数据仓库
数据仓库
ETL构建企业级数据仓库流程

基本概念
业务板块:业务板块定义了数据仓库的多种命名空间,是一种系统级的概念对象。当数据的业务含义存在较大差异时,可以创建不同的业务板块,让各成员独立管理不同的业务,后续数据仓库的建设将按照业务绑卡进行划分
数据域:数据域主要用于存放统一业务板块内不同概念的指标,例如:划分出商品域,交易域,会员域等
业务过程:业务过程即业务活动中所有的事件,通常为不可拆分的事件。创建业务过程,是为了从顶层视角,贵方业务过长中事务内容的类型和唯一性
维度:维度即进行统计的对象。通常,维度是实际客观存在的实体。创建维度,即从顶层规范业务中实体的存在性和唯一性,维度即维度组合也是派生指标的统计粒度
指标:分为原子指标和派生指标。派生指标是以原子指标为基准,组装统计粒度,统计周期及业务限定而生成的
原子指标是对指标统计口径,具体算法的一个抽象。根据计算逻辑复杂性,原子指标分为:
原生的原子指标:例如支付金额
衍生原子指标:基于原子指标组合构建。例如,客单价通过支付金额除以买家数据组合而来
派生指标是业务中常用的统计指标。为了保证统计指标标准,规范,唯一性的生成
业务限定:统计的业务范围,用于筛选出符合业务规则的记录(类似于SQL中where后的条件,不包括时间区间)。
原子指标是计算逻辑的标准化定义,业务限定则是条件限定的标准化定义。
统计周期:统计的时间范围,也可以成为时间周期。例如最近一天,最近30天等(类似于SQL中where后时间条件)。
统计粒度:统计分析的对象或视角,定义数据需要汇总的程度,可以理解为聚合运算时的分组条件(类似于SQL中groupby的对象)。粒度是维度的一个组合,指明统计的范围。例如,某个指标是某个卖家在某个省份的交易额,则粒度就是卖家、省份这两个维度的组合。如果需要统计全表的数据, 则粒度为全表。在指定粒度时,需要充分考虑到业务和维度的关系。统计粒度也被称为粒度,是维度或维度组合,一般用于派生指标构建,是汇总表的唯一识别方式。
基本概念之间的关系和举例:

确定需求
业务调研
充分的业务调研和需求分析是数据仓库建设的基石,直接决定数据仓库是否建设成功。
需要相关业务人员介绍具体的业务,以便明确每个团队的分析员,运营人员的需求,沉淀出相关文档。
通过调研了解一下信息:
- 用户的组织架构和分工界面。例如:用户可能分为数据分析、运营、维护部门,各个部门对数仓需求不同,您需要对不同部门分别进行调研
- 用户的整体业务架构,各个业务模块之间的联系与信息流动的流程。梳理出整体的业务数据框架
- 各个已有的业务系统的主要功能及获取的数据
案例:
电商业务板块分为招商、供应链、营销、服务四个板块,每个板块的需求和数据应用都不同,在构建数仓之前,需要明确构建数仓服务的业务板块类型、每个板块具体满足什么业务需求。
| 公司电商 | 招商 | 供应链 | 营销 | 服务 |
| 商业目标/业务需求 | ||||
| 数据需求 | ||||
| 核心数据 | ||||
| 数据应用 |
(1)分析业务流程
业务过程可以是单个业务时间(例如交易的支付、退款),也可以是某个事件的状态(例如当前账户余额),还可以是一系列相关
事件组成的业务流程;取决于分析的是某件事过去发生的情况,当前状态或是时间流转效率。
分析业务过程的流程如下:
- 选择粒度,在业务过程事件分析中,需要判断所有分析细分的程度和范围,从而决定选择粒度
- 识别维表,选择好粒度之后,选择需要基于此粒度设计维表,包括维度属性等,用于分析是进行分组和筛选
- 最后,确定衡量的指标
案例:经过业务过程调研,电商营销业务的交易订单模块的业务流程:

(2)划分数据域
数据仓库是面向主题的应用,主要功能是将数据综合、归类并进行分析利用
数据域是指面向业务分析,将业务过程或维度进行抽象的集合,为保障整个体系的生命力,数据需要抽取提炼,
并长期维护更新,但是不轻易变动,划分数据域是满足两点:
- 能涵盖当前所有业务需求
- 能在新业务进入时,无影响的包含进已用的数据域中和扩展新的数据域
划分数据域,需要分析各个业务模块中有哪些业务活动。数据域,可以按照用户企业的部分划分,也可以按照业务过程或业务板块中的功能模块划分
案例:电商营销业务模块可以划分以下数据域,数据域中每一部分,都是根据实际业务过程进行归纳,抽象得出的
| 数据域 | 业务过程举例 |
| 会员和店铺域 | 注册、登录、装修、开店、关店 |
| 商品域 | 发布,上架,下架,重发 |
| 日志域 | 曝光、浏览,点击 |
| 交易域 | 下单,支付、发货、确认收货(交易成功) |
| 服务域 | 商品收藏,拜访,培训、优惠券领用 |
| 采购域 | 商品采购 |
(3)定义维度与构建总线矩阵
明确每个业务域中有哪些业务过程后,需要定义维度,并基于维度构建总线矩阵
定义维度
在确认收货的业务过程中,维度所依赖的业务角度主要有两个,即商品和收货地点(地域)。
- 商品角度分析:
- 商品ID(主键)
- 商品名称
- 商品交易价格
- 商品新旧程度:0全新;1闲置;2二手
- 商品类目ID
- 商品类目名称
- 品类ID
- 品类名称
- 买家ID
- 商品状态:0正常;1用户删除;2下架;3未上架
- 商品所在城市
- 商品所在省份
- 地域缴费分析
- 城市code
- 城市名称
- 省份code
- 省份名称
构建总线矩阵
总线矩阵将用于指导后续事实模型中关联维度的定义,构建数据仓库的雪花模型
需要定义数据域下的业务和维度,并明确每个业务过程和哪些维度相关
下表是A公司电商板块交易功能的总线矩阵,我们定义了购买省份、购买城市、类目ID、类目名称、品牌ID、品牌名称、商品ID、商品名称、成交金额等维度,并明确了不同业务过程包含了哪些维度。

