sql 查询
慢查询的原因
https://blog.csdn.net/weixin_45393094/article/details/125666997
1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)
使用explain 检测索引
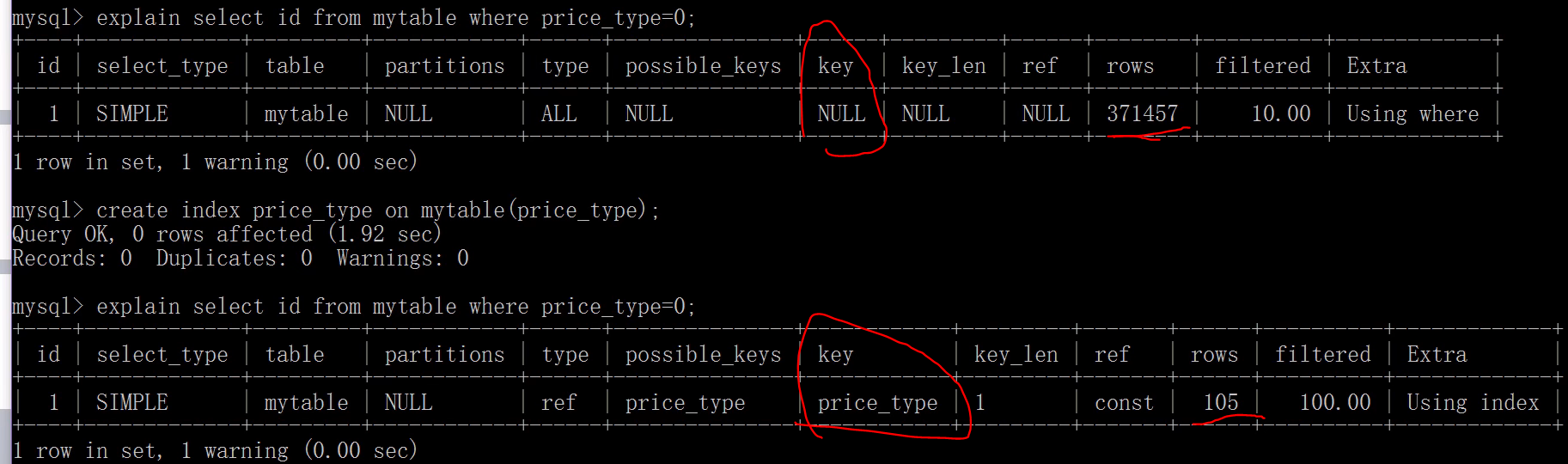
2、I/O吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足
5、网络速度慢
6、查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)
方法 : 分库分表
分库是解决数据库性能瓶颈的问题,如并发等等分表可以解决单表数据量过大,导致查询变慢的问题
7、锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)
8、sp_lock,sp_who,活动的用户查看,原因是读写竞争资源。 (SQL Server)
9、返回了不必要的行和列
10、查询语句不好,没有优化
11 热点数据
方法:Redis缓存
12 性能瓶颈问题 机器负载过高
方法: 读写分离?
