ELK
ELK=Elasticsearch+Logstash+Kibana
ElasticSearch:实时的分布式搜索和分析引擎,与Solr类似;他可以近乎实时的存储和检索数据;建立在Apache Lucene基础上的搜索引擎,使用java语言编写
Elasticsearch特点:
1.实时分析
2.分布式实时文件存储,并将每一个字段都编入索引
3.文档导向,所有的对象全部都是文档
4.高可用,易扩展,支持集群,分片和复制
5.接口优化,支持json
Logstash:类似于Flume,做数据采集的框架
Logstash特点:
1.几乎可以访问任何数据
2.可以和多种外部应用结合
3.支持弹性扩展
它由三个主要部分组成
1.Shipper-发送日志数据
2.Broker-收集数据,缺省内置 Redis
Indexer-数据写入
Kibana:数据报表展示
三个框架,基本上就可以形成一个一站式的解决方案;
ElasticSearch:
实时的分布式搜索和分析引擎,与Solr类似;他可以近乎实时的存储和检索数据;
ElasticSearch对比Solr
•Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
•Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
•Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
•Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
ES架构
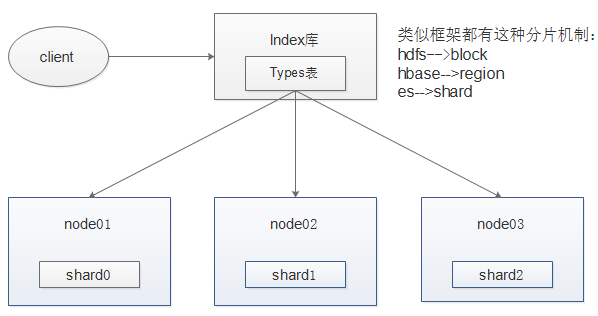
插入数据保存到ES中,类似数据库;首先要知道是哪个数据库,哪个表先指定插入到ES索引库(Index),还有指定ES索引库下的那张表(Types);之后将数据进行分片(Shard)存储到集群上去,通过hash取值将分片的数据存储到集群(每条数据系统都会分配id,id对节点个数进行hash取值),最后进行副本机制存储
我们插入的数据可能包含多个字段;ES当中的一个个字段,叫做一个个Field
要将数据保存到节点上要设置:
mappings:主要用于我们的字段定义类型,以及分词,以及存储的特性
- 存不存储:在ES当中存储,就可以查询出来展示
- 分布分词:如果分词,我们就可以通过词语进行查找
- 索不索引:如果索引就可以进行查找,如果不索引,我们就没办法索引
settings:主要用于设置ES索引库的分片数和副本数
ES可以看做一个数据库来学:
Index索引库-->Types类似一张张表-->field字段
mysql数据库-->table-->column字段
mappings:定义es当中的字段的类型,以及分词、存储、索引的特性
setting:主要用于设置es索引库的分片数和副本数
ducument:就是一个个的json字符串,es当中所有的数据都是json字符串
接近实时NRT:搜索速度快(延时通常是1秒以内)
cluster:ES本身就是分布式,一个集群由一个或多个节点组成
node:一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
shards:1)允许你水平分割/扩展你的内容容量。 2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
replicas:在分片/节点失败的情况下,提供了高可用性。
elasticsearch-head:
这个插件是es提供的一个用于图形化界面查看的一个插件工具,可以安装上这个插件之后,通过这个插件来实现我们通过浏览器查看es当中的数据
es-head插件的安装:使用js来开发,需要使用js来操作es的后台数据
js能不能够操作后台的文件
规定:js不能操作任何的文件,只是一个浏览器端的语言
js是通过一个平台包装起来了,运行在一个nodejs的平台上面,才可以去后台执行各种操作
es-head插件可以用来管理集群,包括索引库数据的查询,但是没有添加索引数据,删除索引数据的操作
kibana:数据展示的框架,同时可以通过我们的curl的命令来执行我们的es数据操作,包括增删改查
curl-XPUT http://node01:9200/blog01/?pretty curl--是kibana常用的命令,发送请求的命令 XPUT--创建一个索引库 blog01--索引库的名字 pretty--格式化,
默认创建blog01索引库,是包含5个分片和2个副本
索引管理
插入数据
curl -XPUT http://node01:9200/blog01/article/1?pretty -d '{"id": "1", "title": "What is lucene"}' blog01--索引库 article--表 1--表示数据的id,系统默认的id
在linux上插入数据
curl -XPUT http://node01:9200/blog01/article/1?pretty -d \ '{"id": "1", "title": "What is lucene"}' \ -H "Content-Type: application/json"
必须条件-H "Content-Type: application/json";此原因时由于ES增加了安全机制, 进行严格的内容类型检查,严格检查内容类型也可以作为防止跨站点请求伪造攻击的一层保护。
查询数据
curl -XGET http://node01:9200/blog01/article/1?pretty
更新文档
curl -XPUT http://node01:9200/blog01/article/1?pretty -d \ '{"id": "1", "title": " What is elasticsearch"}'
更新数据其实就是插入数据,当系统id相同时,添加数据就是更新数
搜索文档
curl -XGET "http://node01:9200/blog01/article/_search?q=title:elasticsearch&pretty"
_search表示搜索
查询结果:
took:表示获取数据的时间
hits:表示获取多少数据,所有数据都包含在里面的hits里面
删除文档
curl -XDELETE "http://node01:9200/blog01/article/1?pretty"
删除索引
curl -XDELETE http://node01:9200/blog01?pretty
ES查询
批量添加数据
例如:
POST /school/student/_bulk
往school索引库,student表,批量添加数据
1.match_all做查询
匹配所有
GET /school/student/_search?pretty
{
"query": {
"match_all": {}
}
}
2.通过关键字段进行查询
查询含有"travel"字段的
GET /school/student/_search?pretty