(4)明确统计指标
指标定义注意事项
原子指标是明确的统计口径,计算逻辑(dwd明细事实表)。派生指标即常见的统计指标(dws聚合事实表)
派生指标=时间周期+业务限定+原子指标+统计粒度
真实操作过程中,DWD事实模型或DIM维度模型定义完成,才能创建原子指标。通常情况下,了解具体报表需求后,即可进行派生指标的创建。在新建派生指标前,必须完成原子指标的创建,且需要确认原子指标的来源模型中
有维度模型(关联或本身即维度模型),以保证可以设置派生指标的统计粒度。注意事项:
- 原子指标和业务限定来源于同一张维度表或事实表,且继承来源表的数据域
- 统计粒度和时间周期必选,是否选择业务限定有具体的派生指标语义决定。例如,如果支付金额为原子指标
则最近七天买家支付金额(统计粒度为买家、时间周期为最近七天)和最近七天买家支付宝支付金额(统计
粒度为买家,业务限定为支付宝,时间周期为最近其他)都可以作为派生指标
- 派生指标唯一归属一个原子指标,且继承原子指标的数据域
根据业务需求确定指标
案例:数据需求为最近一天厨具类目的商品在各省的销售总额,该类目销售额top10的商品名称,各省购买力分布(人均消费额)等
需要用到对应事实模型的度量--商品的销售金额,根据业务需求,定义出:
- 原子指标:商品成功交易的金额总和
- 派生指标:最近一天全省厨具类目各商品的销售总额
最近一天全省厨具类目的人均消费额(消费总额除以人数)
梳理指标体系:
根据公司实际指标体系,简单的做下总结
- 确定数据来源 如哪些业务系统,订单、商品、库存、供应商、合作商、采购、营建、资产、运营等系统。
- 确定各系统的数据体系 如现制商品数、外购商品数、等效商品数、客均商品数、响应时长、超时时长、外送时长、准时率等。
- 数据域划分 如用户域(用户注册、用户消费、用户留存)、流量域(用户下载、用户启动、用户使用(页面访问、下单、分享、点击)、用户下单)、订单域(订单、订单商品、订单制作、订单配送、订单评价)、
商品域(商品SKU、商品类目、商品配方)、结算域(收入、成本、增值税)、门店域(门店基础、门店人员、门店地址)、供应链域(门店库存、仓库库存、损耗)
数据仓库--业务流程
确定主题?
既然是仓库,就应该“按类”存储;按主题分类,确定好主题边界合理划分主题
比如财务为主题时,就要定义好边界,不能掺杂人力的数据
(1)划分主题域:
主题就是指我们要分析的具体方面;一是分析角度(维度),二是要分析具体量度
概念逻辑设计:业务模型
逻辑模型设计:抽象了主题和表的属性
物理模型:落地到数据库
数据仓库--数据来源
数据库、FTP/HTTP、日志、其他文档
数据仓库--数据采集
数据源分为数据库,日志,平面文件
MySQL:使用Sqoop,DataX
Datax:Ali开源的,基于多线程级别的并行实现离线,异构平台同步工具,能够快速实现数据异构数据源的离线同步
流程:SourceData--Reader--Channel--Writer--TargetData
Sqoop:关系型数据与HDFS之间数据同步工具,多数使用sqoop1
Sqoop作为一个客户端,通过参数转化成MapReduce,提交到yarn集群上,由nodemanager通信采集;
采集数据源,采集只有map过程,指定map数量为4,相对指定4个程序读取数据源
问题:如果公司网络不是普遍连接,可能会使yarn的节点与数据库连接不上,导致不能导入
Sqoop1与Sqoop2:
Sqoop1:
仅有一个客户端,架构简单明了,部署即用,使用门槛比较低;但是耦合性强,用户密码暴露导致不安全
Sqoop2:
服务端部署,运行;提供cli,restapi,webUI等入口,concetor集中管理,RDBMS账号控制更安全,但Sqoop2仅负责数据的读写操作,部署相对负责
Log日志:使用Flume
包含三部分:
Source:负责根据配置策略,捕获event并投递到Channel中
Sink:从Channel中消费数据,投递到下一个目标端
Channel:一个暂缓event的数据通道
使用场景:
1.日志归集:将不日志合并
2.load balance
3.日志分流or多路存储
4.整合kafka(能够保持数据一致性,将所有数据落地kafka,如果有实时和离线可以保证订阅数据一致)
5.整合SparkStreaming
数据仓库--数仓分层
维度表设计原则
- 尽可能生成丰富的维度属性。
例如电商公司的商品维度可能有近百个维度属性,为下游的数据统计、分析、探查提供了良好的基础。
- 尽可能多的给出包含一些富有意义的文字性描述。
属性不应该是编码,而应该是真正的文字。在阿里巴巴维度建模中,通常是编码和文字同时存在,例如商品维度中的商品ID和商品标题、类目ID和类目名称等。ID通常用于不同表之间的关联,而名称通常用于报表标签。
- 区分数值型属性和事实。
数值型字段是作为事实还是维度属性,可以根据字段的常用用途区分。例如,若用于查询约束条件或分组统计,则是作为维度属性;若用于参与度量的计算,则是作为事实。
- 尽量沉淀出通用的维度属性。
- 通过逻辑处理得到维度属性。
- 通过多表关联得到维度属性。
- 通过单表的不同字段混合处理得到维度属性。
- 通过对单表的某个字段进行解析得到维度属性。
事实表设计原则
- 尽可能包含所有与业务过程相关的事实。
设计事实表的目的是度量业务过程,所以分析哪些事实与业务过程有关,是事实表设计中至关重要的。在事实表中应该尽量包含所有与业务过程相关的事实,即使存在冗余,但是因为事实通常为数字型,带来的存储开销不会很大。
- 只选择与业务过程相关的事实。
在选择事实时应该注意,只选择与业务过程有关的事实。例如,A公司的订单交易业务流程中,在设计下单这个业务过程的事实表时,不能包含支付金额这个表示支付业务过程的事实。
- 在选择维度和事实之前,必须先声明粒度。
粒度(数据行数的最小单位,非统计粒度)的声明是事实表设计中不可忽视的重要一步。粒度用于确定事实表中一行所表示业务的细节层次,决定了维度模型的扩展性。在选择维度和事实之前,必须先声明粒度,且每个维度和事实必须与所定义的粒度保持一致。在事实表中,通常通过业务描述来表述粒度并定义事实表主键,但对于聚集性事实表的粒度描述(例如存在下单、支付等多个事务),可以基于多个字段拼接,形成新的字段作为事实表主键,也可以不定义主键,这样一行记录即最小粒度。
- 在同一个事实表中,不能包含多种不同粒度的事实。
事实表中所有事实的粒度需要与表声明的粒度保持一致,在同一个事实表中不能有多种不同粒度的事实。
- 事实的单位要保持一致。
在同一个事实表中,事实的单位应该保持一致。例如,原订单金额、 订单优惠金额、订单运费金额这三个事实,应该采用一致的计量单位,例如统一为元,以方便使用。
-
汇总表设计原则
聚集是指针对原始明细粒度的数据进行汇总。DWS汇总数据层是面向分析对象的主题聚集建模。在本教程中,最终的分析目标为:最近一天某个类目(例如,厨具)商品在各省的销售总额、该类目销售额Top10的商品名称、各省用户购买力分布。因此,我们可以以最终交易成功的商品、类目、买家等角度对最近一天的数据进行汇总。数据聚集的注意事项如下:- 聚集是不跨越事实的。聚集是针对原始星形模型进行的汇总。为获取和查询与原始模型一致的结果,聚集的维度和度量必须与原始模型保持一致,因此聚集是不跨越事实的,所以原子指标只能基于一张事实表定义,但是支持原子指标组合为衍生原子指标。
- 聚集会带来查询性能的提升,但聚集也会增加ETL维护的难度。当子类目对应的一级类目发生变更时,先前存在的、已经被汇总到聚集表中的数据需要被重新调整。
此外,进行DWS层设计时还需遵循数据公用性原则。数据公用性:需考虑汇总的聚集是否可以提供给第三方使用。您可以思考,基于某个维度的聚集是否经常用于数据分析中。如果答案是肯定的,就有必要把明细数据经过汇总沉淀到聚集表中。
数据仓库--模型设计
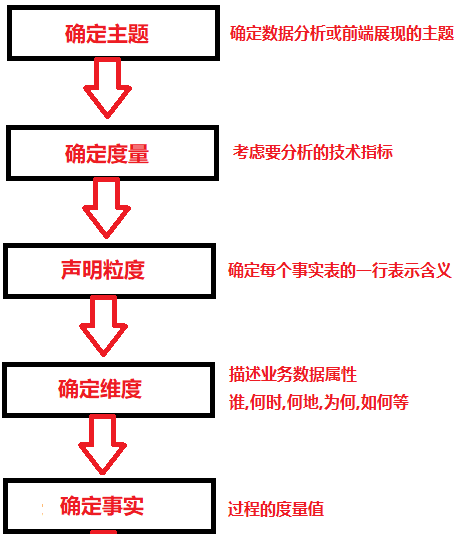
- 数据仓库整体采用Kimball维度建模的方式,主要有两点:
- 维度建模能够快速响应业务需求的变化
- 可以采用增量的方式进行开发,按数据域进行增量开发
- 维度表设计规范
- 每个拉链表生成唯一的代理健,代理健以_key结尾
- 每个维表生成一个特殊行,避免事实表数据丢失以及处理迟到维情况
- 尽可能的宽(反规范化)、包括可能的维度属性,减少关联并且保证一致性
- 维表属性划分按照自然属性进行划分,即属性不需要通过事实表进行建立关系的应放在同一个维表中
- 事实表设计规范
- 将每个业务过程用独立的事实表来存放
- 将常用的维度采用退化维保留在事实表中
- 尽可能保留最细粒度的事实数据
- 尽量将不可加事实拆分成可加事实事实表划分依据:
- 事实表划分依据
- 事实是否同时发生
- 事实表的粒度是否相同
经典数据仓库模型
数仓建模的目标:
访问性能:能够快速查询所需的数据,减少数据I/O
数据成本:减少不必要的数据冗余,实现计算结果数据复用,降低大数据系统中存储成本和计算成本
使用效率:改善用户应用体验,提高使用数据的效率
数据质量:改善数据统计口径的不一致性,减少数据计算错误的可能性,提供高质量的,一致的数据访问平台
一、实体关系(ER)模型
将事物抽象成"实体"
实体:客观存在的事物,商品,人,物等
属性:对主题的修饰,比如商品的名称,颜色,尺寸
关系:现实的物理事件是依附于实体的,商品入库事件,依附实体的商品、货位,就会有“库存”的属性产生;用户购买商品,依附实体用户,商品,就会有“数量”,“金额”等属性产生
购物过程:用户,商品,商家都是实体;用户购物的过程三方形成关系,实体自身带有属性
在设计表时,实体会形成表,而关系也形成表*(比如购买商品,用户和商家形成订单表,而购买件数,金额就行形成关系也会生成表)
实体之间的关系:
1:1的关系
1:n的关系
n:m的关系
针对商品入库,ER图构建
(1)抽象出实体:商品、货位
(2)实体之间的关系:一个货位可以存储多个商品,一个商品仅能放在一个货位上
(3)实体属性,关系属性:商品:ID,名称,颜色;货位:位置,容量
入库关系:库存
ER实体模型
将实体抽象出来:商品,货位
关系也要抽象表:库存
相应的实体也具有相关属性

