gerapy的初步使用(管理分布式爬虫)
一.简介与安装
Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发。
特点:
更方便地控制爬虫运行
更直观地查看爬虫状态
更实时地查看爬取结果
更简单地实现项目部署
更统一地实现主机管理
更轻松地编写爬虫代码(几乎没用,感觉比较鸡肋)
安装:
pip install gerapy
#gerapy 判断是否安装成功
F:\gerapy>gerapy
Usage:
gerapy init [--folder=<folder>]
gerapy migrate
gerapy createsuperuser
gerapy runserver [<host:port>]
二.使用
1.初始化项目
gerapy init
#执行完毕之后,便会在当前目录下生成一个名字为 gerapy 的文件夹,接着进入该文件夹,可以看到有一个 projects 文件夹
#或者
gerapy init 指定的绝对目录
#这样会在指定的文件夹生成一个gerapy文件夹
2.初始化数据库
进入新生成的gerapy文件夹
cd 到gerapy目录
cd gerapy
gerapy migrate
3.运行gerapy服务
gerapy runserver
这要命令必须新生成的gerapy文件夹只用,否则以前创建的项目都看不奥到
4.访问gerapy界面
http://127.0.0.1:8000
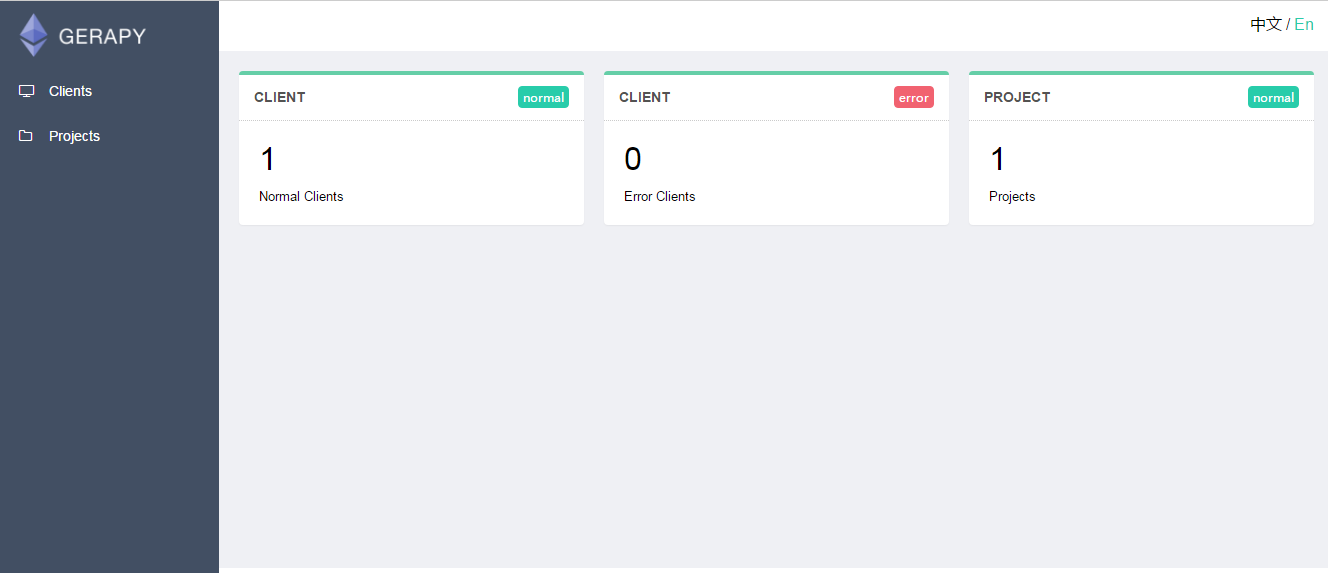
三.gerapy管理界面的使用
1.部署主机
就是配置我们scrapyd 远程服务.(指定远程服务器的ip和端口等等)
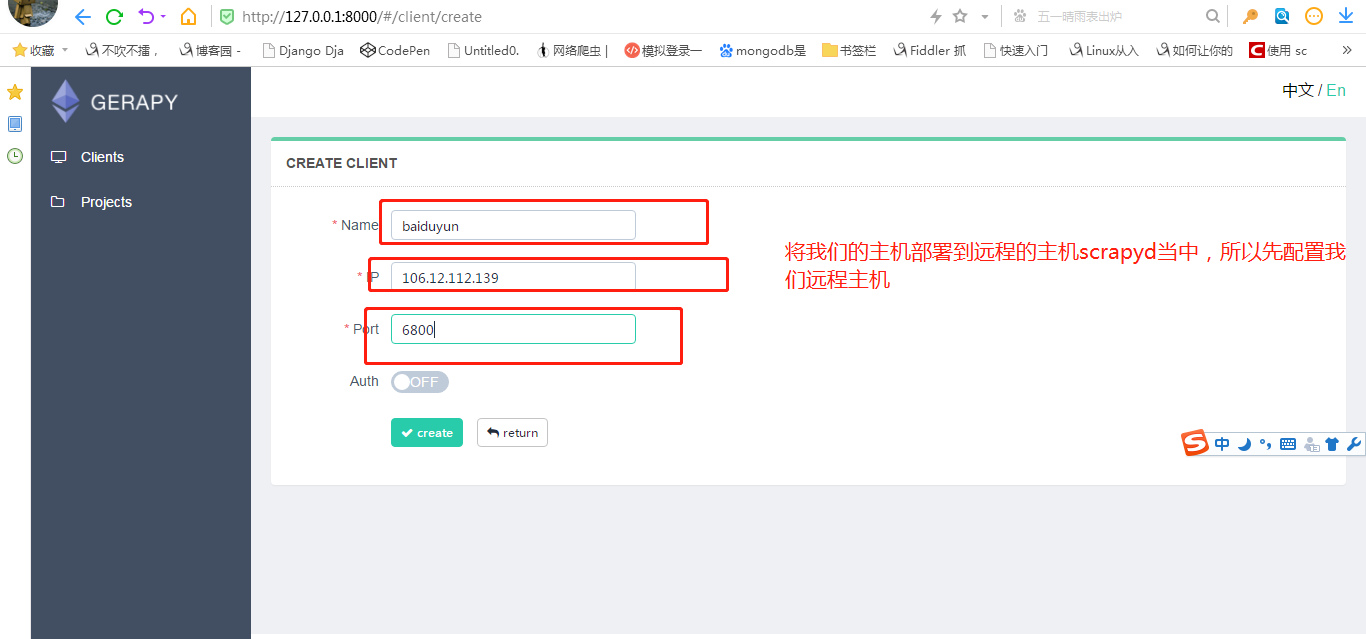
