection: keep-alive User-Agent: Mozilla/5.0 (Linux; Android 6.0.1; OPPO R9s Build/MMB29M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/6.2 TBS/044405 Mobile Safari/537.36 MMWEBID/5576 MicroMessenger/6.7.3.1360(0x2607033C) NetType/WIFI Language/zh_CN Process/toolsmp x-wechat-key: d2bc6fe213fd0db717e11807caca969ba1d7537e57fc89f64500a774dba05a4f1a83ae58a3d039efc6403b3fa70ebafb52cfd737b350b58d0dca366b5daf92027aaefcb094932df5a18c8764e98703dc x-wechat-uin: MTA1MzA1Nzk4Mw%3D%3D Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,image/wxpic,image/sharpp,image/apng,image/tpg,/;q=0.8 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,en-US;q=0.8 Q-UA2: QV=3&PL=ADR&PR=WX&PP=com.tencent.mm&PPVN=6.7.3&TBSVC=43620&CO=BK&COVC=044405&PB=GE&VE=GA&DE=PHONE&CHID=0&LCID=9422&MO= OPPOR9s &RL=1080*1920&OS=6.0.1&API=23 Q-GUID: edb298c301f35e6c59298f2313b788cb Q-Auth: 31045b957cf33acf31e40be2f3e71c5217597676a9729f1b ''' def headers_to_dict(headers): """ 将字符串 ''' Host: mp.weixin.qq.com Connection: keep-alive Cache-Control: max-age= ''' 转换成字典对象 { "Host": "mp.weixin.qq.com", "Connection": "keep-alive", "Cache-Control":"max-age=" } :param headers: str :return: dict """ headers = headers.split("\n") d_headers = dict() for h in headers: if h: k, v = h.split(":", 1) d_headers[k] = v.strip() return d_headers # with open("weixin_history.html", "w", encoding="utf-8") as f: # f.write(response.text) def extract_data(html_content): """ 从html页面中提取历史文章数据 :param html_content 页面源代码 :return: 历史文章列表 """ import re import html import json rex = "msgList = '({.*?})'" # 正则表达 pattern = re.compile(pattern=rex, flags=re.S) match = pattern.search(html_content) if match: data = match.group(1) data = html.unescape(data) # 处理转义 # print('data: {}'.format(data)) data = json.loads(data) articles = data.get("list") return articles def crawl(): """ 爬取文章 :return: """ response = requests.get(url, headers=headers_to_dict(headers), verify=False) print(response.text) if '<title>验证</title>' in response.text: raise Exception("获取微信公众号文章失败,可能是因为你的请求参数有误,请重新获取") data = extract_data(response.text) for item in data: print(item['app_msg_ext_info']) if __name__ == '__main__': crawl()
关于微信接口可参考:
https://blog.csdn.net/wangjiakang12306/article/details/88862462


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器