Bill Inmon:自上而下建设数据仓库,数据集市的信息来源于数据仓库;在数据仓库中,信息存储符合三范式
第一范式:字段都应该是原子性的
第二范式:实体的属性完全依赖于主关键字,不能存在仅依赖主关键字一部分的属性
拆分后分数值依赖于课程这个主键
| 学生ID | 所属系 | 系主任 | 所修课程 | 分数 |
| 001 | 物理系 | 张三 | 0001 | 100 |
| 001 | 物理系 | 张三 | 0002 | 90 |
| 学生ID | 所属系 | 系主任 | 学生ID | 所修课程 | 分数 | ||
| 001 | 物理系 | 张三 | 001 | 0001 | 100 | ||
| 001 | 0002 | 90 |
第三范式:任何非主属性不依赖于其他非主属性(传递ID)
商品颜色对应了商品ID有对应了ID,商品ID又对应了ID,形成传递
| ID | 商品ID | 商品颜色 | 商家 | 用户ID |
| 001 | 001001 | 白色 | 安踏 | 000001 |
| ID | 商品ID | 商家 | 用户id | 商品id | 商品颜色 | 尺寸 | ||
| 001 | 001001 | 安踏 | 000001 | 001001 | 百色 | 40码 |
E-R实体关系模型应用场景:
ER模型是数据库设计的理论基础;
数据仓库底层ods,dwd也多可以采用ER关系模型设计
二、维度模型
事实表和维度的分界线:
用于度量的事实表
事实定义:表示某个业务度量
存储什么内容:组织机构业务过程事件的性能度量结果。
存储原则:将来源于同一个业务过程的底层度量结果存储于一个维度模型中。
为什么这么存储:因为数据量巨大。
事实有哪些类型:可加,半可加,不可加
事实表的粒度的类型:事务,周期性,累计快照
注意事项:
1,允许多个组织的业务用户访问同一个单一的集中式数据仓库,确保他们能在整个企业中使用一致的数据。
2,物理世界的每个度量事件对应的事实表行具有一对一的关系。每行的数据是一个特定级别的细节(粒度)数据
3,同一个事实表的度量行比具有相同的粒度
用于描述环境的维度表
存储的内容:包含于业务过程度量事件有关的文本环境
维度表的语意:“谁(who),什么(what),哪里(where),何时(when),为什么(why),如何(how)”
维度表的特点:通常有多列(多个属性),和事实表比较 维度表通常小的多,单一主键
作用:是用于和事实表连接操作时实现参照完整性的基础,可作为查询约束、分组、报表标识。
注意:
1,尽量减少在维度表中使用代码,将代码替换为详细的文本属性。尽量减少他们对代码转换注释的依赖。
2,为维度属性提供详细的业务术语耗费的精力越多,效果越好,强大的维度属性带来的回报是健壮的分片-分块能力。
3,连续值数字基本上可以认为属于事实,来自于不太大列表的离散数字基本可以认为是维度属性
4,维度表可以冗余,不一定要满足第三范式,通常是非规范化的。对于维度表的存储空间的权衡 往往 关注 简单性和可访问性;是否方便使用,是否能提高查询性能。
以日常工作量为例
工作量的属性:人员,工作日期,上班时长,加班时长,工作内容,是否外勤
上班时长,加班时长是主干;以工作量为主题的主要内容
人员,日期,是否外勤可以本分类的为单独列出来,称为维度表
事实表可以设计成如下
WorkDate EmployeeID,WorkTypeID,Islegwork,Content,
而时间,员工,工作类型,是否外勤则归为维度表。
Ralph Kimball:自下而上建设数据仓库,数据仓库是企业内所有数据集市的集合,信息总是被存储在多维模型中
(公司是从小到大的,先构建一个面向订单的主题,再构建一个面向仓库的主题,而主题按照维度建模,所有主题最终汇总形成数据仓库)
第一种方式将所有独立系统数据整合很难和容易遗漏;第二种方式划分主题,围绕这个主题创建一个集市,在创建另一个主题时,再构建集市,问题主题设置过多集市就会出现一个字段有不同的表示
最终将数据仓库划分不同的层次。(ODS,DW,DM)
维度建模将数据仓库中的表划分为事实表和维度表两种类型
事实表:在ER模型中抽取了有实体,关系,属性三种类型,在现实世界中,每一个操作性事件,基本都是发生在实体间;伴随着这种操作事件的发生,会产生度量的值,而这个过程就产生了一个事实表,存储了每一个可度量的事件。
电商场景:一次购买事件,设计主体包括客户,商品,商家;产生的可度量值包括商品金额,数量,件数等
用于度量的事实表
存储内容:业务过程事件的性能度量结果
存储原则:来源于同一业务过程的底层度量结果存储于同一维度模型
事实表类型:可加,半可加,不可加
事实表粒度:通用,周期性,累积快照
注意事项:
1,允许多个业务用户访问同一个单一的集中式数据仓库,确保使用数据的一致性
2,物理世界的每个度量事件对应的事实表行具有一对一的关系。每行的数据是一个特定级别的细节(粒度)数据
3,同一个事实表的度量行比具有相同的粒度
维度表:看待事物的角度。比如从颜色、尺寸的角度来比较手机的外观,从CPU、内存等比较手机性能
维度表一般为单一主键,在ER模型中,主体为客观存在的事物,会带有自己的描述性属性,属性一般为文本性,描述性的;这些描述性被称为维度
比如商品:单一主键:商品ID,属性包括产地,颜色,材质,尺寸,单价等,但并非属性一定是文本,比如单价,尺寸,均为数值型描述的,日常主要的维度抽象包括:时间维度表,地域维度表等
维度表之间还可以有层级关系:dim_乡镇~dim_县~dim_市~dim_省
用于描述环境的维度表
存储内容:业务过程度量事件有关的文本环境
维度表的语意:“谁(who),什么(what),哪里(where),何时(when),为什么(why),如何(how)”
维表特点:通常有多列(多个属性),单一主键,利用关键字通过事实表外键约束于事实表的某一行
注意:
1,尽量减少在维度表中使用代码,将代码替换为详细的文本属性。尽量减少他们对代码转换注释的依赖。
2,为维度属性提供详细的业务术语耗费的精力越多,效果越好,强大的维度属性带来的回报是健壮的分片-分块能力。
3,连续值数字基本上可以认为属于事实,来自于不太大列表的离散数字基本可以认为是维度属性
4,维度表可以冗余,不一定要满足第三范式,通常是非规范化的。对于维度表的存储空间的权衡 往往 关注 简单性和可访问性;是否方便使用,是否能提高查询性能。
案例 以购物订单为例,以维度建模的方式设计该模型 涉及到的实时表为订单表,订单明细表,维度包括商品维度,用户维度,商家维度,区域维度,时间维度 商品维度:商品ID,商品名称,商品种类,单价,产地等 用户维度:用户ID,姓名,性别,年龄,常住地,职业,学历等 时间维度:日期ID,日期,周几,上/中/下旬,是否周末,是否假期等 订单中包含的度量:商品件数,总金额,总减免 描述性属性:下单时间,结算时间,订单状态等 订单明细包含度量:商品ID,件数,单价,减免金额 描述性属性:入购物车时间,状态

