[ORACLE]oracle 表连接的几种方式
总结如下表:
| 类别 | 嵌套循环连接(NESTED LOOP) | 排序合并连接 (SORT MERGE JOIN) | 哈希连接(HASH JOIN) |
| 优化器 | USE_NL /*+ leading(表A) use_nl(表B) */ |
USE_MERGE | USE_HASH /*+ leading(表A) use_hash(表B)*/ |
| 使用条件 | 任何连接 | 主要用于不等价连接,如<、 <=、 >、 >=; 但是不包括 <> HASH_JOIN_ENABLED=false 数据源已排序 |
仅用于等价连接 |
| 特点 | 当有高选择性索引或进行限制性搜索时效率比较高, 能够快速返回第一次的搜索结果。 (对于被连接的数据子集较小的情况, 嵌套循环连接是个较好的选择,效率更高) |
当缺乏索引或者索引条件模糊时, |
当缺乏索引或者索引条件模糊时, 哈希连接连接比嵌套循环有效。 通常比排序合并连接快。 在数据仓库环境下,如果表的纪录数多,效率高。 |
| 相关资源 | CPU、磁盘I/O | 内存、临时空间 | 内存、临时空间 |
| 缺点 | 当索引丢失或者查询条件限制不够时,效率很低; 当表的纪录数多时,效率低。 |
所有的表都需要排序。它为最优化的吞吐量而设计, 并且在结果没有全部找到前不返回数据。 |
为建立哈希表,需要大量内存。第一次的结果返回较慢。 |
| 成本 |
outer access cost + |
(outer access cost * # of hash partitions) + inner access cost |
(outer access cost * # of hash partitions) + inner access cost 会耗费PGA的work_area |
| 原理 | 在嵌套循环中,内表被外表驱动, 外表返回的每一行都要在内表中检索找到与它匹配的行, 因此整个查询返回的结果集不能太大(大于1 万不适合), 要把返回子集较小表的作为外表(CBO 默认外表是驱动表), 而且在内表的连接字段上一定要有索引。 |
做大数据集连接时的常用方式,优化器使用两个表中较小的表 (或数据源)利用连接键在内存中建立散列表, 然后扫描较大的表并探测散列表,找出与散列表匹配的行 |
|
| 驱动表被驱动表 |
驱动表返回一行数据,被驱动表要被扫描一次
|
驱动表和被驱动表都被扫描1次 |
HASH JOIN:

创建INDEX后
create unique index "T1^0" on USREFUS(ID,NAME); create index "
T1
^0" on USRBF2(ID,NAME);
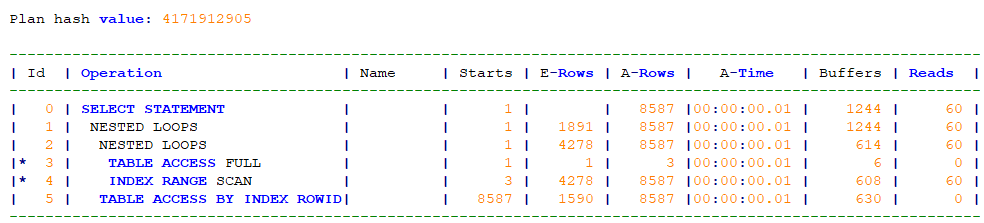
NETSTED LOOPS
每天进步一点点,多思考,多总结
版权声明:本文为CNblog博主「zaituzhong」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号