Python通过Lxml库解析网络爬虫抓取到的html
Lxml是基于 libxml2解析库的Python封装。libxml2是使用C语言编写的,解析速度很好,不过安装起来稍微有点复杂。安装说明可以参考(http: //Lxml.de/installation.html),在CentOS7上中文安装说明(http://www.cjavapy.com/article/64/),使用lxml库来解析网络爬虫抓取到的HTML是一种非常高效的方式。lxml的html模块特别适合处理HTML内容,它可以快速解析大型HTML文件,并提供XPath和CSS选择器来查询和提取数据。
参考文档:
一、可能不合法的html标签解析
从网络上抓取到的html的内容,有可能都是标准写法,标签什么的都闭合,属性也是标准写法,但是有可能有的网站的程序员不专业,这样抓到的html解析就有可能有问题,因此,解析时先将有可能不合法的html解析为统一的格式。避免为后续的解析造成困扰。
1、lxml.html
lxml.html是专门用于解析和处理HTML文档的模块。它基于lxml.etree,但是为HTML文档的特点做了优化。lxml.html能够处理不良形式的HTML代码,这对于解析和爬取网页尤其有用。
>>> import lxml.html
>>> broken_html = '<ul class="body"><li>header<li>item</ul>'
>>> tree = lxml.html.fromstring(broken_html) #解析html
>>> fixed_html = lxml.html.tostring(tree,pretty_print=True)
>>> print fixed_html
<ul class="body">
<li>header</li>
<li>item</li>
</ul>
2、lxml.etree
lxml.etree是lxml库中用于处理XML文档的模块。它基于非常快的XML解析库libxml2,提供了一个类似于标准库xml.etree.ElementTreeAPI的接口,但是在性能和功能性方面要更加强大。lxml.etree支持XPath、XSLT、和Schema验证等高级XML特性。
>>> import lxml.etree
>>> broken_html = '<ul class="body"><li>header<li>item</ul>'
>>> tree = lxml.etree.fromstring(broken_html) #解析html
>>> fixed_html = lxml.etree.tostring(tree,pretty_print=True)
>>> print fixed_html
<ul class="body">
<li>header</li>
<li>item</li>
</ul>
通过以上可以看出,lxml可以正确解析两侧缺失的括号,并闭合标签,但不会额外增加<html>和<body>标签。
二、处理lxml解析出来的html内容
若在html中找到我们想要的内容,用lxml有几种不同的方法,XPath选择器类似Beautiful Soup的find()方法。CSS选择器用法和jQuery中的选择器类似。两种选择器都可以用来查找文档中的元素,但它们各有特点和适用场景。XPath是一种在XML文档中查找信息的语言。它可以用来遍历XML文档的元素和属性。CSS选择器通常用于选择和操作HTML文档中的元素。
1、XPath选择器(/单斜杠表示绝对查找,//双斜杠表示相对查找)
from lxml import etree
source_html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(source_html)
print(html)
result = etree.tostring(html)#会对的html标签进行补全
print(result.decode("utf-8"))
输出结果:
<Element html at 0x39e58f0>
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>
1)获取某个标签的内容(a标签后不需要加斜杠,否则会报错)
#第一种写法
html = etree.HTML(source_html)
html_data = html.xpath('/html/body/div/ul/li/a')#绝对查找
#html_data = html.xpath('//li/a')#相对查找
print(html)
for i in html_data:
print(i.text)
输出结果:
<Element html at 0x14fe6b8>
first item
second item
third item
fourth item
fifth item