星型/雪花模型对比:
冗余:雪花模型符合业务逻辑设计,采用#NF设计,有效降低数据冗余:星型模型的维度表设计不符合3NF,犯规范化,维度表之间不会直接关联,牺牲部分存储空间
性能:雪花模型由于存在维度间的关联,采用3NF降低冗余,通常在使用过程中,需要连接更多维度表,导致性能降低;星型模型反3NF,采用降维的操作将维度整合,以存储空间为代价有效降低维度表连接数,性能较雪花模型高。
ETL:雪花模型符合业务ER模型设计原则,在ETL过程中相对简单,但是由于附属模型限制,ETL任务并行较低;星型模型在设计维度表时反范式设计,所以在ETL过程中整合业务数据到维度表有一定难度,但由于避免附属维度,可并行化处理
问题:数据仓库,不针对某一个分析主题,而是有多个分析主题,即多个事实表,维度表怎样设计?
多个事实表,维度共用
问题:即使同一分析主题,也可能存在多个事实表,维度表如何设计,多个时间维度?
维度同样共用
维度表设计:
1.代理键:维度表中必须有一个能够唯一表示一行记录的列,通过该列维护维度表与事实表之间的关系,一般在维度表中业务主键符合条件可以当做维度主键
问题:当整合多个数据源的维度时,不同数据源的业务主键重复怎么办?
维护一个与系统业务不相关的唯一标识的自增代理键(通常是数值型,自增);

