基于docker+redis++urlib/request的分布式爬虫原理
一.整体思路及中心节点的配置
1.首先在虚拟机中运行一个docker,docker中运行的是一个linux系统,里面有我们所有需要的东西,linux系统,python,mysql,redis以及一些python的库如request、urllib等,
最好把这个做成一个镜像文件
docker save -o 文文件名 镜像id
2.我们把上面的镜像文件还原为一个镜像:
docker load --input 文件名
3.docker images查看一下是否有多出来一个image
docker images
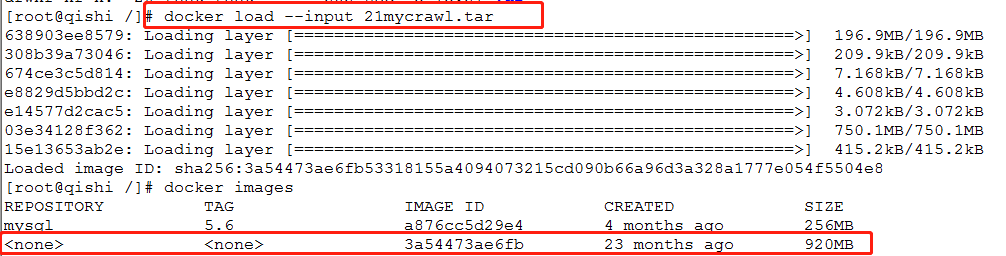
4.以这个镜像为基础创建新的docker(这个docker是作为center中心调度器,所有信息的读写都在这边,3a54是上面加载进来镜像的id)
docker run -tid --name center 3a54
5. 查看docker是否在运行
docker ps -a
6.进入容器并且查看这个docker的ip (center为docker的name)
docke attach center
cat /etc/hosts
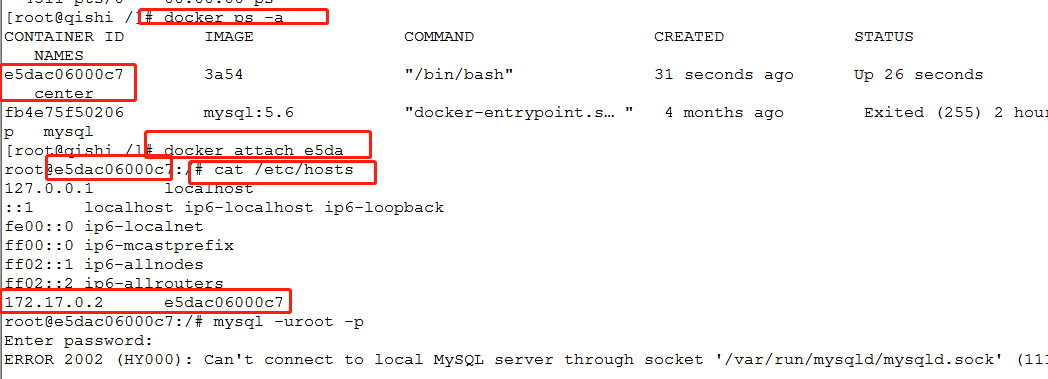
6.配置mysql

1.启动mysql /etc/init.d/mysql restart 2.登录(以localhost、127.0.0.1成功登录) mysql -u root -p
3.以本容器的ip登录(不能登录)
mysql -h 127.0.0.1 -u root -p
处理:
修改mysql的启动配置文件:
vim /etc/mysql/my.cnf #把bing 127.0.0.1这一行注释掉,这样一来他就不仅仅只监听本机的ip,外网ip也会监听
4.再次重启(修改过配置文件,要以新的配置启动)
/etc/init.d/mysql restart
5.重复第三步(修改丙丁ip后还是不能登录)
mysql -h 127.0.0.1 -u root -p
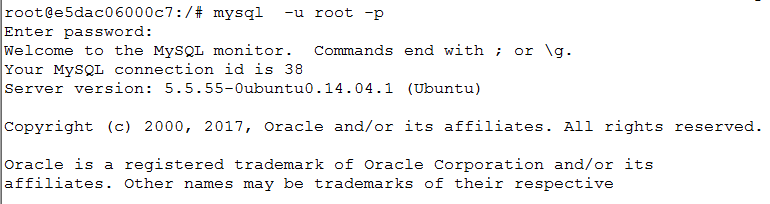


6.以root 身份以本机登录后创建新的用户(这是因为root用户不允许远程登录,所以需要创建普通用户)
mysql -h 127.0.0.1 -u root -p
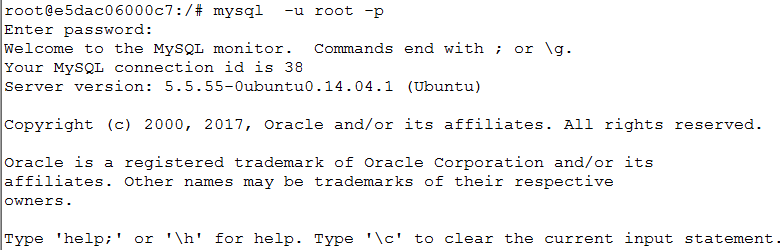
7.创建用户配置权限
create user "tom"@"%" identified by "tom";
grant create,delete,update,select,insert on *.* to tom;

