
RabbitMQ之流量控制
为什么要控制流量?
举个栗子,秒杀业务,上游发起下单操作。
下游完成秒杀业务逻辑(库存检查,库存冻结,余额检查,余额冻结,订单生成,余额扣减,库存扣减,生成流水,余额解冻,库存解冻)
上游下单业务简单,每秒发起了10000个请求,下游秒杀业务复杂,每秒只能处理2000个请求,很有可能上游不限速的下单,导致下游系统被压垮,引发雪崩。
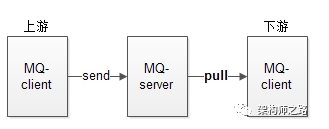
MQ-client根据自己的处理能力,每隔一定时间,或者每次拉取若干条消息,实施流控,达到保护自身的效果。并且这是MQ提供的通用功能,无需上下游修改代码。
问:如果上游发送流量过大,MQ提供拉模式确实可以起到下游自我保护的作用,会不会导致消息在MQ中堆积?
答:下游MQ-client拉取消息,消息接收方能够批量获取消息,需要下游消息接收方进行优化,方能够提升整体吞吐量,例如:批量写。
1)MQ-client提供拉模式,定时或者批量拉取,可以起到削平流量,下游自我保护的作用(MQ需要做的)
2)要想提升整体吞吐量,需要下游优化,例如批量处理等方式(消息接收方需要做的)
先不说如何下游优化,下面说说RabbitMQ如何控制流量:
一个 queue 中消息最大保存量可以在声明 queue 的时候通过设置 x-max-length 参数为非负整数进行指定。Queue 长度的选取需要考量就绪消息量、被忽略的未确认消息量,以及消息大小。当 queue 中的消息量达到了设定的上限时,为了给新消息腾出空间,将会从该 queue 用于保存消息的队列的前端将“老”消息丢弃或者 dead-lettered 。
下面的 Java 示例展示了如何声明一个最多保存 10 条消息的 queue :
Map<String, Object> args = new HashMap<String, Object>(); args.put("x-max-length", 10); channel.queueDeclare("myqueue", false, false, false, args);
Prefetch设置:
全局式设定:在application.yml文件中设定spring.rabbitmq.listener.prefetch即可, 这会影响到本Spring Boot应用中所有使用默认SimpleRabbitListenerContainerFactory的消费者
spring: rabbitmq: host: localhost username: chris password: 123123 virtual-host: prontera listener: prefetch: 100
特定消费者设置:在消费者的配置中自定义一个SimpleRabbitListenerContainerFactory
@Bean public SimpleRabbitListenerContainerFactory myContainerFactory( SimpleRabbitListenerContainerFactoryConfigurer configurer, ConnectionFactory connectionFactory) { SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory(); factory.setPrefetchCount(100); configurer.configure(factory, connectionFactory); return factory; } 然后在消费者上声明使用该ContainerFactory即可达到对特定消费者配置prefetch的作用 @RabbitListener(queues = "#{rabbitConfiguration.TOPIC_QUEUE}", containerFactory = "myContainerFactory") public void processBootTask2(WorkUnit content) { System.out.println(content); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号