hive中如何实现代理键自增id?
(1)使用UDF(2)使用MySQL语句
思路:获取上一日最大的id值,在最大id上实现新增数据的自增
全量数据 s1,s2----dim_good1 增量数据 s1,s2----tmp_inc --query '....s1 where create_time>'2020-02-01' --query '....s2 where create_time>'2020-02-01'' 代理键 pid insert overwrite table dim_good1 partition(dt='2020-02-01') select t2*,
(对新增id进行排序再加上上一日最大id) row_number() over(order by id) + t1.max_id as gid from tmp_inc as t2 cross join
(获取上一日最大id) (select coalesce(max(gid),0) as max_id from dim_good1 where dt='2020-01-31') t1 union all select * from dim_good1 where dt='2020-01-31'
2.稳定维度表(不需要进行分区)
部分维度表的维度时在维度表产生后,属性是稳定的,无变化的;比如时间维度,区域维度等,针对这种维度,设计维度表时候,仅需要完整的数据,不需要天的快照数据,因为当前数据状态既是历史数据状态
3.缓慢渐变维度
维度数据会随着时间发生变化,变化速度比较缓慢,这种维度数据通常称作为缓慢渐变维;由于数据仓库需要追溯历史变化,尤其是一些重要的数据,所以历史状态也需要采取一定的措施进行保存
- 每天保存当前数据的全量快照数据,该方案适合数量较小的维度,使用简单的方式保存历史状态
- 在维度表中添加关键属性值的历史字段,仅保留上一个状态
| id | name | dept | last_dept |
| 001 | 小王 | dp1 | dp2 |
拉链表
当维度数据发生变化时,将旧数据置为失效,将更改后的数据当做新的记录插入到维度表中,并开始生效,这样能够记录数据在某种粒度上的变化历史
| id | name | dept | start_date | end_date |
| 1 | 小王 | dp1 | 2020-01-29 | 2020-01-31 |
| 1 | 小王 | dp2 | 2020-02-01 | 9999-12-31 |
问题:拉链表怎么和事实表关联?
添加代理键(如何不添加uid,id都是1,按部门统计时就会出现2X2的现象)

(可以统计出同一个用户在不同时期所在部门,如果不用拉链表,保留的只是最新的数据,那么按部门统计时使用最新的数据,没有之前的数据)
问题:事实表中id变化为uid,事实表来源于业务表,代理键和业务本身没有关系,那么怎么在实时表中装载代理键?
事实表中历史的用户维度id不会发生变化,所以事实表的代理键仅发生在新增数据上
--事实表装载代理键-- fact_order:oid(订单id) uid(用户id,当成代理键) tm_id ... dim_user:uid(创建自增id) id(业务id) name dapt start_time end_date
(将维度表的uid装载到事实表的uid) order:oid id create_time update_time 筛选出昨天新增数据
--query ' order where create_time>=2020-02-01' --order_inc
insert overwrite table fact_oder partition(dt='...') select tmp.* from (select t1.* ,t2.uid from order_inc as t1(昨天采集的数据) join dim_user as t2 on t1.id=t2.id)tmp(关联后有多条记录) where create_time>=start_date and create_tim<=end_date(维度的生效时间)
union all
select * from fact_order
问题:如何取2020-02-05的数据?
select * from use where start_date<=2020-02-05 and end_date>=2020-02-05
代理键是维度建模中极力推荐的方式,它的应用能有效的隔离源端变化带来的数仓结构不稳定问题,同时也能提高数据检索能力
但是,代理键维护代价非常高,尤其是数据装载过程中,对事实表带来了较大的影响,在基于hive的数据建设影响更加严重,比如代理将成本
事实表中关联键的转载,不支持非等值关联问题带来etl过程更加复杂(对于维度时尽量不是用拉链表)
故,在大数据体系下,谨慎使用代理键,同时对于缓慢渐变维度场景,可以考虑空间换时间,每天保留全量快照;但是这样会带来存储成本,根据实际情况衡量
维度表拆分、合并
- 不同的主题同样的维度关注点是不一样的,不同的主题共用一个维度表保证数据一致性,但是可以将维度提取出一部分作为维度子表供应一个主题
比如京东自营产品和其他商铺:可以基于商家维度进一步拆分将特有属性列拆分出来