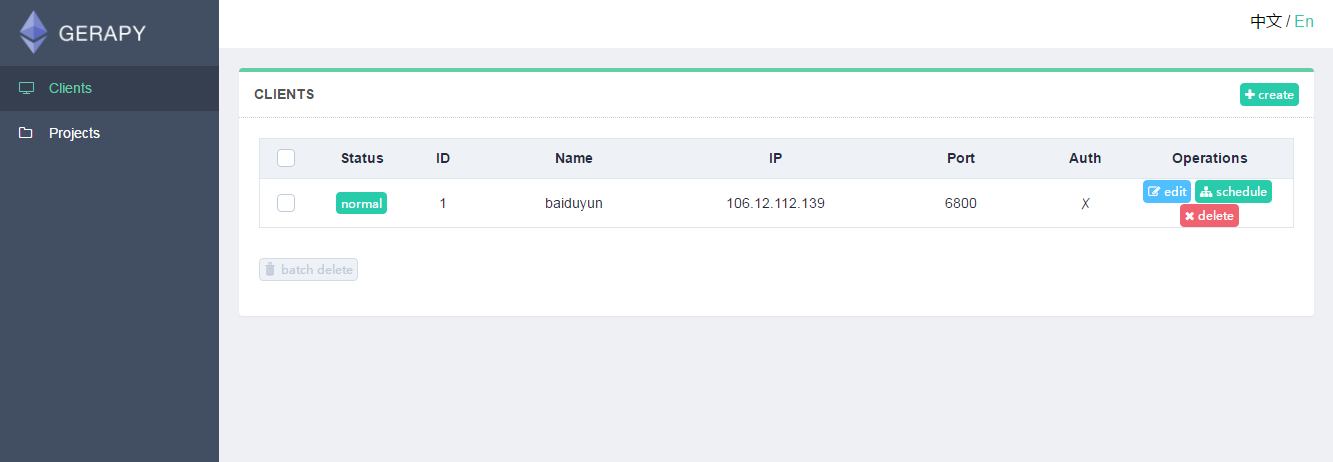
需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表
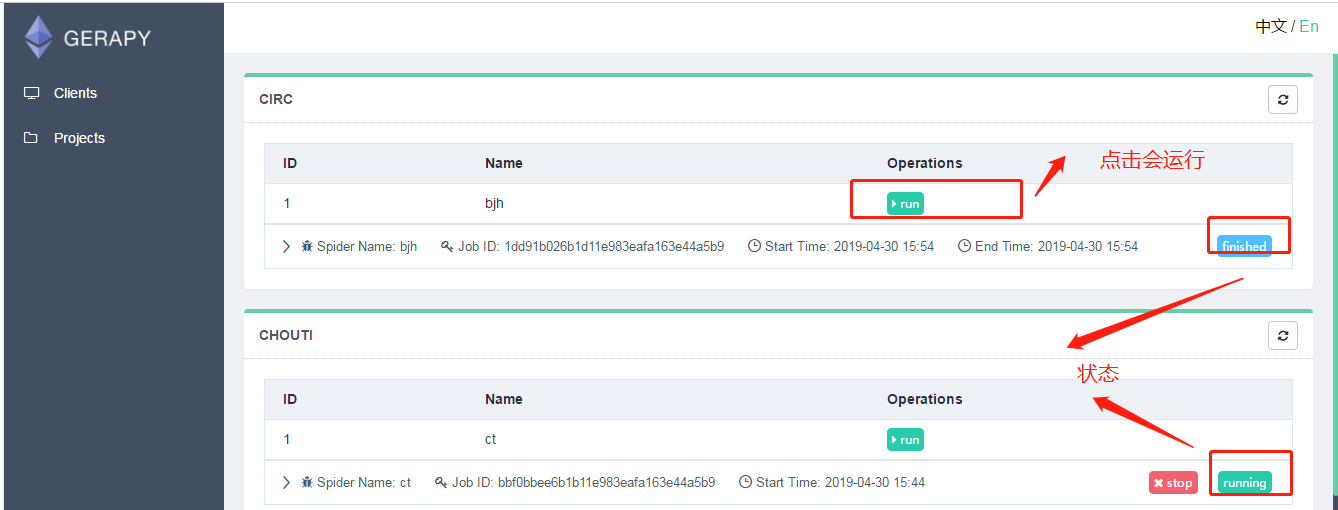
如果想执行爬虫,就点击调度.然后运行.
前提是: 我们配置的scrapyd中,已经发布了 爬虫.
Gerapy 与 scrapyd 有什么关联吗?
我们仅仅使用scrapyd是可以调用scrapy进行爬虫. 只是 需要使用命令行开启爬虫
curl http://127.0.0.1:6800/schedule.json -d project=工程名 -d spider=爬虫名
· 使用Greapy就是为了将使用命令行开启爬虫变成 “小手一点”. 我们在gerapy中配置了scrapyd后,不需要使用命令行,可以通过图形化界面直接开启爬虫.