其实就是将数据库分为了主从库,一个主库用于写数据,多个从库用于读数据(读的操作比较多,所以常见设置一个或多个从库),主从数据库之间的数据通过某种机制保持同步,是一种常见的数据架构
执行SQL响应比较慢,你有哪些排查思路
https://blog.csdn.net/gupaoedu_tom/article/details/125390367
1 没加索引,或者索引失效
在慢查询日志中找到耗时高的日志 ,用explain 查询是否命中索引 。尝试加索引
2 查询数据过多
分库 分表 :分库是为了解决数据库性能问题 如并发 ; 分表是为了单表查询数据大,导致慢的问题
3 网络问题或者机器负载过高
读写分离 一主多从 ,主库写 ,从库读 。同时主从同步
4 热点数据导致负载不均衡
缓存 REDIS
子查询
子查询就是在查询语句里嵌套一条或者多条查询语句。
最常用的子查询分别是带关键字IN/EXISTS/以及多种运算符的子查询。
SELECT * FROM article WHERE uid IN(SELECT uid FROM user WHERE status=0)
子查询与多表联合查询的区别
子查询:
- MySQL使用子查询进行SELECT语句嵌套查询,可以一次完成很多逻辑上需要多个步骤才能完成的SQL操作;
- 子查询虽然很灵活,但是执行效率并不高;
- 执行子查询时,主查询SQL语句中嵌套了子查询SQL语句, 这就类似于循环查询。
多表联合查询:
- 总体来说,连接查询与子查询实现的最终效果是类似的。可以使用连接查询(JOIN)代替子查询,连接查询需要建立临时表,但因为联表操作不需要查询数据,因此只需要在新表中做一次查询即可;
- 表关联是可以利用两个表的索引的,这样查询效率更高。如果是子查询,至少第二次查询是没有办法使用索引的。
总结:
多表联合查询通过建立临时表,减少查询数据的次数,同时可以利用索引提高查询效率,因此多表联合查询比子查询效率更高!!!
连接查询和子查询哪个效率高呢?
首先两者不存在谁优于谁的说法,只是那种更适应某种环境。一般要看你是什么用途,如果数据量少的话可以子查询,或者经常用的数据就使用子查询,不经常用的就连接查询,适习惯而定,当然是指数据量少的情况下。
一般来讲连接查询效率更高,因为子查询会多次遍历数据,而连接查询只遍历一次,但是如果数据量较少的话子查询更加容易控制。但如果数据量大的话两者的区别就会很明显,对于数据量多的肯定是用连接查询快些,原因:因为子查询会多次遍历所有的数据(视你的子查询的层次而定),如果你的子查询是在无限套娃,且每张表数据量不大,使用子查询效率高。
连接查询只会遍历一次,但是数据量少的话也就无所谓是连接查询还是子查询,多表数据量大建议采用连接查询。
注:连接查询是SQL查询的核心,连接查询的连接类型选择依据实际需求。如果选择不当,非但不能提高查询效率,反而会带来一些逻辑错误或者性能低下。下面总结一下两表连接查询选择方式的依据:
1、 查两表关联列相等的数据用内连接。
2、 左表是右表的子集时用右外连接。
3、 右表是左表的子集时用左外连接。
4、 左表和右表彼此有交集但彼此互不为子集时候用全外连接(全连接)。
5、 求差操作的时候用联合查询。
数据库查找不重复的值
sql语句要select 某字段值不重复 的数据,使用distinct关键字。例如从 “name” 列中仅选取所有不重复的值,使用以下SQL:
SELECT DISTINCT name FROM table;
1、distinct 【查询字段】,必须放在要查询字段的开头,即放在第一个参数;
2、只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用;
3、DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,即查出的参数拼接每行记录都是唯一的;
4、不能与all同时使用,默认情况下,查询时返回的就是所有的结果。
数据库多个进程怎么保证执行前后一致性。
方法:锁
分布式的呢?
大数据产品在解决数据安全的方式上,都比较接近,简单来说,就是让一份数据通过异步或者同步的方式保存在多台机器上,从而保障数据的安全。
分布式存储在解决数据安全的技术难点后,又引入了一个新的技术问题,就是如何保障多个副本中的数据一致性。目前SequoiaDB是使用Raft算法来保证数据在多个副本中一致性。
raft协议是一种分布式一致性协议
https://zhuanlan.zhihu.com/p/125573685
raft 协议包括2部分: leader选举和日志复制
一个节点有3种状态:
- Follower state.
- Candidate state.
- Leader state.