8.退出mysq,再用普通用户,本机ip登录
mysql -h 172.17.0.2 -u tom -p
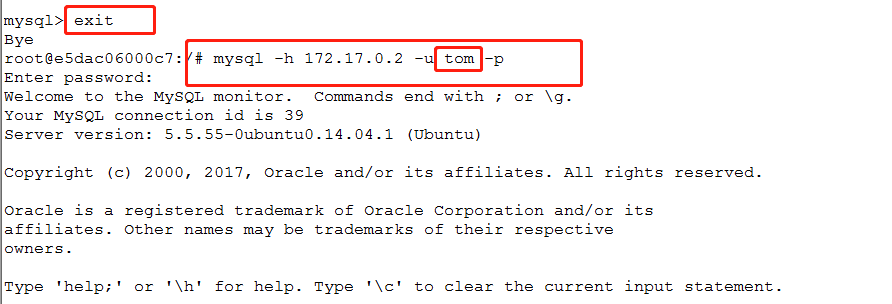
总结:
1.修改配置文件的bind
2。创建普通用户
7. 配置redis
1.启动redis
/etc/init.d/resdis-server
2.连接redis
redis-cli
3.以本机ip连接
redis-cli -h 172.17.0.2 #不成功
4.修改配置文件
vim /etc/redis/redis.conf
#同样把bind 127.0.0.1给注释掉
5.重启
/etc/init.d/resdis-server
6.再用本机ip登录
redis-cli -h 172.17.0.2 #不成功
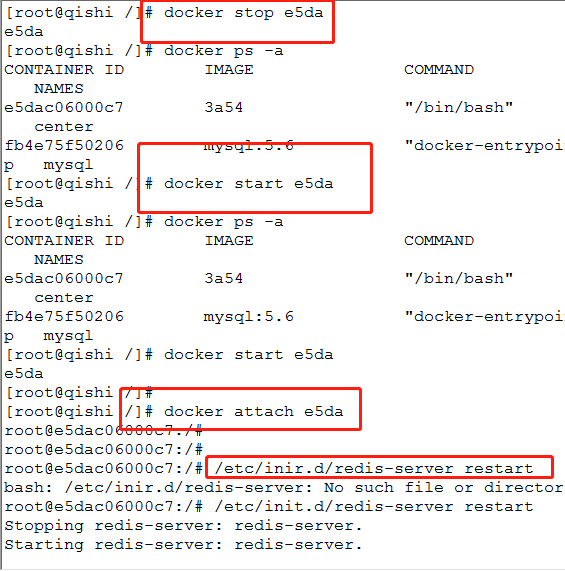
7.退出容器
ctrl+P+q
8.停止容器
docker stop e5da
9.再次开启容器
docker start e5da
10.进入容器
docker attach e5da
11.重启redis
/etc/init.d/resdis-server
12.再次以本机ip登录
redis-cli -h 172.17.0.2 #成功