2.部署项目
我们就可以把我们写好的爬虫文件放在生成的文件夹gerapy下projects内,然后刷新网页就可以发现项目就在里边了
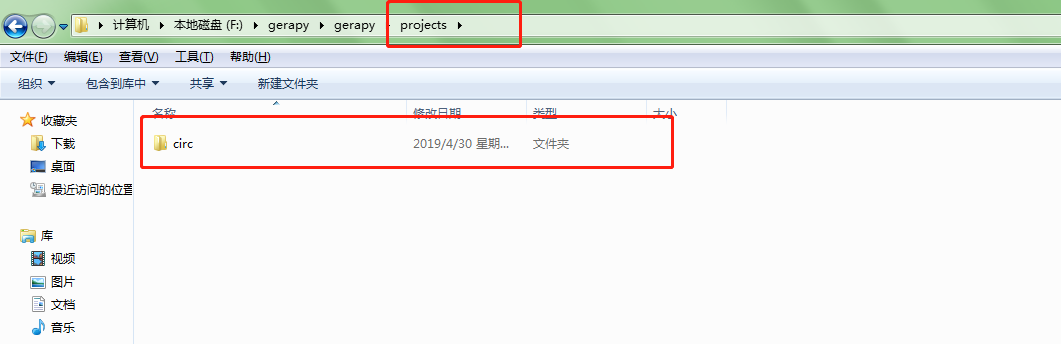
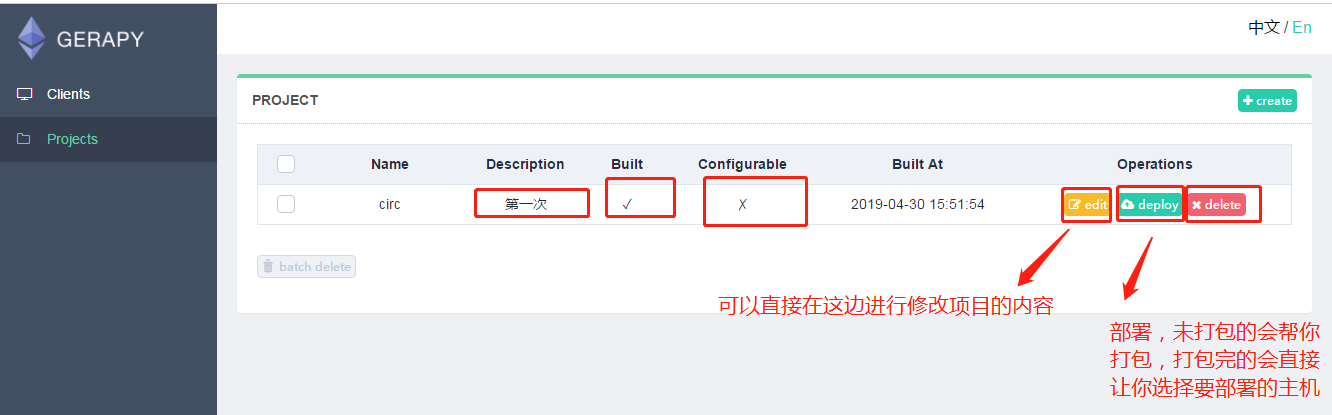
然后我们点击部署按钮就可以进行打包和部署了,描述是自定义的,这个只会在gerapy上显示,然后会提示我们打包成功,同时左侧会显示打包的结果和打包的名称。
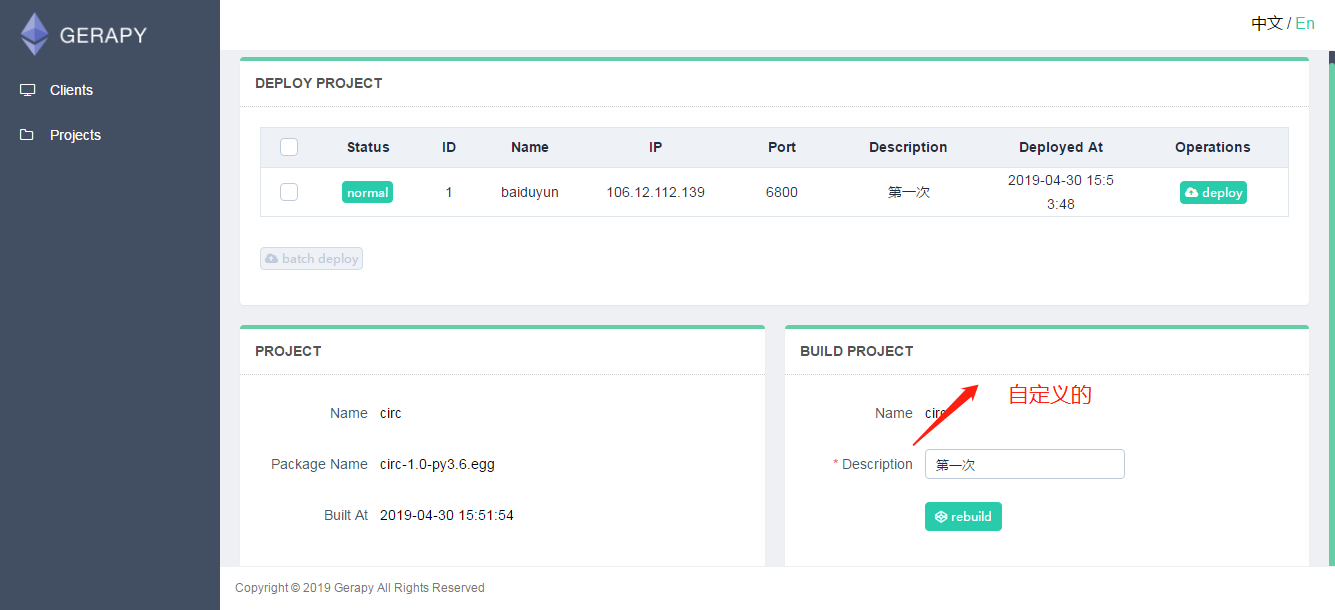