{
"query": {
"match": {"about": "travel"}
}
}
3.bool的复合查询
查询喜欢旅游且不是男孩的数据
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": { "match": {"about": "travel"}},
"must_not": {"match": {"sex": "boy"}}
}
}
}
4.bool的复合查询中的should
should表示可有可无的(如果should匹配到了就展示,否则就不展示)
例子:
查询喜欢旅行的,如果有男性的则显示,否则不显示
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": { "match": {"about": "travel"}},
"should": {"match": {"sex": "boy"}}
}
}
}
5.term匹配
使用term进行精确匹配(比如数字,日期,布尔值或 not_analyzed的字符串(未经分析的文本数据类型))
语法
{ "term": { "age": 20 }}
{ "term": { "date": "2018-04-01" }}
{ "term": { "sex": “boy” }}
{ "term": { "about": "trivel" }}
例子:
查询喜欢旅行的
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": { "term": {"about": "travel"}},
"should": {"term": {"sex": "boy"}}
}
}
}
6.使用terms匹配多个值
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": { "terms": {"about": ["travel","history"]}}
}
}
}
term主要是用于精确的过滤比如说:”我爱你”
在match下面匹配可以为包含:我、爱、你、我爱等等的解析器
在term语法下面就精准匹配到:”我爱你”
7.Range过滤
Range过滤允许我们按照指定的范围查找一些数据:操作范围:gt::大于,gae::大于等于,lt::小于,lte::小于等于
例子:
查找出大于20岁,小于等于25岁的学生
GET /school/student/_search?pretty
{
"query": {
"range": {
"age": {"gt":20,"lte":25}
}
}
}
8.exists和 missing过滤
exists和missing过滤可以找到文档中是否包含某个字段或者是没有某个字段
exists:包含某个字段必须展示
missing:过滤掉某个字段,不进行展示
例子:
查找字段中包含age的文档
GET /school/student/_search?pretty
{
"query": {
"exists": {
"field": "age"
}
}
}
9.bool的多条件过滤
用bool也可以像之前match一样来过滤多行条件:
must :: 多个查询条件的完全匹配,相当于 and 。
must_not :: 多个查询条件的相反匹配,相当于 not 。
should :: 至少有一个查询条件匹配, 相当于 or
例子:
过滤出about字段包含travel并且年龄大于20岁小于30岁的同学
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": [
{"term": {
"about": {
"value": "travel"
}
}},{"range": {
"age": {
"gte": 20,
"lte": 30
}
}}
]
}
}
}
10.查询与过滤条件合并
通常复杂的查询语句,我们也要配合过滤语句来实现缓存,用filter语句就可以来实现
例子:
查询出喜欢旅行的,并且年龄是20岁的文档
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": {"match": {"about": "travel"}},
"filter": [{"term":{"age": 20}}]
}
}
}
索引映射(mappings)管理
我们说ES可以看做成为一个数据,往数据库里面添加数据时要提前定义好字段类型
mappings就是定义数据字段的类型,当我们是put的方式插入数据时,
比如:id字段类型是int,但是插入的数据时"abc"则无法插入数据,如果插入的"123",则可以通过自动转换,转换成为int类型进行插入
其实添加数据时,最好带上字段类型
DELETE school
PUT school
{
"mappings": {
"logs" : {
"properties": {"messages" : {"type": "text"}}
}
}
}
添加索引:school,文档类型类logs,索引字段为message ,字段的类型为text
添加字段类型的好处:
PUT /document/article/1
{
"author" : "zhangsan",
"titleScore" : 60
}
查看索引字段类型:GET /document/article/_mapping。可以发现titleScore的类型是long。
PUT /document/article/2
{
"title" : "elasticsearchshi是是什么",
"author" : "zhangsan",
"titleScore" : 66.666
}
查看索引字段类型:GET /document/article/_mapping。可以发现titleScore的类型是long。
问题:如果后期ElaticSearch对接java的时候,将会把titleScore类型定义为Long类型
class Article{ private String title; private String author; private Long titleScore
titleScore的值,将会变为66;精度将会改变
为了解决后期我们查询时候造成数据的精度丢失,我们可提前通过mappings定义好我们每一个字段类型,不会造成精度丢失的问题
索引库(setting)的设置
settings用于设置es索引库的分片数,副本数
可以更改索引库的副本
但是分片数是在索引库创建的时候指定的,一旦指定分片数就没有办法更改
如果数量较大,查询比较频繁,分片数量尽可能创建多一点,一般分片数都是服务器个数的N倍
PUT document { "mappings": { "article" : { "properties": { "title" : {"type": "text"} , "author" : {"type": "text"} , "titleScore" : {"type": "double"} } } } }
查看settings