一开始,所有节点都是Follower状态,
leader选举:
当所有的Follower都无法感知到leader存在时,这是他们会变成一个candidate(参选者),candidate可以向其他节点发起投票,其他节点反馈投票结果,
即是同意还是驳回,如果此次投票获得了大部分节点的同意,则candidate成为了新的leader,这个过程就叫Leader Election
日志复制:
Leader选出来之后,任何改变都需要通过Leader来传达,做法是:每一次变更都会作为一个entry加入到Leader节点日志中,这时entry的状态是未提交状态(uncommitted),所以这并不会改变节点的当前值。为了能够提交entry,首先需要做的是将entry复制到所有Follower节点,然后leader开始等待直到大部分节点都写入成功了entry为止,最后leader 提交entry,节点值发生变更,并通知所有Follower entry is committed,最后所有节点都达到了一致的状态,这个过程叫做日志复制。
数据库题(各科成绩均大于85分的学生)
SELECT * FROM grade WHERE name NOT IN ( SELECT DISTINCT NAME FROM grade WHERE score <= 85)
select id form stu
group by id
having min(score)>85
sql 的执行顺序
from > join > where > group by > 聚和函数 > having > select > order by > limit
group by
CREATE TABLE Person ( PersonID int, LastName varchar(255), FirstName varchar(255), Address varchar(255), City varchar(255) ); INSERT INTO Person VALUES (1, 'Tom', 'Erichsen', 'Skagen 210, Stavanger 4006', 'Norway'); INSERT INTO Person VALUES (2, 'Tom', 'Erichsen', 'Skagen 210, Stavanger 4006', 'Norway'); INSERT INTO Person VALUES (3, 'Tl', 'Erichsen', 'Skagen 210, Stavanger 4006', 'Norway');
SELECT City, SUM(PersonID)FROM Person group by City;
Norway|6
INSERT INTO Person VALUES (1, 'Tom', 'Erichsen', 'Skagen 210, Stavanger 4006', 'Norway');
INSERT INTO Person VALUES (2, 'Tom', 'Erichsen', 'Skagen 210, Stavanger 4006', 'Norway');
INSERT INTO Person VALUES (3, 'Tl', 'Erichsen', 'Skagen 210, Stavanger 4006', 'Norway');
INSERT INTO Person VALUES (10, 'Tom', 'Erichsen', 'Skagen 210, Stavanger 4006', 'Norwy');
INSERT INTO Person VALUES (30, 'Tl', 'Erichsen', 'Skagen 210, Stavanger 4006', 'Norwy');
SELECT PersonID FROM Person group by City; 返回第一行数据
1 10
mysql分组后,取每组第一条数据或最新一条
https://blog.csdn.net/u013066244/article/details/116461584?spm=1001.2101.3001.6661.
1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-116461584-blog-92764058.t5_download_50w&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-116461584-blog-92764058.t5_download_50w&utm_relevant_index=1
思路:先进行排序,然后再进行分组,获取每组的第一条。
select * from (select distinct(a.id) tid, a.* from template_detail a
where a.template_id in (3, 4)
order by a.id desc) tt
group by tt.template_id;
Q: 为什么要写distinct(a.id)呢?