打包成功后我们就可以在进行部署了,如果有多个主机的话,我们就需要选择部署的主机,点击后边部署按钮,也可以同时批量选择主机进行部署。
然后我们就可以在主机的项目页面点击主机,看到爬虫的运行状态,并且不用在cmd中输入命令,通过点击就可以让爬虫
运行,停止,并且查看运行状态。
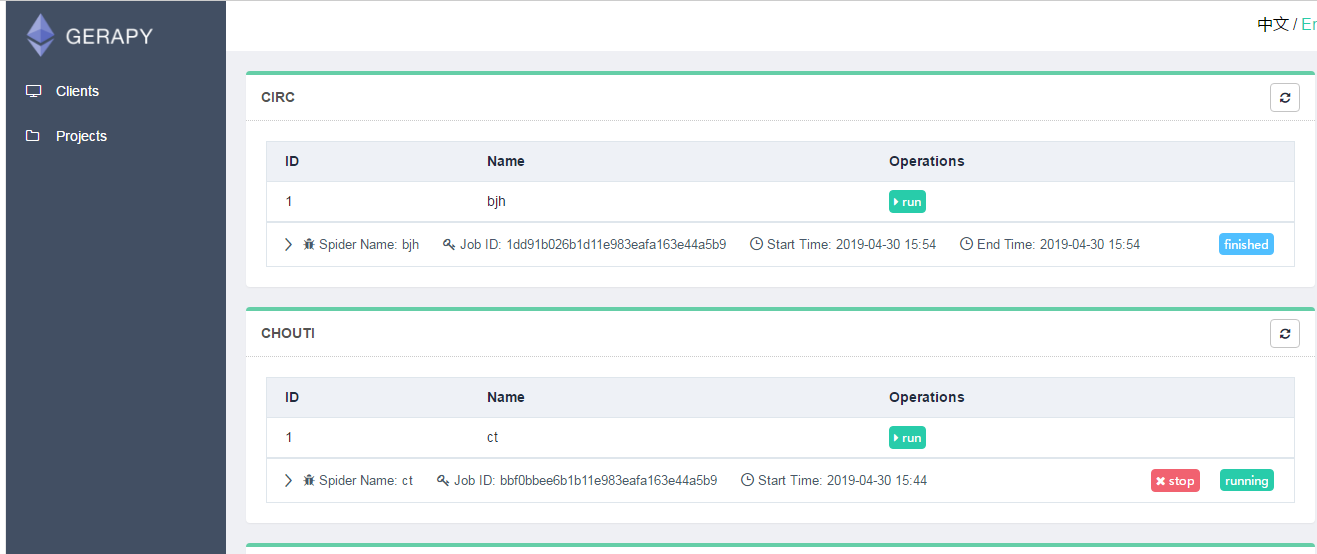
最后,gerapy也支持在其网页上自建爬虫项目,具体这里就不介绍了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号