- 固有信息和非固有信息拆分:
姓名,性别,身份证,出生年月日(不要使用年龄,因为年龄是不断变化的);
常住地,手机号等非固有在一个扩展表中(除非维度变化非常频繁,不推荐使用;把动静数据放在一起)
案例:
针对公司员工进行维度设计:
公司包括销售体系,技术体系,行政体系,物流体系等;很多部门都很关注公司员工信息,比如物流体系分析人员发货错误率,人员效率;
财务部门关注员工薪资,待遇以便分析财务预算等,HR关注薪资待遇以便评估公司人才计划等
从另一个角度看,销售体系员工有相对应的销售区域划分,技术体系员工有相应的技术方向等
问题:不同主题的用户维度是对不齐的,比如物流人员就没有技术方面;技术人员没有销售大区。
方案1:针对不同的主题,建一个基础维度表,将所有信息写入到维度表中(针对不同的主题,维度表的字段可能为空);如果针对某个主题,可以
在提取一个子维度表(推荐)

方案2:将所有主题共有的信息提取出来作为一个共用维度表,在针对各个主题特有信息做一个特有维度表

事实表设计:包含业务表本身的数据,业务表的度量
一般事实表中包含两部分信息:维度、度量,度量即为事实;但是有些特殊情况下,事实表中无度量信息,只是记录一个实际业务动作。
明细事实表:
事实表有粒度大小之分,基于数据仓库层次架构,明细事实表一般存在于dwd层(维度规范化),该层事实表表设计不进行聚合,汇总动作,仅做数据规范化,数据降维动作,同时数据保持业务事务粒度,确保数据信息无丢失
数据降维:为了提高模型易用性,将常规维度表中的常用属行数据冗余到相应的事实表中,从而在使用的时候避免维度表关联的方式,即为数据降维(将常用的维度表字段拿到事实表中),也就是有些属性不用单独再去创建维度表,可以降维到事实表中

设计事实表的主要业务依据是业务过程,每个业务动作事件,都可以作为一个事实,那么在一个订单处理过程中,会有多个动作,这个过程中事实表怎样设计?
方案1:单事件事实表
对于每一个业务动作事件,设计一个事实表,仅记录该事件的事实以及状态(每产生一个动作就是一个事实表)
单事件事实表更方便跟踪业务流程细节数据,针对特殊业务场景比较方便和灵活,数据处理上也更加灵活;
不方便的地方就是数仓中需要管理的太多的事实表,同时跟踪业务流转不够直观
方案2:流程事实表
对于一个业务流程主体,设计一个事实表,跟踪整个流程的事实以及状态流转(比如订单从下单,到最后的支付完成这个状态)
流程事实表:能过直观的跟踪业务流转和当前状态,流程事实表中,方便大部分的通用分析应用场景,由于和业务的数据模型设计思路一致,
也是目前最常用的事实表设计,但是细节数据跟踪不到位,特殊场景的分析不够灵活
场景案例: 出行领域,用户下单打车,改订单的整个流程: 用户下单--司机接单--司机做单--乘客支付--评价、投诉 如何设计明细事实表?
事务性事实表:(很难看出数据流转的过程,能更好的分析数据)

流程事实表:

事实表存储:
增量存储:
即每周期仅处理增量部分数据,针对状态无变化的数据比较合适
全量快照:
状态有变化,但每天保存当天的快照数据,对于数据量在可控范围内的情况可以采用保存策略:
- 如果存储空间和成本可接受,完整存储,确保能够追溯到历史每天数据状态
- 存储空间有限,考虑移动到历史快照数据到冷盘,需要使用时可恢复
- 数据历史状态数据无太大价值,可以考虑部分删除,比如保留每月最后一天的快照数据
拉链表:
数据量大,但缓慢变化,需要跟踪历史状态,和缓慢渐变维度类似
案例:信用卡场景 用户的信用额度,已用额度存在缓慢的变化,有需要跟踪变化的记录,设计相关事实表 源数据包括用户id,卡id,额度,已用额度,剩余额度,创建时间,更新时间 设计拉链表: credit_aount:cart_id,use_id,amount,used_amount,create_time,update_time 1,采集数据:s_credit_amount(变化的数据) --query 'select * from where update_time>=2020-02-01' 2,dwd拉链表:d_credit_amount_1 --2020-01-31
(拉链表的使用,数据状态发生变化后,之前日期的数据使之失效;变化后的数据是最新的数据) drop table if exists tmp_credit_amount; create table tmp_credit_amount as select tmp.* from (select t1.card_id, t1.user_id, t1.amount, t1.used_amount, t1.create_time, t1.start_date (case when t2.card_id is not null(状态发生改变) and t1.end_date>'2020-02-01' then '2020-01-31'(状态改变多次,去最后一次)
else t1.end_date end ) as end_date from d_credit_amount_1 as t1 left join s_credit_amount(发生变化的表) as t2
on t1.credit=t2.credit(以上是发生变化的数据失效) union all t1.card_id, t1.user_id, t1.amount, t1.used_amount, t1.create_time, '2020-02-01' as start_date, '9999-12-31' as end_date from s_credit_amount as t1) tmp insert overwrite table d_credit_amount_1 select * from tmp_credit_amout
--基于全量快照数据做拉链
(某些数据源可能没有create_time和update_time)
dwd:d_credit_amount_d(全量快照)
cart_id,use_id,amount,used_amount,create_time
根据全量快照表构建拉链表d_credit_amount_1
1,获取上日发生变化的数据(可使用md5值)
select t1.*
from
(select
t1.card_id,
t1.user_id,
t1.amount,
t1.used_amount,
t1.create_time,
md5(concat(card_id,user_id,amount,user_amount,create_time)) as md5_flag
from d_credit_amount_d dt='2020-02-01') t1(以上发生变化的数据)
left join
(select
t2.card_id,
t2.user_id,
t2.amount,
t2.used_amount,
t2.create_time,
md5(concat(card_id,user_id,amount,user_amount,create_time)) as md5_flag
from d_credit_amount_d dt='2020-01-31') t2(以上是之前的数据)
on t1.card_id=t2.card_id
where t1.md5!=t2.md5(新产生的数据不等于原来的数据,说明数据变化了) or t2.card_id is null(判断空值);
聚合事实表:
相对于明细事实表,聚合事实表通常是在明细事实表基础上,按照一定的粒度粗细进行汇总、聚合操作,
它的粒度较明细数据粒度粗,同时伴随这细节信息的丢失(比如:订单金额时,可能下单时间就会丢掉);
在数仓层次结构中,通常位于dws层,一般作为通用汇总层数据存在,也可以是更高粒度的指标数据,
但是同一个事实表中,尽可能保证事实粒度一致
- 日粒度(日报)
- 周期性积累(包含周、月、年)
- 历史积累(是根据之前的数据求出来的,比如:累积金额,最近的下单时间)
- 可累加事实:在一定粒度范围内,可累加的事实度量,比如:订单金额,订单数
- 不可累加事实:在更高粒度上不可累加的事实,比如:通过率,转化率,下单用户数
(对于不可累加的事实表,通常拆分设计,通过率=通过数/申请数;有细粒度数据去重计算而来的事实,正常储存,
但是更粗粒度累积是不可直接使用,比如一天的通过率是20%,七天不能直接相加)
注意:在同一个事实表中要保持数据粒度的一致性(虽然可以算,但是不推荐)
聚合事实表存储
在数据仓库中,按照日期范围的不同,通常包括以下类别的聚合事实表;
- 公共维度层-通用汇总(封装底层计算逻辑,避免上次接触明细)
应对大部分可预期、常规的数据需求,通常针对模式相对稳定的分析,BI指标计算、特征提取等场景,封装部分业务处理,计算逻辑,尽量避免用户直接使用底层明细数据,该层用到的数据范围比较广泛
- 日粒度
主要应对模式稳定的分析,BI日报,特征提取场景,同时日粒度也为后续积累计算提供粗粒度的底层,数据范围一般我上一日的数据
- 周期性积累
主要应对明确的周期性分析,BI周期性报表,数据范围一般在某一周期内(一般来自于日粒度,公共维度层)
- 历史累积
历史以来某一特定数据的累积,通常在用户画像,经营分析,特征提取当面场景较多,书籍数据范围比较广泛,通常是计算耗时较长的一部分,比如某门店累积营业额(非可度量,描述性)
订单粒度(通用汇总:就是在订单的明细表进行轻度计算)
订单id,用户id,司机id,
性别,年龄,下单时间(维度退化),
用户等待接单时长,用户等待司机时长,预估时长,预估路程,实际时长,实际路程(指标)
应付金额,实付金额,优惠券减免,新用户减免(属于支付系统事实表,在通用层尽量汇总全面)
用户粒度(通用汇总)
用户id
性别,年龄(维度退化)
下单笔数,接单笔数,主动取消笔数,被动取消笔数,行程(指标)
优惠,消极评价笔数,中性评价笔数,积极评级笔数(属于支付系统事实表,在通用层尽量汇总全面)
司机粒度(通用汇总)
司机id,
品牌,车系(维度退化)
出车时长,做单时长,行驶里程,做单金额,奖励金额(指标)
主动取消笔数,被动取消笔数(属于订单系统事实表,在通用层尽量汇总全面)
日粒度数据(交易相关日报,用到时间、区域等维度表)
时间id,地域id
下档用户数,下单数,支付用户数,支付单数,应收金额,实付金额,优惠金额(指标;根据实际业务需求划分)
累积粒度
注册用户数,下单用户数,首次下单用户数,取消订单用户数,支付用户数,被投诉用户数

1.3数据仓库的开发
背景
互联网信用贷款行业,主要业务流程
用户注册后,通过一系列的信息认证,信息认证成功后,可以申请授信,然后有风控策略、模型给出信用评定,同时给予相应额度
用户获取额度后可以在平台发起贷款,贷款也要再次通多相应的风控模型,评级通过后可以放宽用户收到放款后,需要分期还款,每期归还一定的额度
1.3.1梳理业务流程
(1)梳理业务流

(2)梳理数据流
比如:用户注册提供了什么信息(姓名,性别,手机号)
(3)
数据类型,存储介质
(4)
需求--功能性需求,非功能性需求
- 梳理出ER实体关系模型

(5)数据采集方案
- 表的数据量、每日增量、create_time和update_time,自增id,源表索引
条件1:自增id,全量抽取(--split by id -- m4,抽取策略是取id最大值与最小值/4)
条件2:create_time,增量抽取(--split by create_time -- m4,这时不要指定id;避免数据倾斜)
- 确定使用增量还是全量
用户、订单等变化频率不大,推荐使用全量采集
申请授信表变化量大的表,增量采集
(6)数据仓库模型设计
- 抽象维度表