A:防止合并的构造(derived_merge);
185. 部门工资前三高的所有员工
表: Employee
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
+--------------+---------+
Id是该表的主键列。
departmentId是Department表中ID的外键。
该表的每一行都表示员工的ID、姓名和工资。它还包含了他们部门的ID。
表: Department
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
+-------------+---------+
Id是该表的主键列。
该表的每一行表示部门ID和部门名。
公司的主管们感兴趣的是公司每个部门中谁赚的钱最多。一个部门的 高收入者 是指一个员工的工资在该部门的 不同 工资中 排名前三 。
编写一个SQL查询,找出每个部门中 收入高的员工 。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:
Employee 表:
+----+-------+--------+--------------+
| id | name | salary | departmentId |
+----+-------+--------+--------------+
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
+----+-------+--------+--------------+
Department 表:
+----+-------+
| id | name |
+----+-------+
| 1 | IT |
| 2 | Sales |
+----+-------+
输出:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Joe | 85000 |
| IT | Randy | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
解释:
在IT部门:
- Max的工资最高
- 兰迪和乔都赚取第二高的独特的薪水
- 威尔的薪水是第三高的
在销售部:
- 亨利的工资最高
- 山姆的薪水第二高
- 没有第三高的工资,因为只有两名员工
# Write your MySQL query statement below 比我大的不超过3个,我就是前3名 SELECT d1.NAME AS Department, e1.NAME AS Employee, e1.Salary AS Salary FROM Employee AS e1 LEFT JOIN Department AS d1 ON e1.DepartmentId = d1.Id WHERE 3>(SELECT count(DISTINCT e2.Salary) from Employee AS e2 WHERE e1.Salary<e2.Salary AND e1.DepartmentId = e2.DepartmentId);
mysql 中order by 与group by的顺序
group by 比order by先执行,order by不会对group by 内部进行排序,如果group by后只有一条记录,那么order by 将无效
blog.csdn.net/u012861978/article/details/52168500
https://blog.csdn.net/qq_41059320/article/details/89281125
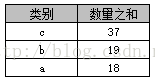
select 类别, sum(数量) AS 数量之和 from A group by 类别 order by sum(数量) desc
184. 部门工资最高的员工
表: Employee
+--------------+---------+ | 列名 | 类型 | +--------------+---------+ | id | int | | name | varchar | | salary | int | | departmentId | int | +--------------+---------+ id是此表的主键列。 departmentId是Department表中ID的外键。 此表的每一行都表示员工的ID、姓名和工资。它还包含他们所在部门的ID。
表: Department
+-------------+---------+ | 列名 | 类型 | +-------------+---------+ | id | int | | name | varchar | +-------------+---------+ id是此表的主键列。 此表的每一行都表示一个部门的ID及其名称。
编写SQL查询以查找每个部门中薪资最高的员工。
按 任意顺序 返回结果表。
查询结果格式如下例所示。
示例 1:
输入: Employee 表: +----+-------+--------+--------------+ | id | name | salary | departmentId | +----+-------+--------+--------------+ | 1 | Joe | 70000 | 1 | | 2 | Jim | 90000 | 1 | | 3 | Henry | 80000 | 2 | | 4 | Sam | 60000 | 2 | | 5 | Max | 90000 | 1 | +----+-------+--------+--------------+ Department 表: +----+-------+ | id | name | +----+-------+ | 1 | IT | | 2 | Sales | +----+-------+ 输出: +------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Jim | 90000 | | Sales | Henry | 80000 | | IT | Max | 90000 | +------------+----------+--------+ 解释:Max 和 Jim 在 IT 部门的工资都是最高的,Henry 在销售部的工资最高。
# Write your MySQL query statement below SELECT Department.name AS 'Department', Employee.name AS 'Employee', Salary FROM Employee LEFT JOIN Department ON Employee.DepartmentId = Department.Id WHERE (Employee.DepartmentId , Salary) IN ( SELECT DepartmentId, MAX(Salary) FROM Employee GROUP BY DepartmentId ) ;
COUNT
https://cloud.tencent.com/developer/article/1665491
COUNT(常量) 和 COUNT(*)表示的是直接查询符合条件的数据库表的行数。而COUNT(列名)表示的是查询符合条件的列的值不为NULL的行数。
count(*)优化
MyISAM做了一个简单的优化,那就是它可以把表的总行数单独记录下来,如果从一张表中使用COUNT(*)进行查询的时候,可以直接返回这个记录下来的数值就可以了,当然,前提是不能有where条件。
InnoDB中索引分为聚簇索引(主键索引)和非聚簇索引(非主键索引),聚簇索引的叶子节点中保存的是整行记录,而非聚簇索引的叶子节点中保存的是该行记录的主键的值。
所以,相比之下,非聚簇索引要比聚簇索引小很多,所以MySQL会优先选择最小的非聚簇索引来扫表。所以,当我们建表的时候,除了主键索引以外,创建一个非主键索引还是有必要的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号