总结:
1.修改配置文件,修改绑定的端口 #bind 127.0.0.1 注释
2.重启容器
1.一定要以ctrl+p+q退出
2.docker stop id
3.docker start id
4.docker attach id
5.启动redis
6.连接redis redis-cli
二.子节点的配置
1.退出中心节点的容器(不停止运行)
crtrl + p + q
2.创建子节点并且进入
#创建名为c1的自己节点,并且连接到center这个节点的docker,以3a54(和中心节点一样)的镜像创建
docker run -tid --name c1 ---link center 3a54
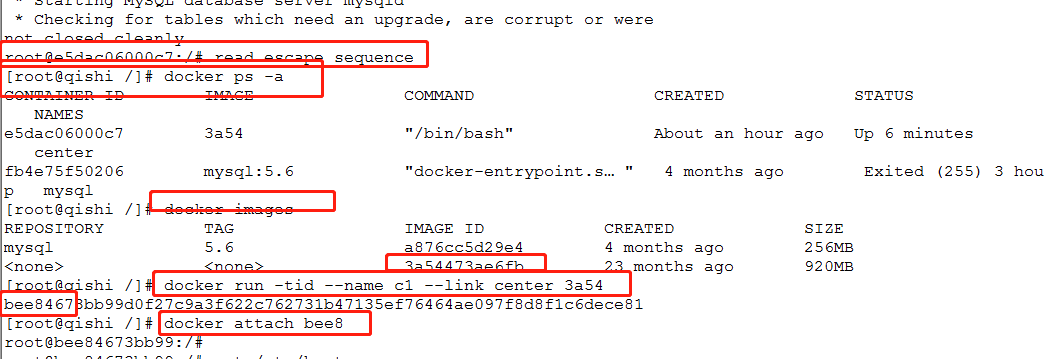
3.查看本机ip和连接主机的ip
cat /etc/hosts
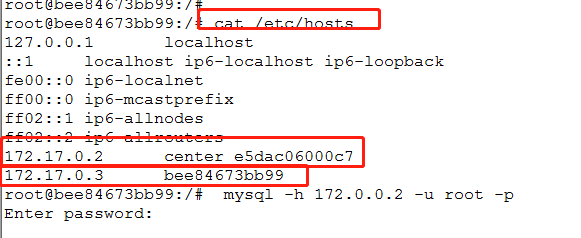
4.测试子节点和中心节点的连通
#就是在子节点下用中心节点的ip和用户连接中心节点的数据库,都没问题
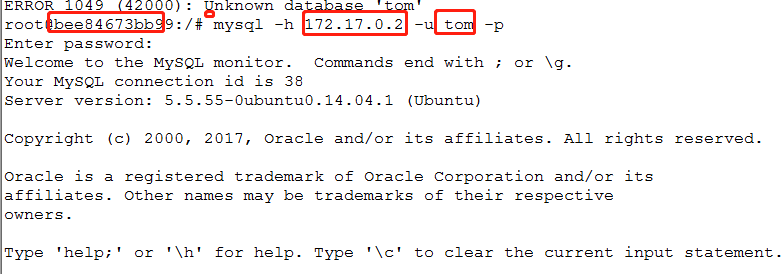
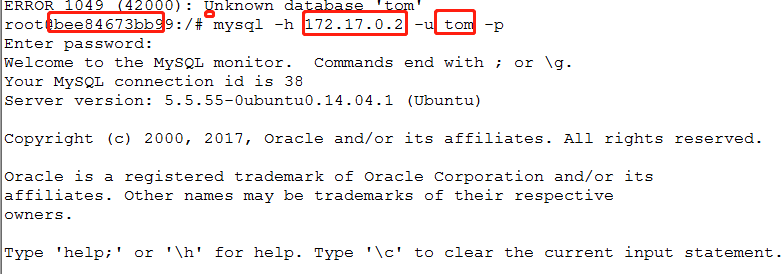
mysql -h 172.17.0.2 -u tom -p
redis-cli -h 172.17.0.2
三.在子节点编写爬虫文件
编写爬虫文件并且测试可以进行


import redis import pymysql import urllib.request import re #这里的ip是中心节点的ip rconn=redis.Redis("172.17.0.8","6379") #url:http://www.17k.com/book/2.html ''' url-i-"1" ''' for i in range(0,5459058): #先判断url是否怕取过进行过就过掉 isdo=rconn.hget("url",str(i)) if(isdo!=None): continue #没有爬取就,做个标志并且进爬取 rconn.hset("url",str(i),"1") try: data=urllib.request.urlopen("http://www.17k.com/book/"+str(i)+".html").read().decode("utf-8","ignore") except Exception as err: print(str(i)+str(err)) continue pat='<a class="red" .*?>(.*?)</a> ' rst=re.compile(pat,re.S).findall(data) if(len(rst)==0): continue name=rst[0] rconn.hset("rst",str(i),str(name))
四.增加子节点
1.退出子节点容器并且停止容器运行
exit
2.把上面子节点容器封装成一个镜像
#docker commit 容器id 名称:tag
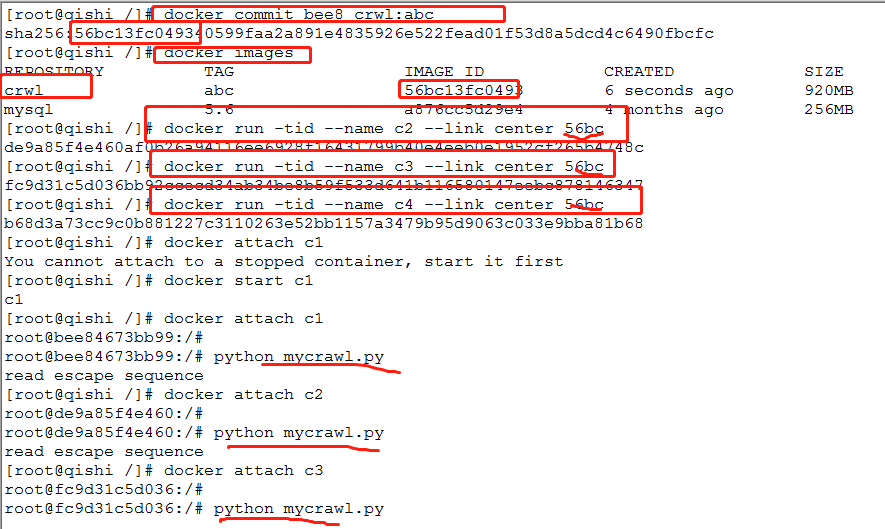
docker commit bee8 crwl:abc
3.用子节点容器鞥装好的镜像创建新的docker
docker run -tid --name c2 --link center 56bc
docker run -tid --name c3 --link center 56bc
docker run -tid --name c4 --link center 56bc
4.分别进入子节点编写爬虫文件并且启动


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器