#第二种写法
#在要找的标签后面加/text(),就是获取标签中的文本内容,结果中直接就是文本内容了,不用在通过text属性获取了。
html = etree.HTML(source_html)
html_data = html.xpath('/html/body/div/ul/li/a/text()')#绝对查找
#html_data = html.xpath('//li/a/text()')#相对查找
print(html)
for i in html_data:
print(i)
输出结果:
<Element html at 0x128e3b7>
first item
second item
third item
fourth item
fifth item
2)获取a标签下的属性
html = etree.HTML(source_html)
html_data = html.xpath('//li/a/@href') #相对查找
#html_data = html.xpath('/html/body/div/ul/li/a/@href') #绝对查找
for i in html_data:
print(i)
输出结果:
link1.html
link2.html
link3.html
link4.html
link5.html
3)查找a标签属性等于link2.html的内容
html = etree.HTML(source_html)
html_data = html.xpath('/html/body/div/ul/li/a[@href="link2.html"]/text()')绝对查找
#html_data = html.xpath('//li/a[@href="link2.html"]/text()')#相对查找
print(html_data)
for i in html_data:
print(i)
输出结果:
['second item']
second item
4)查找最后一个li标签里的a标签的href属性
html = etree.HTML(source_html)
html_data = html.xpath('//li[last()]/a/text()')
print(html_data)
for i in html_data:
print(i)
输出结果:
['fifth item']
fifth item
5)查找倒数第二个li标签里a标签的href属性
html = etree.HTML(source_html)
html_data = html.xpath('//li[last()-1]/a/text()')
print(html_data)
for i in html_data:
print(i)
输出结果:
['fourth item']
fourth item
6)查找某个标签id属性值等于value的标签
//*[@id="value"]
7)使用chrome浏览器提取某个标签的XPath
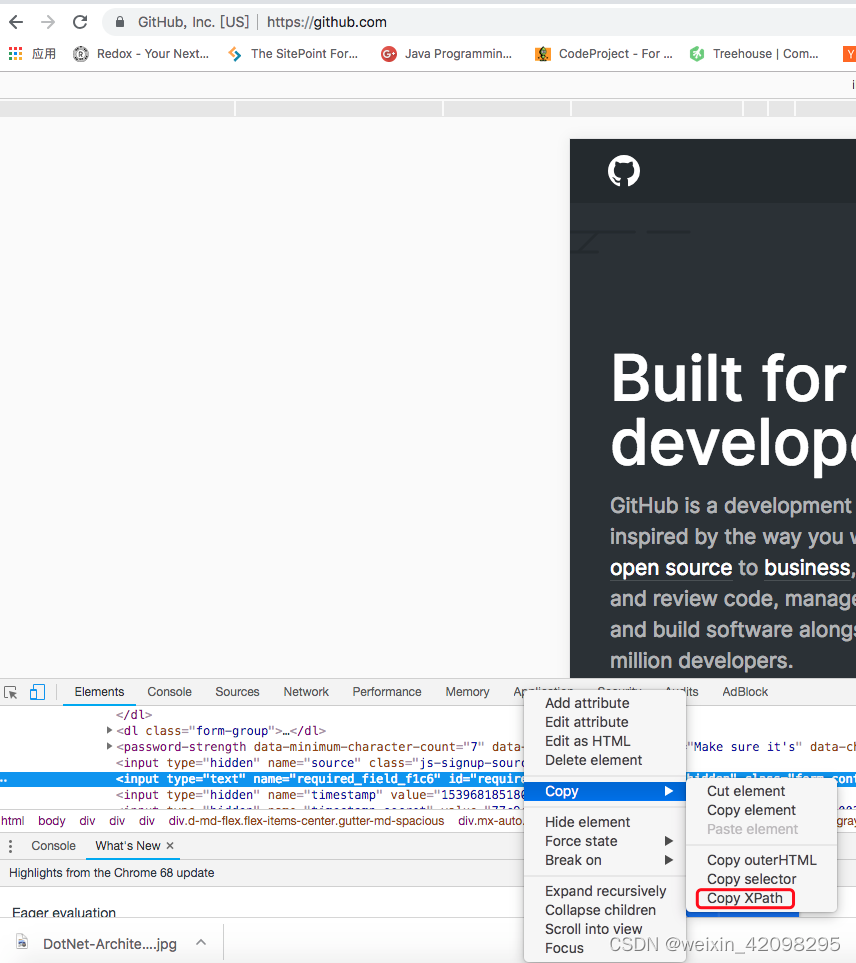
![]()
2、CSS选择器(基本上和jQuery选择器用法一样)
| 选择器 | 描述 |
|---|---|
| * | 选择所有标签 |
| a | 选择<a>标签 |
| .link | 选择所有class = 'link'的元素 |
| a.link | 选择class = 'link'的<a>标签 |
| a#home | 选择id = 'home'的<a>标签 |
| a > span | 选择父元素为<a>标签的所有<span>子标签 |
| a span | 选择<a>标签内部的所有<span>标签 |
使用示例:
>>> html = """<div>
<tr id="places_area_row" class="body">
<td>header</td>
<td class="w2p_fw">item1</td>
<td class="w2p_fw">item2</td>
<td class="w2p_fw">item3</td>
<td><tr><td class="w2p_fw">header</td>
<td class="w2p_fw">item4</td>
<td class="w2p_fw">item5</td>
<td class="w2p_fw">item6</td></tr></td>
</tr>
</div>"""
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area_row > td.w2p_fw')[0]
>>> htmlText = td.text_content()
>>> print htmlText
item1
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号