- 根据维度表和ER实体表创建事实明细表

- 聚合事实模型设计(通用汇总层)
(7)数据仓库ETL落地
1.3.1数据开发步骤
- 确定统计那些指标(根据业务需求)
- 需求确定 比如:pv uv topn
- 建模确定表结构create table t1 ( pv int , uv int ,topn string)
- 实现方案确定(将确定的指标封装进去即可,之后通过大量的逻辑运算得到t表即可)
- 数据开发过程
- 表落地
- 写sql语句实现业务逻辑
- 部署代码
- 数据测试
- 试运行和上线
1.3.2案例步骤:
用户画像开发--客户基本属性表
--用户画像-客户基本属性模型表 create database if not exists gdm; create table if not exists gdm.itcast_gdm_user_basic( user_id string ,--用户ID user_name string ,--用户登陆名 user_sex string ,--用户性别 user_birthday string ,--用户生日 user_age bigint ,--用户年龄 hex_phone string ,--手机号 fore_phone string ,--手机前3位 dw_date timestamp ) partitioned by (dt string); #*************************** --客户基本属性模型表BDM层 --一般从mysql直接抽取过来,不做任何处理 create database if not exists bdm; create external table if not exists bdm.itcast_bdm_user( user_id string ,--用户ID user_name string ,--用户登陆名 user_sex string ,--用户性别 user_birthday string ,--用户生日 hex_phone string ,--手机号 ) partitioned by (dt string) row format delimited fields terminated by ','; alter table itcast_bdm_user add partition (dt='2017-01-01') location '/business/itcast_bdm_user/2017-01-01'; --客户基本属性表FDM层 --我们通过对BDM层预处理来构建FDM层,比如年龄:我们在BDM只有个生日,我们可以通过生日得到年龄字段或是对手机号进行切割得到前三位 create database if not exists fdm; create table if not exists fdm.itcast_fdm_user_wide( user_id string ,--用户ID user_name string ,--用户登陆名 user_sex string ,--用户性别 user_birthday string ,--用户生日 user_age bigint ,--用户年龄 hex_phone string ,--手机号 fore_phone string ,--手机前3位 dw_date timestamp ) partitioned by (dt string); --加载数据 insert overwrite table fdm.itcast_fdm_user_wide partition(dt='2017-01-01') select t.user_id, t.user_name, t.user_sex, t.user_birthday, (year(current_date)-(year(birthday))) as age, t.hex_phone, substring(t.hex_phone,3) as fore_phone, from_unixtime(unix_timestamp()) dw_date from bdm.itcast_bdm_user t where dt='2017-01-01'; --用户画像-客户基本属性模型表GDM层 create database if not exists gdm; create table if not exists gdm.itcast_gdm_user_basic( user_id string ,--用户ID user_name string ,--用户登陆名 user_sex string ,--用户性别 user_birthday string ,--用户生日 user_age bigint ,--用户年龄 hex_phone string ,--手机号 fore_phone string ,--手机前3位 dw_date timestamp ) partitioned by (dt string); --加载数据 insert overwrite table gdm.itcast_gdm_user_basic partition(dt='2017-01-01') select t.user_id, t.user_name, t.user_sex, t.user_birthday, t.user_age, t.hex_phone, t.fore_phone, from_unixtime(unix_timestamp()) dw_date from (select * from fdm.itcast_fdm_user_wide where dt='2017-01-01') t;
演示模型表开发脚本: ###################### #名称:客户基本属性模型表 # itcast_gdm_user_basic.sh ###################### #!/bin/sh #获取昨天时间 yesterday=`date -d '-1 day' "+%Y-%m-%d"` #指定跑哪一天数据 if [ $1 ];then yesterday=$1 fi SPARK_SUBMIT_INFO="/export/servers/spark/bin/spark-sql --master spark://node1:7077 --executor-memory 1g --total-executor-cores 2 --conf spark.sql.warehouse.dir=hdfs://node1:9000/user/hive/warehouse" SOURCE_DATA="/root/source_data" SQL_BDM="create database if not exists bdm; create external table if not exists bdm.itcast_bdm_user( user_id string ,--用户ID user_name string ,--用户登陆名 user_sex string ,--用户性别 user_birthday string ,--用户生日 hex_phone string ,--手机号 ) partitioned by (dt string) row format delimited fields terminated by ',' location '/business/bdm/itcast_bdm_user' ; alter table bdm.itcast_bdm_user add partition (dt='$yesterday');" SQL_FDM="create database if not exists fdm; create table if not exists fdm.itcast_fdm_user_wide( user_id string ,--用户ID user_name string ,--用户登陆名 user_sex string ,--用户性别 user_birthday string ,--用户生日 user_age bigint ,--用户年龄 hex_phone string ,--手机号 fore_phone string ,--手机前3位 dw_date timestamp ) partitioned by (dt string);" ##加载数据 LOAD_FDM=" insert overwrite table fdm.itcast_fdm_user_wide partition(dt='$yesterday') select t.user_id, t.user_name, t.user_sex, t.user_birthday, (year(current_date)-(year(birthday))) as age, t.hex_phone, substring(t.hex_phone,3) as fore_phone, from_unixtime(unix_timestamp()) dw_date from bdm.itcast_bdm_user t where dt='$yesterday';" SQL_GDM="create database if not exists gdm; create table if not exists gdm.itcast_gdm_user_basic( user_id string ,--用户ID user_name string ,--用户登陆名 user_sex string ,--用户性别 user_birthday string ,--用户生日 user_age bigint ,--用户年龄 hex_phone string ,--手机号 fore_phone string ,--手机前3位 dw_date timestamp ) partitioned by (dt string);" ##加载数据到GDM LOAD_GDM="insert overwrite table gdm.itcast_gdm_user_basic partition(dt='$yesterday') select t.user_id, t.user_name, t.user_sex, t.user_birthday, t.user_age, t.hex_phone, t.fore_phone, from_unixtime(unix_timestamp()) dw_date from (select * from fdm.itcast_fdm_user_wide where dt='$yesterday') t;" ##创建BDM层表 echo "${SQL_BDM}" $SPARK_SUBMIT_INFO -e "${SQL_BDM}" ##添加数据到BDM hdfs dfs -put $SOURCE_DATA/itcast_bdm_user.txt /business/bdm/itcast_bdm_user/"dt=$yesterday" ##创建FDM层表 echo "${SQL_FDM}" $SPARK_SUBMIT_INFO -e "${SQL_FDM}" ##导入数据到FDM echo "${LOAD_FDM}" $SPARK_SUBMIT_INFO -e "${LOAD_FDM}" ##创建GDM层表 echo "${SQL_GDM}" $SPARK_SUBMIT_INFO -e "${SQL_GDM}" ##导入GDM数据 echo "${LOAD_GDM}" $SPARK_SUBMIT_INFO -e "${LOAD_GDM}"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号