GET /document/_settings
修改settings
可以看到当前的副本数是1,那么为了提高容错性,我们可以把副本数改成2:
PUT /document/_settings
{
"number_of_replicas": 2
}
package com.tainjp.es; import com.alibaba.fastjson.JSONObject; import org.elasticsearch.action.index.IndexRequestBuilder; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.transport.TransportAddress; import org.elasticsearch.common.xcontent.XContentFactory; import org.elasticsearch.common.xcontent.XContentType; import org.elasticsearch.transport.client.PreBuiltTransportClient; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.InetAddress; import java.net.UnknownHostException; import java.util.HashMap; /** * @author Tianjinpen * @Create 2020-03-22 16:45 */ public class ES01 { TransportClient client=null; //1.创建索引库,通过客户端连接服务端,所以创建客户端 //获取es客户端 @Before public void initClient() throws UnknownHostException { //获取settings对象 //put方法设置es参数属性 Settings settings = Settings.builder().put().build(); //2.客户端需要连接服务端 TransportAddress transportAddress1 = new TransportAddress(InetAddress.getByName("192.168.56.100"), 9300); TransportAddress transportAddress2 = new TransportAddress(InetAddress.getByName("192.168.58.110"), 9300); TransportAddress transportAddress3 = new TransportAddress(InetAddress.getByName("192.168.58.120"), 9300); //配置构造参数 client = new PreBuiltTransportClient(settings).addTransportAddress(transportAddress1).addTransportAddress(transportAddress2).addTransportAddress(transportAddress3); } /*向索引库中添加索引 *一共四种方式 * */ @Test //第一种方式:通过json的方式 public void createIndex1(){ String json = "{" + "\"user\":\"kimchy\"," + "\"postDate\":\"2013-01-30\"," + "\"message\":\"travelying out Elasticsearch\"" + "}"; IndexRequestBuilder indexRequestBuilder = client.prepareIndex("myIndex1", "article", "1"); IndexResponse indexResponse = indexRequestBuilder.setSource(json, XContentType.JSON).get(); } @Test //第二种方式:通过mapping的方式 public void createIndex2(){ HashMap<String, String> jsonMap = new HashMap<String, String>(); jsonMap.put("name", "zhangsan"); jsonMap.put("sex", "1"); jsonMap.put("age", "18"); jsonMap.put("address", "bj"); IndexRequestBuilder indexRequestBuilder = client.prepareIndex("myIndex1", "article", "2"); IndexResponse indexResponse = indexRequestBuilder.setSource(jsonMap).get(); } @Test //第三种方式:XcontentType的方式 public void createIndex3() throws IOException { IndexResponse indexResponse = client.prepareIndex("myindex1", "article", "3") .setSource(new XContentFactory().jsonBuilder() .startObject() .field("name", "lisi") .field("age", "18") .field("sex", "0") .field("address", "bj") .endObject()) .get(); } @Test //第四种方式:Java对象转接送 public void createIndex4(){ Person person = new Person(); person.setAge(18); person.setId(20); person.setName("张三丰"); person.setAddress("武当山"); person.setEmail("zhangsanfeng@163.com"); person.setPhone("18588888888"); person.setSex(1); String json = JSONObject.toJSONString(person); client.prepareIndex("myindex1", "article", "4").setSource(json,XContentType.JSON).get(); } @After public void closeClient(){ client.close(); } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号